Beitragen#
Dieses Projekt ist eine Gemeinschaftsleistung, die von einer großen Anzahl von Mitwirkenden aus aller Welt gestaltet wird. Weitere Informationen zur Geschichte und den Personen hinter scikit-learn finden Sie unter Über uns. Es wird auf scikit-learn/scikit-learn gehostet. Der Entscheidungsprozess und die Governance-Struktur von scikit-learn sind in Scikit-learn Governance und Entscheidungsfindung dargelegt.
Scikit-learn ist selektiv, wenn es um das Hinzufügen neuer Algorithmen und Funktionen geht. Das bedeutet, der beste Weg, zum Projekt beizutragen und ihm zu helfen, ist, mit bekannten Problemen zu beginnen. Unter Wege zum Beitragen erfahren Sie, wie Sie aussagekräftige Beiträge leisten können.
Wege zum Beitragen#
Es gibt viele Möglichkeiten, zu scikit-learn beizutragen. Dazu gehören
Scikit-learn in Ihrem Blog und in Artikeln zu erwähnen, es von Ihrer Website aus zu verlinken oder es einfach mit einem Sternchen zu versehen, um zu sagen „Ich benutze es“; dies hilft uns, das Projekt zu bewerben
Schwierigkeiten bei der Nutzung dieses Pakets durch Einreichen eines Issues zu melden und bei von anderen gemeldeten Issues, die für Sie relevant sind, einen "Daumen hoch" zu geben (siehe Einreichen einer Fehler- oder Funktionsanfrage für Details)
Verbesserung der Dokumentation
Leisten eines Code-Beitrags
Es gibt viele Möglichkeiten, ohne Code beizutragen, und wir schätzen diese Beiträge genauso hoch wie Code-Beiträge. Wenn Sie daran interessiert sind, einen Code-Beitrag zu leisten, beachten Sie bitte, dass scikit-learn seit seiner Gründung im Jahr 2007 zu einem ausgereiften und komplexen Projekt herangewachsen ist. Beiträge zum Projektcode erfordern im Allgemeinen fortgeschrittene Fähigkeiten und sind möglicherweise nicht der beste Ort, um zu beginnen, wenn Sie neu im Open-Source-Beitragsmodell sind. In diesem Fall empfehlen wir, die Vorschläge unter Neue Mitwirkende zu befolgen.
Neue Mitwirkende#
Wir empfehlen neuen Mitwirkenden, zunächst diesen Leitfaden zum Beitragen zu lesen, insbesondere Wege zum Beitragen und Richtlinien für automatisierte Beiträge.
Als nächstes empfehlen wir neuen Mitwirkenden, grundlegende Kenntnisse über scikit-learn und Open Source zu erwerben, indem sie
Verbesserung und Untersuchung von Issues
bestätigen, dass ein gemeldetes Problem reproduziert werden kann, und ein minimal reproduzierbares Codebeispiel (falls fehlend) bereitstellen, kann Ihnen helfen, verschiedene Anwendungsfälle und Benutzerbedürfnisse zu lernen
die Ursache eines Problems untersuchen, um sich mit der scikit-learn-Codebasis vertraut zu machen
Überprüfen der Pull-Requests anderer Entwickler hilft Ihnen, ein Verständnis für die Anforderungen und die Qualität zu entwickeln, die von Beiträgen erwartet werden
Verbesserung der Dokumentation kann helfen, Ihr Wissen über die statistischen Konzepte hinter den Modellen und Funktionen sowie die scikit-learn API zu vertiefen
Wenn Sie Code-Beiträge leisten möchten, nachdem Sie Ihre grundlegenden Kenntnisse aufgebaut haben, empfehlen wir Ihnen, zunächst nach einem Issue zu suchen, das Sie interessiert und das in einem Bereich liegt, mit dem Sie als Benutzer bereits vertraut sind oder über den Sie Hintergrundwissen verfügen. Wir empfehlen, mit kleineren Pull-Requests zu beginnen und unsere Checkliste für Pull-Requests zu befolgen. Bezüglich der erwarteten Etikette, welche Issues und gestoppten PRs bearbeitet werden sollen, lesen Sie bitte Gestoppte Pull-Requests, Gestoppte und nicht beanspruchte Issues und Issues mit dem Tag „Needs Triage“.
Wir verwenden das Label „good first issue“ selten, da es schwierig ist, Annahmen über neue Mitwirkende zu treffen und diese Issues oft komplexer sind als ursprünglich erwartet. Es ist dennoch nützlich zu prüfen, ob es „good first issues“ gibt, obwohl diese je nach Ihrer Vorerfahrung immer noch zeitaufwendig zu lösen sein können.
Für erfahrenere scikit-learn-Mitwirkende können Issues mit dem Label „Easy“ ein guter Anlaufpunkt sein.
Richtlinien für automatisierte Beiträge#
Das Beitragen zu scikit-learn erfordert menschliches Urteilsvermögen, kontextuelles Verständnis und Vertrautheit mit der Struktur und den Zielen von scikit-learn. Es ist nicht für die automatische Verarbeitung durch KI-Tools geeignet.
Bitte sehen Sie davon ab, Issues oder Pull-Requests einzureichen, die von vollautomatischen Tools generiert wurden. Die Maintainer behalten sich das Recht vor, nach eigenem Ermessen solche Einreichungen zu schließen und Konten, die dafür verantwortlich sind, zu sperren.
Überprüfen Sie alle von KI-Tools vorgenommenen Code- oder Dokumentationsänderungen und stellen Sie sicher, dass Sie alle Änderungen verstehen und bei Bedarf erläutern können, bevor Sie sie unter Ihrem Namen einreichen. Reichen Sie keinen KI-generierten Code ein, den Sie nicht persönlich überprüft, verstanden und getestet haben, da dies die Zeit der Maintainer verschwendet.
Bitte fügen Sie keine KI-generierten Texte in die Beschreibung von Issues, PRs oder in Kommentare ein, da dies es den Gutachtern erschwert, Ihren Beitrag zu bewerten. Wir freuen uns jedoch, wenn sie zur Verbesserung der Grammatik oder für nicht-muttersprachliche Englischsprecher verwendet werden.
Wenn Sie KI-Tools verwendet haben, geben Sie dies bitte in Ihrer PR-Beschreibung an.
PRs, die gegen diese Richtlinien zu verstoßen scheinen, werden ohne Überprüfung geschlossen.
Einreichen einer Fehler- oder Funktionsanfrage#
Wir verwenden GitHub Issues, um alle Fehler und Funktionsanfragen zu verfolgen. Zögern Sie nicht, ein Issue zu öffnen, wenn Sie einen Fehler gefunden haben oder eine Funktion implementiert sehen möchten.
Falls Sie Probleme bei der Nutzung dieses Pakets haben, zögern Sie nicht, ein Ticket im Bug Tracker einzureichen. Sie sind ebenfalls willkommen, Funktionsanfragen oder Pull-Requests zu posten.
Es wird empfohlen, vor dem Einreichen zu überprüfen, ob Ihr Issue den folgenden Regeln entspricht
Überprüfen Sie, ob Ihr Issue nicht bereits von anderen Issues oder Pull-Requests bearbeitet wird.
Wenn Sie einen Algorithmus oder eine Funktionsanfrage einreichen, überprüfen Sie bitte, ob der Algorithmus unsere Anforderungen für neue Algorithmen erfüllt.
Wenn Sie eine Fehlermeldung einreichen, empfehlen wir Ihnen dringend, die Richtlinien unter Wie man eine gute Fehlerbeschreibung erstellt zu befolgen.
Wenn eine Funktionsanfrage Änderungen an den API-Prinzipien oder Änderungen an Abhängigkeiten oder unterstützten Versionen beinhaltet, muss sie durch ein SLEP unterstützt werden, das als Pull-Request an die Enhancement Proposals unter Verwendung der SLEP-Vorlage eingereicht wird und dem in Scikit-learn Governance und Entscheidungsfindung dargelegten Entscheidungsprozess folgt.
Wie man eine gute Fehlerbeschreibung erstellt#
Wenn Sie ein Issue bei GitHub einreichen, tun Sie bitte Ihr Bestes, um diese Richtlinien zu befolgen! Dies erleichtert es uns, Ihnen gutes Feedback zu geben
Der ideale Fehlerbericht enthält ein kurzes reproduzierbares Code-Snippet, damit jeder den Fehler leicht reproduzieren kann. Wenn Ihr Snippet länger als etwa 50 Zeilen ist, verlinken Sie bitte zu einem Gist oder einem GitHub-Repository.
Wenn es nicht möglich ist, ein reproduzierbares Snippet einzufügen, geben Sie bitte genau an, welche **Estimators und/oder Funktionen beteiligt sind und wie die Daten geformt sind**.
Wenn eine Ausnahme ausgelöst wird, geben Sie bitte **den vollständigen Traceback** an.
Bitte geben Sie Ihren **Betriebssystemtyp und die Versionsnummer** sowie Ihre **Python-, scikit-learn-, numpy- und scipy-Versionen** an. Diese Informationen finden Sie durch Ausführen von
python -c "import sklearn; sklearn.show_versions()"Bitte stellen Sie sicher, dass alle **Code-Snippets und Fehlermeldungen in geeigneten Codeblöcken formatiert** sind. Weitere Details finden Sie unter Erstellen und Hervorheben von Codeblöcken.
Wenn Sie bei der Kuratierung von Issues helfen möchten, lesen Sie bitte über Bug-Triage und Issue-Kuration.
Code und Dokumentation beitragen#
Der bevorzugte Weg, zu scikit-learn beizutragen, ist das Forken des Haupt-Repositorys auf GitHub und anschließendes Einreichen eines „Pull-Requests“ (PR).
Um zu beginnen, müssen Sie
Finden Sie ein Issue zum Bearbeiten (siehe Neue Mitwirkende)
Befolgen Sie den Entwicklungs-Workflow
Stellen Sie sicher, dass Sie die Checkliste für Pull-Requests beachtet haben.
Wenn Sie Dokumentation beitragen möchten, stellen Sie sicher, dass Sie sie lokal erstellen können, bevor Sie einen PR einreichen.
Hinweis
Um doppelte Arbeit zu vermeiden, wird dringend empfohlen, den Issue-Tracker und die PR-Liste zu durchsuchen. Wenn Sie sich über doppelte Arbeit unsicher sind oder an einem nicht-trivialen Feature arbeiten möchten, wird empfohlen, zuerst ein Issue im Issue-Tracker zu öffnen, um Feedback von den Kernentwicklern zu erhalten.
Eine einfache Möglichkeit, ein zu bearbeitendes Issue zu finden, ist die Anwendung des Labels „help wanted“ in Ihrer Suche. Dies listet alle Issues auf, die bisher nicht beansprucht wurden. Wenn Sie an einem solchen Issue arbeiten möchten, hinterlassen Sie einen Kommentar mit Ihrer Idee, wie Sie es angehen wollen, und beginnen Sie damit. Wenn jemand anderes bereits vor 2-3 Wochen gesagt hat, dass er an dem Issue arbeitet, lassen Sie ihn bitte seine Arbeit beenden, andernfalls betrachten Sie es als gestoppt und übernehmen Sie es.
Um die Qualität der Codebasis zu erhalten und den Überprüfungsprozess zu erleichtern, muss jeder Beitrag den Codierungsrichtlinien des Projekts entsprechen, insbesondere
Ändern Sie keine nicht verwandten Zeilen, um den PR auf den in seiner Beschreibung oder im Issue angegebenen Umfang zu beschränken.
Schreiben Sie nur Inline-Kommentare, die einen Mehrwert bieten, und vermeiden Sie es, Offensichtliches zu sagen: Erklären Sie das „Warum“ anstelle des „Was“.
Am wichtigsten: Tragen Sie keinen Code bei, den Sie nicht verstehen.
Entwicklungs-Workflow#
Die folgenden Schritte beschreiben den Prozess der Codeänderung und des Einreichens eines PR
Synchronisieren Sie Ihren
main-Branch mit demupstream/main-Branch. Weitere Details finden Sie auf den GitHub Docs.git checkout main git fetch upstream git merge upstream/main
Erstellen Sie einen Feature-Branch, um Ihre Entwicklungsänderungen zu speichern
git checkout -b my_featureund beginnen Sie mit den Änderungen. Verwenden Sie immer einen Feature-Branch. Es ist eine gute Praxis, niemals am
main-Branch zu arbeiten!Entwickeln Sie das Feature auf Ihrem Feature-Branch auf Ihrem Computer und verwenden Sie Git zur Versionskontrolle. Wenn Sie mit der Bearbeitung fertig sind, fügen Sie geänderte Dateien mit
git addund danngit commithinzu.git add modified_files git commit
Hinweis
pre-commit kann Ihren Code beim
git commitautomatisch neu formatieren. Wenn dies geschieht, müssen Siegit addgefolgt vongit commiterneut ausführen. In selteneren Fällen müssen Sie möglicherweise Dinge manuell beheben, verwenden Sie die Fehlermeldung, um herauszufinden, was geändert werden muss, und verwenden Siegit addgefolgt vongit commit, bis der Commit erfolgreich ist.Pushen Sie dann die Änderungen mit folgendem Befehl auf Ihren GitHub-Account:
git push -u origin my_featureBefolgen Sie diese Anweisungen, um einen Pull-Request aus Ihrem Fork zu erstellen. Dies benachrichtigt potenzielle Gutachter. Möglicherweise möchten Sie erwägen, eine Nachricht an den Discord im Entwicklungs-Channel zu senden, um mehr Sichtbarkeit zu erhalten, wenn Ihr Pull-Request nach ein paar Tagen keine Aufmerksamkeit erhält (sofortige Antworten sind jedoch nicht garantiert).
Es ist oft hilfreich, Ihren lokalen Feature-Branch mit den neuesten Änderungen des Haupt-scikit-learn-Repositorys synchron zu halten.
git fetch upstream
git merge upstream/main
Anschließend müssen Sie möglicherweise die Konflikte lösen. Sie können auf die Git-Dokumentation zum Lösen von Merge-Konflikten über die Kommandozeile verweisen.
Checkliste für Pull-Requests#
Bevor ein PR zusammengeführt werden kann, muss er von zwei Kernentwicklern genehmigt werden. Ein unvollständiger Beitrag – bei dem Sie erwarten, weitere Arbeiten zu leisten, bevor Sie eine vollständige Überprüfung erhalten – sollte als Entwurfs-Pull-Request markiert und zu „bereit zur Überprüfung“ geändert werden, wenn er reifer ist. Entwurfs-PRs können nützlich sein, um: anzuzeigen, dass Sie an etwas arbeiten, um doppelte Arbeit zu vermeiden, eine breite Überprüfung von Funktionalität oder API zu erbitten oder Mitwirkende zu suchen. Entwurfs-PRs profitieren oft von der Aufnahme einer Aufgabenliste in der PR-Beschreibung.
Um den Überprüfungsprozess zu erleichtern, empfehlen wir, dass Ihr Beitrag den folgenden Regeln entspricht, bevor Sie einen PR als „bereit zur Überprüfung“ markieren. Die **fett gedruckten** sind besonders wichtig
Geben Sie Ihrem Pull-Request einen aussagekräftigen Titel, der zusammenfasst, was Ihr Beitrag leistet. Dieser Titel wird nach dem Zusammenführen oft zur Commit-Nachricht, daher sollte er Ihren Beitrag für die Nachwelt zusammenfassen. In einigen Fällen reicht „Fix <ISSUE TITLE>“ aus. „Fix #<ISSUE NUMBER>“ ist nie ein guter Titel.
Stellen Sie sicher, dass Ihr Code die Tests besteht. Die gesamte Testsuite kann mit
pytestausgeführt werden, dies wird jedoch normalerweise nicht empfohlen, da es lange dauert. Oft reicht es aus, nur die Tests auszuführen, die Ihre Änderungen betreffen: Wenn Sie beispielsweise etwas insklearn/linear_model/_logistic.pygeändert haben, sind die folgenden Befehle normalerweise ausreichendpytest sklearn/linear_model/_logistic.py, um sicherzustellen, dass die Doctest-Beispiele korrekt sind.pytest sklearn/linear_model/tests/test_logistic.py, um die spezifischen Tests für die Datei auszuführen.pytest sklearn/linear_model, um das gesamtelinear_model-Modul zu testen.pytest doc/modules/linear_model.rst, um sicherzustellen, dass die Beispiele im Benutzerhandbuch korrekt sind.pytest sklearn/tests/test_common.py -k LogisticRegression, um alle unsere Estimator-Checks auszuführen (speziell fürLogisticRegression, falls dies der von Ihnen geänderte Estimator ist).
Es können andere Tests fehlschlagen, aber diese werden von der CI erfasst, sodass Sie die gesamte Testsuite nicht lokal ausführen müssen. Anleitungen zur effizienten Nutzung von
pytestfinden Sie in den Nützlichen Pytest-Aliase und Flags.Stellen Sie sicher, dass Ihr Code ordnungsgemäß kommentiert und dokumentiert ist und stellen Sie sicher, dass die Dokumentation korrekt gerendert wird. Informationen zur Erstellung der Dokumentation finden Sie in unseren Richtlinien für die Dokumentation. Die CI wird auch die Dokumentation erstellen: siehe Generierte Dokumentation auf GitHub Actions.
Tests sind für die Annahme von Verbesserungen unerlässlich. Fehlerbehebungen oder neue Features sollten mit Nicht-Regressionstests versehen werden. Diese Tests überprüfen das korrekte Verhalten der Korrektur oder des Features. Auf diese Weise wird garantiert, dass weitere Änderungen an der Codebasis mit dem gewünschten Verhalten konsistent sind. Bei Fehlerbehebungen sollten die Nicht-Regressionstests zum Zeitpunkt des PR für den Code in der
main-Branch fehlschlagen und für den PR-Code erfolgreich sein.Wenn Ihr PR voraussichtlich Auswirkungen auf Benutzer hat, müssen Sie einen Changelog-Eintrag hinzufügen, der Ihre PR-Änderungen beschreibt. Weitere Details finden Sie in der README.
Befolgen Sie die Codierungsrichtlinien.
Verwenden Sie gegebenenfalls die Validierungstools und Skripte im Modul
sklearn.utils. Eine Liste der für Entwickler verfügbaren Hilfsprogramme finden Sie auf der Seite Dienstprogramme für Entwickler.Häufig lösen Pull-Requests ein oder mehrere andere Issues (oder Pull-Requests) auf. Wenn das Zusammenführen Ihres Pull-Requests bedeutet, dass andere Issues/PRs geschlossen werden sollten, sollten Sie Schlüsselwörter verwenden, um Links zu ihnen zu erstellen (z. B.
Fixes #1234; mehrere Issues/PRs sind erlaubt, solange jedem ein Schlüsselwort vorangestellt ist). Nach dem Zusammenführen werden diese Issues/PRs automatisch von GitHub geschlossen. Wenn Ihr Pull-Request nur mit anderen Issues/PRs zusammenhängt oder das Ziel-Issue nur teilweise löst, erstellen Sie einen Link zu ihnen, ohne die Schlüsselwörter zu verwenden (z. B.Towards #1234).PRs sollten oft die Änderung untermauern, durch Leistung- und Effizienzbenchmarks (siehe Leistungsüberwachung) oder durch Anwendungsbeispiele. Beispiele veranschaulichen auch die Funktionen und Besonderheiten der Bibliothek für die Benutzer. Schauen Sie sich andere Beispiele im Verzeichnis examples/ als Referenz an. Beispiele sollten verdeutlichen, warum die neue Funktionalität in der Praxis nützlich ist, und, wenn möglich, sie mit anderen in scikit-learn verfügbaren Methoden vergleichen.
Neue Features verursachen einen gewissen Wartungsaufwand. Wir erwarten, dass die PR-Autoren an der Wartung des von ihnen eingereichten Codes teilnehmen, zumindest zunächst. Neue Features müssen mit erläuternden Dokumenten im Benutzerhandbuch und kleinen Code-Schnipseln illustriert werden. Falls relevant, fügen Sie bitte auch Referenzen in der Literatur hinzu, mit PDF-Links, wenn möglich.
Das Benutzerhandbuch sollte auch die erwartete Zeit- und Platzkomplexität des Algorithmus und die Skalierbarkeit enthalten, z. B. „dieser Algorithmus skaliert auf eine große Anzahl von Stichproben > 100000, skaliert aber nicht in der Dimensionalität:
n_featureswird voraussichtlich kleiner als 100 sein“.
Sie können auch unsere Richtlinien für Code-Reviews überprüfen, um eine Vorstellung davon zu bekommen, was die Gutachter erwarten.
Sie können auf häufige Programmierfehler mit folgenden Werkzeugen prüfen
Code mit guter Unit-Test-Abdeckung (mindestens 80%, besser 100%), prüfen mit
pip install pytest pytest-cov pytest --cov sklearn path/to/tests
Siehe auch Testen und Verbessern der Testabdeckung.
Führen Sie eine statische Analyse mit
mypyaus.mypy sklearnDies darf keine neuen Fehler in Ihrem Pull-Request verursachen. Die Verwendung der
# type: ignore-Annotation kann eine Lösung für einige Fälle sein, die von mypy nicht unterstützt werden, insbesonderebeim Import von C- oder Cython-Modulen,
bei Eigenschaften mit Dekoratoren.
Bonuspunkte gibt es für Beiträge, die eine Leistungsanalyse mit einem Benchmark-Skript und Profiling-Ausgabe enthalten (siehe Leistungsüberwachung). Schauen Sie sich auch den Leitfaden Wie man auf Geschwindigkeit optimiert für weitere Details zum Profiling und zu Cython-Optimierungen an.
Hinweis
Der aktuelle Stand der scikit-learn-Codebasis entspricht nicht allen diesen Richtlinien, aber wir erwarten, dass die Durchsetzung dieser Beschränkungen für alle neuen Beiträge die Gesamtqualität der Codebasis in die richtige Richtung bringen wird.
Siehe auch
Für zwei sehr gut dokumentierte und detailliertere Anleitungen zum Entwicklungs-Workflow besuchen Sie bitte den Abschnitt Scipy Development Workflow und den Abschnitt Astropy Workflow for Developers.
Continuous Integration (CI)#
Azure Pipelines werden zum Testen von scikit-learn unter Linux, Mac und Windows mit verschiedenen Abhängigkeiten und Einstellungen verwendet.
CircleCI wird zum Erstellen der Dokumente zur Anzeige verwendet.
GitHub Actions werden für verschiedene Aufgaben verwendet, einschließlich des Erstellens von Wheels und Quellcode-Distributionen.
Commit-Nachrichten-Marker#
Bitte beachten Sie, dass, wenn einer der folgenden Marker in der neuesten Commit-Nachricht erscheint, die folgenden Aktionen ausgeführt werden.
Commit-Nachrichten-Marker |
Aktion durch CI |
|---|---|
[ci skip] |
CI wird vollständig übersprungen |
[cd build] |
CD wird ausgeführt (Wheels und Quellcode-Distribution werden erstellt) |
[lint skip] |
Azure-Pipeline überspringt Linting |
[scipy-dev] |
Build & test mit unseren Abhängigkeiten (numpy, scipy, etc.) Entwicklungsversionen |
[free-threaded] |
Build & test mit CPython 3.14 free-threaded |
[pyodide] |
Build & test mit Pyodide |
[azure parallel] |
Azure CI-Jobs parallel ausführen |
[float32] |
Führen Sie Float32-Tests aus, indem Sie |
[all random seeds] |
Führen Sie Tests mit dem |
[doc skip] |
Dokumentation wird nicht erstellt |
[doc quick] |
Dokumentation erstellt, schließt jedoch Beispielgalerie-Plots aus |
[doc build] |
Dokumentation erstellt, einschließlich Beispielgalerie-Plots (sehr lange) |
Beachten Sie, dass standardmäßig die Dokumentation erstellt wird, aber nur die Beispiele, die direkt von dem Pull-Request geändert werden, ausgeführt werden.
Konflikte in Lock-Dateien lösen#
Hier ist ein Bash-Snippet, das bei der Lösung von Konflikten in Umgebungs- und Lock-Dateien hilft
# pull latest upstream/main
git pull upstream main --no-rebase
# resolve conflicts - keeping the upstream/main version for specific files
git checkout --theirs build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git add build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git merge --continue
Dies wird upstream/main in unseren Branch mergen und dabei automatisch upstream/main für konfliktbehaftete Umgebungs- und Lock-Dateien priorisieren (das ist gut genug, da wir die Lock-Dateien anschließend neu generieren).
Beachten Sie, dass dies nur Konflikte in Umgebungs- und Lock-Dateien behebt und Sie möglicherweise andere Konflikte lösen müssen.
Schließlich müssen wir die Umgebungs- und Lock-Dateien für die CIs neu generieren, indem wir Folgendes ausführen:
python build_tools/update_environments_and_lock_files.py
Gestoppte Pull-Requests#
Da die Entwicklung eines Features ein langwieriger Prozess sein kann, erscheinen einige Pull-Requests inaktiv, aber unvollständig. In einem solchen Fall ist die Übernahme eine große Hilfe für das Projekt. Eine gute Etikette zur Übernahme ist:
Feststellen, ob ein PR gestoppt ist
Ein Pull-Request kann das Label „stalled“ oder „help wanted“ tragen, wenn wir ihn bereits als Kandidaten für andere Mitwirkende identifiziert haben.
Um zu entscheiden, ob ein inaktiver PR gestoppt ist, fragen Sie den Mitwirkenden, ob er/sie plant, den PR in naher Zukunft weiterzuarbeiten. Wenn Sie nicht innerhalb von 2 Wochen mit einer Aktivität antworten, die den PR voranbringt, deutet dies darauf hin, dass der PR gestoppt ist und führt dazu, dass der PR mit „help wanted“ getaggt wird.
Beachten Sie, dass, wenn ein PR bereits frühere Kommentare zur Beteiligung erhalten hat, auf die seit einem Monat keine Antwort erfolgt ist, davon auszugehen ist, dass der PR gestoppt ist und die Wartezeit auf einen Tag verkürzt werden kann.
Nach einem Sprint werden die Teilnehmer des Sprints über nicht zusammengeführte PRs, die während des Sprints geöffnet wurden, informiert, und diese PRs werden mit „sprint“ getaggt. PRs, die mit „sprint“ getaggt sind, können von Sprintleitern neu zugewiesen oder als gestoppt erklärt werden.
Übernahme eines gestoppten PRs: Um einen PR zu übernehmen, ist es wichtig, auf dem gestoppten PR zu kommentieren, dass Sie ihn übernehmen, und vom neuen PR zum alten zu verlinken. Der neue PR sollte erstellt werden, indem von dem alten gezogen wird.
Gestoppte und nicht beanspruchte Issues#
Im Allgemeinen haben Issues, die zur Verfügung stehen, einen „help wanted“-Tag. Allerdings haben nicht alle Issues, die Mitwirkende benötigen, diesen Tag, da der „help wanted“-Tag nicht immer aktuell ist. Mitwirkende können Issues finden, die noch verfügbar sind, anhand der folgenden Richtlinien:
Zunächst, um zu **festzustellen, ob ein Issue beansprucht ist**
Prüfen Sie auf verlinkte Pull-Requests
Prüfen Sie die Konversation, um zu sehen, ob jemand gesagt hat, dass er an der Erstellung eines Pull-Requests arbeitet
Wenn ein Mitwirkender zu einem Issue kommentiert, dass er daran arbeitet, wird ein Pull-Request innerhalb von 2 Wochen (neuer Mitwirkender) oder 4 Wochen (Mitwirkender oder Kernentwickler) erwartet, es sei denn, ein längerer Zeitrahmen wird ausdrücklich genannt. Über diese Frist hinaus kann ein anderer Mitwirkender das Issue übernehmen und einen Pull-Request dafür erstellen. Wir ermutigen Mitwirkende, direkt zu dem gestoppten oder nicht beanspruchten Issue zu kommentieren, um Community-Mitglieder wissen zu lassen, dass sie daran arbeiten werden.
Wenn das Issue mit einem gestoppten Pull-Request verknüpft ist, empfehlen wir, dass Mitwirkende das Verfahren im Abschnitt Gestoppte Pull-Requests befolgen, anstatt direkt am Issue zu arbeiten.
Issues mit dem Tag „Needs Triage“#
Das Label „Needs Triage“ bedeutet, dass das Issue noch nicht bestätigt oder vollständig verstanden wurde. Es signalisiert den scikit-learn-Mitgliedern, das Problem zu klären, den Umfang zu besprechen und die nächsten Schritte zu entscheiden. Sie sind herzlich eingeladen, sich an der Diskussion zu beteiligen, aber gemäß unserem Verhaltenskodex eröffnen Sie bitte keinen PR, bevor das Label „Needs Triage“ entfernt wurde, es ein klarer Konsens zur Behebung des Issues besteht und es einige Richtungen zur Behebung gibt.
Videoressourcen#
Diese Videos sind Schritt-für-Schritt-Einführungen, wie man zu scikit-learn beiträgt, und eine großartige Ergänzung zu den Textleitfäden. Bitte stellen Sie sicher, dass Sie sich trotzdem unsere Leitfäden ansehen, da diese unseren neuesten, aktuellsten Workflow beschreiben.
Crashkurs: Beitrag zu Scikit-Learn & Open Source Projekten: Video, Transkript
Beispiel für das Einreichen eines Pull Requests an Scikit-Learn: Video, Transkript
Sprint-spezifische Anweisungen und praktische Tipps: Video, Transkript
3 Komponenten des Reviews eines Pull Requests: Video, Transkript
Hinweis
Im Januar 2021 wurde der Standard-Branch-Name von master zu main für das Scikit-Learn GitHub-Repository geändert, um inklusivere Begriffe zu verwenden. Diese Videos wurden vor der Umbenennung des Branches erstellt. Für Mitwirkende, die diese Videos zum Einrichten ihrer Arbeitsumgebung und zum Einreichen eines PRs ansehen, sollte master durch main ersetzt werden.
Dokumentation#
Wir freuen uns über durchdachte Beiträge zur Dokumentation und prüfen gerne Ergänzungen in den folgenden Bereichen
Docstrings für Funktionen/Methoden/Klassen: Auch als „API-Dokumentation“ bekannt, beschreiben diese, was das Objekt tut und detaillieren alle Parameter, Attribute und Methoden. Docstrings leben neben dem Code in sklearn/ und werden gemäß doc/api_reference.py generiert. Um eine öffentliche API, die in der API-Referenz aufgeführt ist, hinzuzufügen, zu aktualisieren, zu entfernen oder zu verwerfen, ist dies der richtige Ort.
Benutzerhandbuch: Diese bieten detailliertere Informationen über die in Scikit-Learn implementierten Algorithmen und befinden sich im Allgemeinen im Stammverzeichnis doc/ und doc/modules/.
Beispiele: Diese bieten vollständige Codebeispiele, die die Verwendung von Scikit-Learn-Modulen demonstrieren, verschiedene Algorithmen vergleichen oder deren Interpretation diskutieren können usw. Beispiele befinden sich in examples/.
Andere reStructuredText-Dokumente: Diese bieten verschiedene andere nützliche Informationen (z. B. den Beitragen zu Pandas-Leitfaden) und befinden sich in doc/.
Richtlinien für das Schreiben von Docstrings#
Sie können
pytestverwenden, um Docstrings zu testen. Angenommen, der Docstring vonRandomForestClassifierwurde geändert, würde der folgende Befehl seine Konformität mit den Docstring-Richtlinien testen.pytest --doctest-modules sklearn/ensemble/_forest.py -k RandomForestClassifierDie richtige Reihenfolge der Abschnitte ist: Parameter, Returns, See Also, Notes, Examples. Informationen zu weiteren möglichen Abschnitten finden Sie in der Numpydoc-Dokumentation.
Hier ist eine Liste einiger gut formatierter Beispiele für die Dokumentation von Parametern und Attributen:
n_clusters : int, default=3 The number of clusters detected by the algorithm. some_param : {"hello", "goodbye"}, bool or int, default=True The parameter description goes here, which can be either a string literal (either `hello` or `goodbye`), a bool, or an int. The default value is True. array_parameter : {array-like, sparse matrix} of shape (n_samples, n_features) \ or (n_samples,) This parameter accepts data in either of the mentioned forms, with one of the mentioned shapes. The default value is `np.ones(shape=(n_samples,))`. list_param : list of int typed_ndarray : ndarray of shape (n_samples,), dtype=np.int32 sample_weight : array-like of shape (n_samples,), default=None multioutput_array : ndarray of shape (n_samples, n_classes) or list of such arraysBeachten Sie im Allgemeinen Folgendes:
Verwenden Sie Python-Basistypen. (
boolanstelle vonboolean)Verwenden Sie Klammern zur Angabe von Formen:
array-like of shape (n_samples,)oderarray-like of shape (n_samples, n_features)Verwenden Sie für Zeichenketten mit mehreren Optionen eckige Klammern:
input: {'log', 'squared', 'multinomial'}1D- oder 2D-Daten können eine Teilmenge von
{array-like, ndarray, sparse matrix, dataframe}sein. Beachten Sie, dassarray-likeauch einelistsein kann, währendndarrayausdrücklich nur einnumpy.ndarrayist.Geben Sie
dataframean, wenn „rahmenähnliche“ Merkmale verwendet werden, z. B. die Spaltennamen.Bei der Angabe des Datentyps einer Liste verwenden Sie
ofals Trennzeichen:list of int. Wenn der Parameter Arrays mit Details zur Form und/oder zum Datentyp sowie eine Liste solcher Arrays unterstützt, können Sie eine der folgenden Optionen verwenden:array-like of shape (n_samples,) or list of such arrays.Bei der Angabe des dtypes eines ndarray verwenden Sie z. B.
dtype=np.int32nach der Angabe der Form:ndarray of shape (n_samples,), dtype=np.int32. Sie können mehrere dtypes als Set angeben:array-like of shape (n_samples,), dtype={np.float64, np.float32}. Wenn eine beliebige Präzision erwähnt werden soll, verwenden Sieintegralundfloatinganstelle der Python-Datentypenintundfloat. Wenn sowohlintals auchfloatingunterstützt werden, ist die Angabe des dtypes nicht erforderlich.Wenn der Standardwert
Noneist, mussNonenur am Ende mitdefault=Noneangegeben werden. Stellen Sie sicher, dass im Docstring angegeben wird, was es bedeutet, wenn der Parameter oder das AttributNoneist.
Fügen Sie in Docstrings für verwandte Klassen/Funktionen „See Also“ hinzu.
„See Also“ in Docstrings sollte eine Zeile pro Referenz sein, mit einem Doppelpunkt und einer Erklärung, zum Beispiel:
See Also -------- SelectKBest : Select features based on the k highest scores. SelectFpr : Select features based on a false positive rate test.
Der Abschnitt „Notes“ ist optional. Er dient der Bereitstellung von Informationen über das spezifische Verhalten einer Funktion/Klasse/Methode/Klassenmethode.
Eine
Notekann auch einem Attribut hinzugefügt werden, erfordert dann aber die Verwendung der Direktive.. rubric:: Note.Fügen Sie im Abschnitt „Example“ ein oder zwei Codeausschnitte hinzu, um zu zeigen, wie es verwendet werden kann. Der Code sollte direkt ausführbar sein, d. h. er sollte alle erforderlichen Importe enthalten. Halten Sie diesen Abschnitt so kurz wie möglich.
Richtlinien für das Schreiben des Benutzerhandbuchs und anderer reStructuredText-Dokumente#
Es ist wichtig, einen guten Kompromiss zwischen mathematischen und algorithmischen Details zu finden und dem Leser eine Intuition dafür zu vermitteln, was der Algorithmus tut.
Beginnen Sie mit einer prägnanten, vereinfachten Erklärung dessen, was der Algorithmus/Code mit den Daten tut.
Heben Sie den Nutzen der Funktion und ihre empfohlene Anwendung hervor. Erwägen Sie die Einbeziehung der Komplexität des Algorithmus (\(O\left(g\left(n\right)\right)\)), falls verfügbar, da „Faustregeln“ sehr maschinenabhängig sein können. Nur wenn diese Komplexitäten nicht verfügbar sind, können stattdessen Faustregeln angegeben werden.
Integrieren Sie eine relevante Abbildung (generiert aus einem Beispiel), um Intuitionen zu vermitteln.
Fügen Sie ein oder zwei kurze Codebeispiele hinzu, um die Verwendung der Funktion zu demonstrieren.
Führen Sie alle notwendigen mathematischen Gleichungen ein, gefolgt von Referenzen. Durch die Zurückstellung der mathematischen Aspekte wird die Dokumentation für Benutzer zugänglicher, die sich hauptsächlich dafür interessieren, die praktischen Auswirkungen der Funktion zu verstehen, anstatt ihre zugrunde liegenden Mechanismen.
Beim Bearbeiten von reStructuredText-Dateien (
.rst) versuchen Sie, die Zeilenlänge nach Möglichkeit unter 88 Zeichen zu halten (Ausnahmen sind Links und Tabellen).In Scikit-Learn reStructuredText-Dateien werden sowohl einzelne als auch doppelte Backticks, die Text umschließen, als Inline-Literal gerendert (oft für Code verwendet, z. B.
list). Dies liegt an spezifischen Konfigurationen, die wir eingerichtet haben. Heutzutage sollten einzelne Backticks verwendet werden.Zu viele Informationen erschweren es den Benutzern, auf die Inhalte zuzugreifen, an denen sie interessiert sind. Verwenden Sie Dropdowns, um sie zu faktorisieren, indem Sie die folgende Syntax verwenden:
.. dropdown:: Dropdown title Dropdown content.
Der obige Ausschnitt ergibt das folgende Dropdown:
Dropdown-Titel#
Dropdown-Inhalt.
Informationen, die standardmäßig über Dropdowns ausgeblendet werden können, sind:
Abschnitte mit niedriger Hierarchie wie
References,Propertiesusw. (siehe zum Beispiel die Unterabschnitte in Detection error tradeoff (DET));detaillierte mathematische Details;
narrative, die fallspezifisch sind;
im Allgemeinen narrative, die möglicherweise nur Benutzer interessieren, die über die Pragmatik eines bestimmten Werkzeugs hinausgehen möchten.
Verwenden Sie keine Dropdowns für den Low-Level-Abschnitt
Examples, da dieser für alle Benutzer sichtbar bleiben sollte. Stellen Sie sicher, dass der AbschnittExamplesdirekt nach der Hauptdiskussion mit möglichst wenigen gefalteten Abschnitten dazwischen kommt.Beachten Sie, dass Dropdowns Querverweise brechen. Wenn dies sinnvoll ist, blenden Sie den Verweis zusammen mit dem Text, der ihn erwähnt, aus. Andernfalls verwenden Sie kein Dropdown.
Richtlinien für das Schreiben von Referenzen#
Wenn bibliografische Referenzen mit arxiv oder Digital Object Identifier Identifikationsnummern verfügbar sind, verwenden Sie die Sphinx-Direktiven
:arxiv:oder:doi:. Sehen Sie beispielsweise Referenzen in Spectral Clustering Graphs.Für den Abschnitt „References“ in Docstrings siehe
sklearn.metrics.silhouette_scoreals Beispiel.Um auf andere Seiten der Scikit-Learn-Dokumentation zu verweisen, verwenden Sie die reStructuredText-Syntax für Querverweise.
Abschnitt: Um auf einen beliebigen Abschnitt in der Dokumentation zu verlinken, verwenden Sie Referenz-Labels (siehe Sphinx docs). Zum Beispiel:
.. _my-section: My section ---------- This is the text of the section. To refer to itself use :ref:`my-section`.
Sie sollten keine bestehenden Sphinx-Referenz-Labels ändern, da dies bestehende Querverweise und externe Links, die auf bestimmte Abschnitte in der Scikit-Learn-Dokumentation zeigen, brechen würde.
Glossar: Verlinkung zu einem Begriff im Glossar der gebräuchlichen Begriffe und API-Elemente.
:term:`cross_validation`
Funktion: Um auf die Dokumentation einer Funktion zu verlinken, verwenden Sie den vollständigen Importpfad zur Funktion.
:func:`~sklearn.model_selection.cross_val_score`
Wenn jedoch eine Direktive
.. currentmodule::oberhalb im Dokument vorhanden ist, müssen Sie nur den Pfad zur Funktion nach dem aktuellen Modul angeben. Zum Beispiel:.. currentmodule:: sklearn.model_selection :func:`cross_val_score`
Klasse: Um auf die Dokumentation einer Klasse zu verlinken, verwenden Sie den vollständigen Importpfad zur Klasse, es sei denn, es gibt eine Direktive
.. currentmodule::im Dokument darüber (siehe oben).:class:`~sklearn.preprocessing.StandardScaler`
Sie können die Dokumentation mit jedem Texteditor bearbeiten und dann die HTML-Ausgabe generieren, indem Sie Die Dokumentation erstellen befolgen. Die resultierenden HTML-Dateien werden in _build/html/ platziert und können in einem Webbrowser angezeigt werden, z. B. durch Öffnen der lokalen Datei _build/html/index.html oder durch Ausführen eines lokalen Servers.
python -m http.server -d _build/html
Die Dokumentation erstellen#
Überprüfen Sie vor dem Einreichen eines Pull Requests, ob Ihre Änderungen neue Sphinx-Warnungen eingeführt haben, indem Sie die Dokumentation lokal erstellen und versuchen, diese zu beheben.
Stellen Sie zunächst sicher, dass Sie die Entwicklungsversion ordnungsgemäß installiert haben. Darüber hinaus erfordert das Erstellen der Dokumentation die Installation einiger zusätzlicher Pakete.
pip install sphinx sphinx-gallery numpydoc matplotlib Pillow pandas \
polars scikit-image packaging seaborn sphinx-prompt \
sphinxext-opengraph sphinx-copybutton plotly pooch \
pydata-sphinx-theme sphinxcontrib-sass sphinx-design \
sphinx-remove-toctrees
Um die Dokumentation zu erstellen, müssen Sie sich im Ordner doc befinden.
cd doc
In den allermeisten Fällen müssen Sie nur die Website ohne die Beispielgalerie generieren.
make
Die Dokumentation wird im Verzeichnis _build/html/stable generiert und kann in einem Webbrowser angezeigt werden, beispielsweise durch Öffnen der lokalen Datei _build/html/stable/index.html. Um auch die Beispielgalerie zu generieren, können Sie verwenden:
make html
Dies führt alle Beispiele aus, was eine Weile dauert. Sie können auch nur wenige Beispiele anhand ihrer Dateinamen ausführen. Hier ist eine Möglichkeit, alle Beispiele mit Dateinamen auszuführen, die plot_calibration enthalten:
EXAMPLES_PATTERN="plot_calibration" make html
Sie können reguläre Ausdrücke für fortgeschrittenere Anwendungsfälle verwenden.
Setzen Sie die Umgebungsvariable NO_MATHJAX=1, wenn Sie die Dokumentation offline anzeigen möchten. Zum Erstellen des PDF-Handbuchs führen Sie aus:
make latexpdf
Sphinx-Version
Obwohl wir unser Bestes tun, um die Dokumentation unter möglichst vielen Sphinx-Versionen zu erstellen, verhalten sich die verschiedenen Versionen tendenziell leicht unterschiedlich. Um die besten Ergebnisse zu erzielen, sollten Sie die gleiche Version verwenden wie die, die wir auf CircleCI verwendet haben. Sehen Sie sich diese GitHub-Suche an, um die genaue Version zu erfahren.
Generierte Dokumentation auf GitHub Actions#
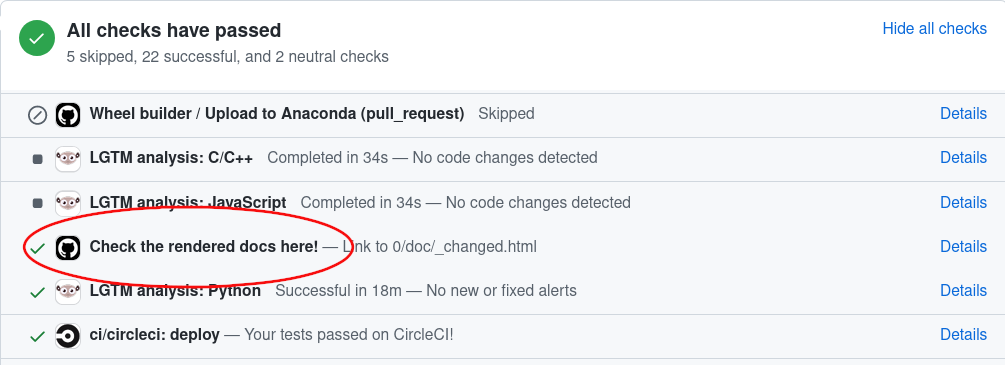
Wenn Sie die Dokumentation in einem Pull Request ändern, erstellt GitHub Actions diese automatisch. Um die von GitHub Actions generierte Dokumentation anzuzeigen, gehen Sie einfach zum Ende Ihrer PR-Seite, suchen Sie nach dem Eintrag „Check the rendered docs here!“ und klicken Sie auf „details“ daneben.
Tests und Verbesserung der Testabdeckung#
Hochwertige Unit-Tests sind ein Eckpfeiler des Entwicklungsprozesses von Scikit-Learn. Zu diesem Zweck verwenden wir das Paket pytest. Die Tests sind entsprechend benannte Funktionen, die sich in tests Unterverzeichnissen befinden und die Gültigkeit der Algorithmen und der verschiedenen Optionen des Codes überprüfen.
Das Ausführen von pytest in einem Ordner führt alle Tests der entsprechenden Unterpakete aus. Für einen detaillierteren pytest Workflow verweisen Sie bitte auf die Checkliste für Pull Requests.
Wir erwarten eine Codeabdeckung für neue Features von mindestens etwa 90 %.
Workflow zur Verbesserung der Testabdeckung#
Um die Codeabdeckung zu testen, müssen Sie zusätzlich zu pytest das Paket coverage installieren.
Führen Sie
pytest --cov sklearn /path/to/testsaus. Die Ausgabe listet für jede Datei die nicht getesteten Zeilennummern auf.Finden Sie eine leicht zu behebende Stelle, indem Sie sehen, welche Zeilen nicht getestet sind, schreiben oder passen Sie einen Test speziell für diese Zeilen an.
Schleife.
Leistungsüberwachung#
Dieser Abschnitt ist stark inspiriert von der Pandas-Dokumentation.
Bei Vorschlägen für Änderungen an der bestehenden Codebasis ist es wichtig sicherzustellen, dass diese keine Leistungsregressionen verursachen. Scikit-Learn verwendet ASV-Benchmarks, um die Leistung einer Auswahl gängiger Schätzer und Funktionen zu überwachen. Sie können diese Benchmarks auf der Scikit-Learn Benchmark-Seite einsehen. Die entsprechende Benchmark-Suite befindet sich im Verzeichnis asv_benchmarks/.
Um alle Funktionen von ASV nutzen zu können, benötigen Sie entweder conda oder virtualenv. Weitere Details finden Sie auf der ASV-Installationswebseite.
Zunächst müssen Sie die Entwicklungsversion von ASV installieren.
pip install git+https://github.com/airspeed-velocity/asv
und wechseln Sie Ihr Verzeichnis zu asv_benchmarks/.
cd asv_benchmarks
Die Benchmark-Suite ist so konfiguriert, dass sie gegen Ihren lokalen Klon von Scikit-Learn läuft. Stellen Sie sicher, dass er auf dem neuesten Stand ist.
git fetch upstream
In der Benchmark-Suite sind die Benchmarks nach der gleichen Struktur wie Scikit-Learn organisiert. Sie können beispielsweise die Leistung eines bestimmten Schätzers zwischen upstream/main und dem Branch, an dem Sie arbeiten, vergleichen.
asv continuous -b LogisticRegression upstream/main HEAD
Der Befehl verwendet standardmäßig Conda zum Erstellen der Benchmark-Umgebungen. Wenn Sie stattdessen virtualenv verwenden möchten, verwenden Sie das Flag -E.
asv continuous -E virtualenv -b LogisticRegression upstream/main HEAD
Sie können auch ein ganzes Modul zum Benchmarken angeben.
asv continuous -b linear_model upstream/main HEAD
Sie können HEAD durch jeden lokalen Branch ersetzen. Standardmäßig werden nur die Benchmarks gemeldet, die sich um mindestens 10 % geändert haben. Sie können dieses Verhältnis mit dem Flag -f steuern.
Um die vollständige Benchmark-Suite auszuführen, entfernen Sie einfach das Flag -b.
asv continuous upstream/main HEAD
Dies kann jedoch bis zu zwei Stunden dauern. Das Flag -b akzeptiert auch einen regulären Ausdruck für eine komplexere Teilmenge von Benchmarks, die ausgeführt werden sollen.
Um die Benchmarks auszuführen, ohne sie mit einem anderen Branch zu vergleichen, verwenden Sie den Befehl run.
asv run -b linear_model HEAD^!
Sie können die Benchmark-Suite auch mit der Version von Scikit-Learn ausführen, die bereits in Ihrer aktuellen Python-Umgebung installiert ist.
asv run --python=same
Dies ist besonders nützlich, wenn Sie Scikit-Learn im editierbaren Modus installiert haben, um die Erstellung einer neuen Umgebung bei jeder Ausführung der Benchmarks zu vermeiden. Standardmäßig werden die Ergebnisse bei Verwendung einer vorhandenen Installation nicht gespeichert. Um die Ergebnisse zu speichern, müssen Sie einen Commit-Hash angeben.
asv run --python=same --set-commit-hash=<commit hash>
Benchmarks werden nach Maschine, Umgebung und Commit gespeichert und organisiert. Um die Liste aller gespeicherten Benchmarks anzuzeigen:
asv show
und um den Bericht eines bestimmten Laufs anzuzeigen:
asv show <commit hash>
Wenn Sie Benchmarks für einen Pull Request ausführen, an dem Sie arbeiten, melden Sie bitte die Ergebnisse auf GitHub.
Die Benchmark-Suite unterstützt zusätzliche konfigurierbare Optionen, die in der Konfigurationsdatei benchmarks/config.json festgelegt werden können. So können die Benchmarks beispielsweise für eine bereitgestellte Liste von Werten für den Parameter n_jobs ausgeführt werden.
Weitere Informationen zum Schreiben eines Benchmarks und zur Verwendung von ASV finden Sie in der ASV-Dokumentation.
Aufrechterhaltung der Abwärtskompatibilität#
Deprecation#
Wenn eine öffentlich zugängliche Klasse, Funktion, Methode, Attribut oder ein Parameter umbenannt wird, unterstützen wir das alte noch zwei Releases lang und geben eine Deprecation-Warnung aus, wenn es aufgerufen, übergeben oder darauf zugegriffen wird.
Deprecating einer Klasse oder Funktion
Angenommen, die Funktion zero_one wird in zero_one_loss umbenannt, fügen wir den Dekorator utils.deprecated zu zero_one hinzu und rufen zero_one_loss von dieser Funktion aus auf.
from sklearn.utils import deprecated
def zero_one_loss(y_true, y_pred, normalize=True):
# actual implementation
pass
@deprecated(
"Function `zero_one` was renamed to `zero_one_loss` in 0.13 and will be "
"removed in 0.15. Default behavior is changed from `normalize=False` to "
"`normalize=True`"
)
def zero_one(y_true, y_pred, normalize=False):
return zero_one_loss(y_true, y_pred, normalize)
Außerdem muss zero_one von API_REFERENCE in DEPRECATED_API_REFERENCE verschoben und zero_one_loss in API_REFERENCE in der Datei doc/api_reference.py hinzugefügt werden, um die Änderungen in der API-Referenz widerzuspiegeln.
Deprecating eines Attributs oder einer Methode
Wenn ein Attribut oder eine Methode veraltet werden soll, verwenden Sie den Dekorator deprecated für die Eigenschaft. Bitte beachten Sie, dass der Dekorator deprecated vor dem property-Dekorator platziert werden sollte, falls vorhanden, damit die Docstrings ordnungsgemäß gerendert werden können. Beispielsweise kann die Umbenennung eines Attributs labels_ in classes_ wie folgt erfolgen:
@deprecated(
"Attribute `labels_` was deprecated in 0.13 and will be removed in 0.15. Use "
"`classes_` instead"
)
@property
def labels_(self):
return self.classes_
Deprecating eines Parameters
Wenn ein Parameter veraltet werden muss, muss manuell eine FutureWarning-Warnung ausgegeben werden. Im folgenden Beispiel ist k veraltet und wird in n_clusters umbenannt.
import warnings
def example_function(n_clusters=8, k="deprecated"):
if k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15",
FutureWarning,
)
n_clusters = k
Wenn die Änderung in einer Klasse erfolgt, validieren und warnen wir in fit.
import warnings
class ExampleEstimator(BaseEstimator):
def __init__(self, n_clusters=8, k='deprecated'):
self.n_clusters = n_clusters
self.k = k
def fit(self, X, y):
if self.k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15.",
FutureWarning,
)
self._n_clusters = self.k
else:
self._n_clusters = self.n_clusters
Wie in diesen Beispielen sollte die Warnmeldung immer sowohl die Version angeben, in der die Deprecation stattfand, als auch die Version, in der das alte Verhalten entfernt wird. Wenn die Deprecation in Version 0.x-dev stattfand, sollte die Meldung besagen, dass die Deprecation in Version 0.x stattgefunden hat und die Entfernung in 0.(x+2) erfolgen wird, damit die Benutzer genügend Zeit haben, ihren Code an das neue Verhalten anzupassen. Wenn die Deprecation beispielsweise in Version 0.18-dev stattfand, sollte die Meldung besagen, dass sie in Version 0.18 stattgefunden hat und das alte Verhalten in Version 0.20 entfernt wird.
Die Warnmeldung sollte auch eine kurze Erklärung der Änderung enthalten und die Benutzer auf eine Alternative hinweisen.
Zusätzlich sollte eine Deprecation-Notiz im Docstring hinzugefügt werden, die die gleichen Informationen wie die Deprecation-Warnung enthält, wie oben erläutert. Verwenden Sie die Direktive .. deprecated::.
.. deprecated:: 0.13
``k`` was renamed to ``n_clusters`` in version 0.13 and will be removed
in 0.15.
Darüber hinaus erfordert eine Deprecation einen Test, der sicherstellt, dass die Warnung in relevanten Fällen ausgelöst wird, aber nicht in anderen Fällen. Die Warnung sollte in allen anderen Tests abgefangen werden (z. B. mit @pytest.mark.filterwarnings), und in den Beispielen sollte keine Warnung auftreten.
Änderung des Standardwerts eines Parameters#
Wenn der Standardwert eines Parameters geändert werden muss, ersetzen Sie bitte den Standardwert durch einen spezifischen Wert (z. B. "warn") und geben Sie eine FutureWarning aus, wenn Benutzer den Standardwert verwenden. Das folgende Beispiel geht davon aus, dass die aktuelle Version 0.20 ist und wir den Standardwert von n_clusters von 5 (alter Standard für 0.20) auf 10 (neuer Standard für 0.22) ändern.
import warnings
def example_function(n_clusters="warn"):
if n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
n_clusters = 5
Wenn die Änderung in einer Klasse erfolgt, validieren und warnen wir in fit.
import warnings
class ExampleEstimator:
def __init__(self, n_clusters="warn"):
self.n_clusters = n_clusters
def fit(self, X, y):
if self.n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
self._n_clusters = 5
Ähnlich wie bei Deprecations sollte die Warnmeldung immer sowohl die Version angeben, in der die Änderung stattgefunden hat, als auch die Version, in der das alte Verhalten entfernt wird.
Die Parameterbeschreibung im Docstring muss entsprechend aktualisiert werden, indem eine Direktive versionchanged mit dem alten und neuen Standardwert hinzugefügt wird, die auf die Version verweist, ab der die Änderung wirksam wird.
.. versionchanged:: 0.22
The default value for `n_clusters` will change from 5 to 10 in version 0.22.
Schließlich benötigen wir einen Test, der sicherstellt, dass die Warnung in relevanten Fällen ausgelöst wird, aber nicht in anderen Fällen. Die Warnung sollte in allen anderen Tests abgefangen werden (z. B. mit @pytest.mark.filterwarnings), und in den Beispielen sollte keine Warnung auftreten.
Richtlinien für Code-Reviews#
Die Überprüfung von Code, der dem Projekt als PRs beigesteuert wird, ist ein entscheidender Bestandteil der Scikit-Learn-Entwicklung. Wir ermutigen jeden, den Code anderer Entwickler zu überprüfen. Der Code-Review-Prozess ist oft für alle Beteiligten sehr lehrreich. Dies ist besonders angebracht, wenn es sich um ein Feature handelt, das Sie nutzen möchten, und Sie daher kritisch beurteilen können, ob der PR Ihren Anforderungen entspricht. Während jeder Pull Request von zwei Kernentwicklern abgenommen werden muss, können Sie diesen Prozess beschleunigen, indem Sie Ihr Feedback geben.
Hinweis
Der Unterschied zwischen einer objektiven Verbesserung und einer subjektiven Kleinigkeit ist nicht immer klar. Gutachter sollten bedenken, dass Code-Reviews in erster Linie dazu dienen, Risiken im Projekt zu reduzieren. Bei der Überprüfung von Code sollte man darauf abzielen, Situationen zu verhindern, die eine Fehlerbehebung, eine Deprecation oder einen Rückzug erfordern könnten. Bezüglich der Dokumentation: Tippfehler, Grammatikfehler und Unklarheiten werden besser sofort behoben.
Wichtige Aspekte, die bei jeder Code-Überprüfung abgedeckt werden müssen#
Hier sind einige wichtige Aspekte, die bei jeder Code-Überprüfung abgedeckt werden müssen, von übergeordneten Fragen bis hin zu einer detaillierteren Checkliste.
Möchten wir das in der Bibliothek haben? Wird es wahrscheinlich verwendet werden? Gefällt Ihnen als scikit-learn-Benutzer die Änderung und beabsichtigen Sie, sie zu verwenden? Liegt es im Geltungsbereich von scikit-learn? Lohnt sich der Wartungsaufwand für eine neue Funktion im Vergleich zu ihrem Nutzen?
Ist der Code mit der API von scikit-learn konsistent? Sind öffentliche Funktionen/Klassen/Parameter gut benannt und intuitiv gestaltet?
Sind alle öffentlichen Funktionen/Klassen und ihre Parameter, Rückgabetypen und gespeicherten Attribute gemäß den scikit-learn-Konventionen benannt und klar dokumentiert?
Wird jede neue Funktionalität in der Benutzeranleitung beschrieben und mit Beispielen veranschaulicht?
Ist jede öffentliche Funktion/Klasse getestet? Wird eine angemessene Auswahl an Parametern, deren Werten, Wertetypen und Kombinationen getestet? Validieren die Tests, dass der Code korrekt ist, d. h. dass er das tut, was die Dokumentation besagt? Wenn es sich bei der Änderung um eine Fehlerkorrektur handelt, ist ein Nicht-Regressionstest enthalten? Diese Tests verifizieren das korrekte Verhalten der Korrektur oder Funktion. Auf diese Weise wird sichergestellt, dass weitere Änderungen an der Codebasis mit dem gewünschten Verhalten übereinstimmen. Im Falle von Fehlerkorrekturen sollten die Nicht-Regressionstests zum Zeitpunkt des PRs für die Codebasis im
main-Branch fehlschlagen und für den PR-Code erfolgreich sein.Werden die Tests im Continuous Integration Build bestanden? Helfen Sie dem Mitwirkenden gegebenenfalls zu verstehen, warum Tests fehlgeschlagen sind.
Decken die Tests jede Codezeile ab (siehe den Coverage-Bericht im Build-Log)? Wenn nicht, sind die Zeilen, die nicht abgedeckt sind, gute Ausnahmen?
Ist der Code leicht zu lesen und frei von Redundanzen? Sollten Variablennamen zur Klarheit oder Konsistenz verbessert werden? Sollten Kommentare hinzugefügt werden? Sollten Kommentare als hilfreich oder überflüssig entfernt werden?
Könnte der Code für relevante Einstellungen viel effizienter umgeschrieben werden?
Ist der Code abwärtskompatibel mit früheren Versionen? (Oder ist ein Deprecationszyklus erforderlich?)
Wird der neue Code Abhängigkeiten von anderen Bibliotheken hinzufügen? (Dies wird wahrscheinlich nicht akzeptiert)
Wird die Dokumentation korrekt gerendert (weitere Details finden Sie im Abschnitt Dokumentation) und sind die Plots lehrreich?
Standardantworten für die Überprüfung enthält einige häufige Kommentare, die Gutachter machen können.
Kommunikationsrichtlinien#
Die Überprüfung offener Pull Requests (PRs) hilft, das Projekt voranzubringen. Es ist eine großartige Möglichkeit, sich mit der Codebasis vertraut zu machen, und sollte den Mitwirkenden motivieren, sich weiterhin am Projekt zu beteiligen. [1]
Jeder PR, ob gut oder schlecht, ist ein Akt der Großzügigkeit. Wenn Sie mit einem positiven Kommentar beginnen, fühlt sich der Autor belohnt, und Ihre anschließenden Anmerkungen werden möglicherweise besser gehört. Sie könnten sich auch gut fühlen.
Beginnen Sie, wenn möglich, mit den großen Problemen, damit der Autor versteht, dass er verstanden wurde. Widerstehen Sie der Versuchung, sofort Zeile für Zeile vorzugehen oder mit kleinen, allgegenwärtigen Problemen zu beginnen.
Lassen Sie nicht zu, dass Perfektion das Gute behindert. Wenn Sie viele kleine Vorschläge machen, die nicht in die Code-Review-Richtlinien fallen, erwägen Sie die folgenden Ansätze:
unterlassen Sie es, diese einzureichen;
kennzeichnen Sie diese als „Nit“, damit der Mitwirkende weiß, dass es in Ordnung ist, sie nicht zu bearbeiten;
verfolgen Sie dies in einem nachfolgenden PR nach, aus Höflichkeit möchten Sie vielleicht den ursprünglichen Mitwirkenden informieren.
Nehmen Sie sich Zeit, um Ihre Kommentare klar zu formulieren und Ihre Vorschläge zu begründen.
Sie sind das Gesicht des Projekts. Schlechte Tage hat jeder, in solchen Fällen verdienen Sie eine Pause: Versuchen Sie, sich Zeit zu nehmen und offline zu bleiben.
Lesen der bestehenden Codebasis#
Das Lesen und Verstehen einer bestehenden Codebasis ist immer eine schwierige Aufgabe, die Zeit und Erfahrung erfordert, um sie zu beherrschen. Auch wenn wir versuchen, im Allgemeinen einfachen Code zu schreiben, kann das Verständnis des Codes auf den ersten Blick angesichts der schieren Größe des Projekts überwältigend erscheinen. Hier ist eine Liste von Tipps, die diese Aufgabe erleichtern und beschleunigen können (in keiner bestimmten Reihenfolge).
Machen Sie sich mit den APIs von scikit-learn-Objekten vertraut: Verstehen Sie, wofür fit, predict, transform usw. verwendet werden.
Bevor Sie sich mit dem Lesen des Codes einer Funktion/Klasse beschäftigen, lesen Sie zuerst die Docstrings und versuchen Sie, eine Vorstellung davon zu bekommen, was jeder Parameter/jedes Attribut bewirkt. Es kann auch helfen, eine Minute innezuhalten und darüber nachzudenken, *wie würde ich das selbst machen, wenn ich müsste?*
Das Schwierigste ist oft, die relevanten Codeabschnitte zu identifizieren. In scikit-learn wird **sehr viel** Eingabeüberprüfung durchgeführt, insbesondere zu Beginn der fit -Methoden. Manchmal erledigt nur ein sehr kleiner Teil des Codes die eigentliche Arbeit. Wenn Sie sich zum Beispiel die
fit-Methode vonLinearRegressionansehen, suchen Sie vielleicht nur nach dem Aufruf vonscipy.linalg.lstsq, aber dieser ist in mehreren Zeilen von Eingabeüberprüfungen und der Handhabung verschiedener Parameterarten begraben.Aufgrund der Verwendung von Vererbung können einige Methoden in übergeordneten Klassen implementiert sein. Alle Schätzer erben mindestens von
BaseEstimatorund von einerMixin-Klasse (z. B.ClassifierMixin), die ein Standardverhalten je nach Art des Schätzers (Klassifikator, Regressor, Transformer usw.) ermöglicht.Manchmal gibt Ihnen das Lesen der Tests für eine bestimmte Funktion eine Vorstellung davon, was ihr beabsichtigter Zweck ist. Sie können
git grep(siehe unten) verwenden, um alle Tests für eine Funktion zu finden. Die meisten Tests für eine bestimmte Funktion/Klasse befinden sich im Ordnertests/des ModulsSie werden oft Code wie diesen sehen:
out = Parallel(...)(delayed(some_function)(param) for param in some_iterable). Dies führtsome_functionparallel mit Joblib aus.outist dann ein iterierbares Objekt, das die vonsome_functionzurückgegebenen Werte für jeden Aufruf enthält.Wir verwenden Cython, um schnellen Code zu schreiben. Cython-Code befindet sich in
.pyx- und.pxd-Dateien. Cython-Code hat einen eher C-ähnlichen Stil: Wir verwenden Zeiger, führen manuelle Speicherzuweisung durch usw. Etwas minimale Erfahrung in C/C++ ist hier praktisch zwingend erforderlich. Weitere Informationen finden Sie unter Cython Best Practices, Conventions and Knowledge.Meistern Sie Ihre Werkzeuge.
Bei einem so großen Projekt ist Effizienz mit Ihrem bevorzugten Editor oder Ihrer IDE ein wichtiger Schritt, um die Codebasis zu verstehen. Die Möglichkeit, schnell zu einer Funktions-/Klassen-/Attributdefinition zu springen (oder sie zu *anzeigen*), hilft sehr. Ebenso die Möglichkeit, schnell zu sehen, wo ein bestimmter Name in einer Datei verwendet wird.
Git verfügt auch über einige integrierte Killerfunktionen. Es ist oft nützlich, zu verstehen, wie sich eine Datei im Laufe der Zeit geändert hat, z. B. mit
git blame(Handbuch). Dies kann auch direkt auf GitHub erfolgen.git grep(Beispiele) ist ebenfalls äußerst nützlich, um alle Vorkommen eines Musters (z. B. eines Funktionsaufrufs oder einer Variablen) in der Codebasis anzuzeigen.
Konfigurieren Sie
git blameso, dass der Commit ignoriert wird, der den Codestil aufblackund dannruffmigriert hat.git config blame.ignoreRevsFile .git-blame-ignore-revsWeitere Informationen finden Sie in der Dokumentation von black zur Vermeidung der Beschädigung von git blame.