Beispiele#
Dies ist die Galerie von Beispielen, die zeigen, wie scikit-learn verwendet werden kann. Einige Beispiele demonstrieren die allgemeine Verwendung der API, andere demonstrieren spezifische Anwendungen in Tutorial-Form. Lesen Sie auch unseren Benutzerhandbuch für detailliertere Erläuterungen.
Release-Highlights#
Diese Beispiele veranschaulichen die Hauptmerkmale der scikit-learn-Releases.




Biclustering#
Beispiele zu Biclustering-Techniken.

Biclustering von Dokumenten mit dem Spectral Co-Clustering Algorithmus
Kalibrierung#
Beispiele, die die Kalibrierung von vorhergesagten Wahrscheinlichkeiten von Klassifikatoren veranschaulichen.
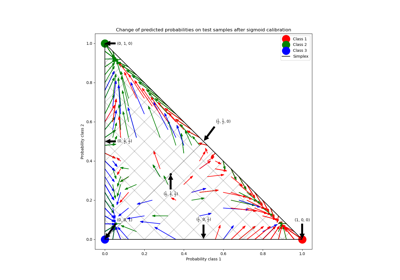
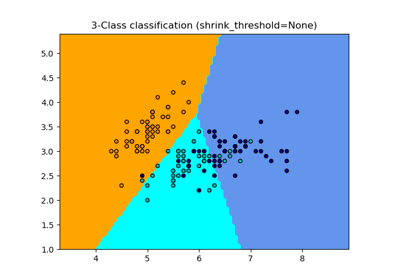
Wahrscheinlichkeitskalibrierung für 3-Klassen-Klassifikation
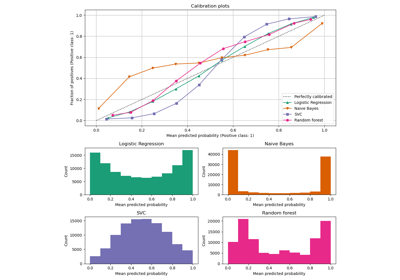
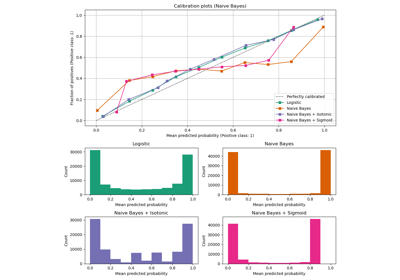
Wahrscheinlichkeitskalibrierung von Klassifikatoren
Klassifizierung#
Allgemeine Beispiele zu Klassifizierungsalgorithmen.

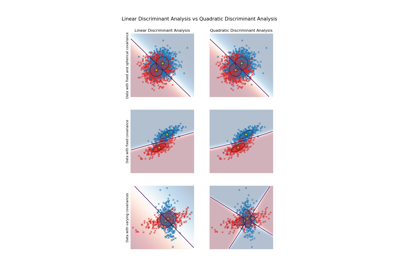
Lineare und Quadratische Diskriminanzanalyse mit Kovarianzellipsoid
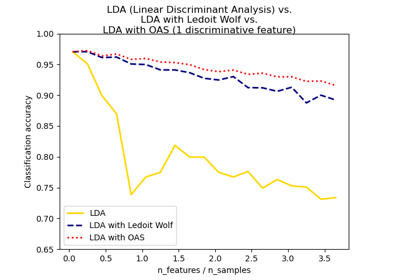
Normale, Ledoit-Wolf und OAS Lineare Diskriminanzanalyse zur Klassifikation
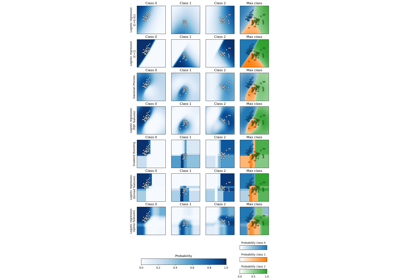
Clustering#
Beispiele zum sklearn.cluster Modul.
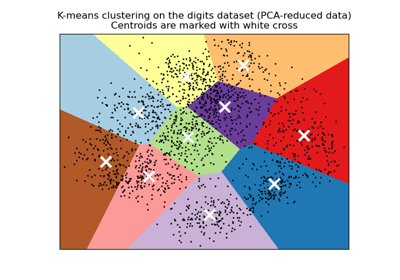
Eine Demo des K-Means Clusterings auf den handschriftlichen Zifferndaten

Eine Demo des strukturierten Ward Hierarchischen Clusterings auf einem Bild von Münzen
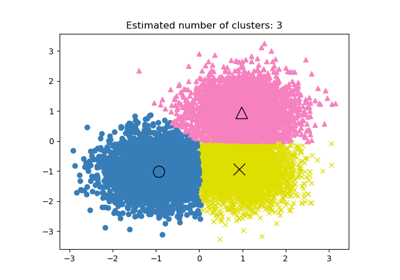
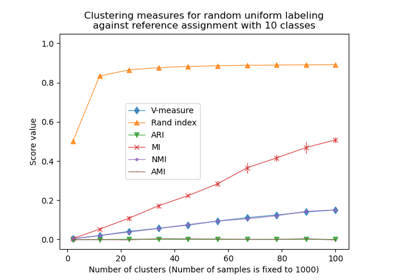
Anpassung für Zufälligkeit in der Clusterleistungsbewertung
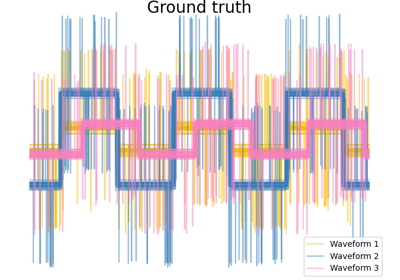
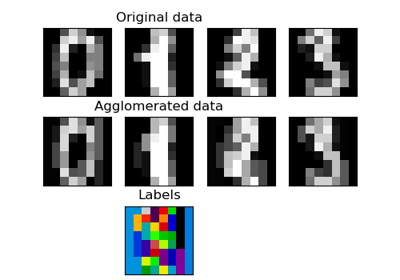
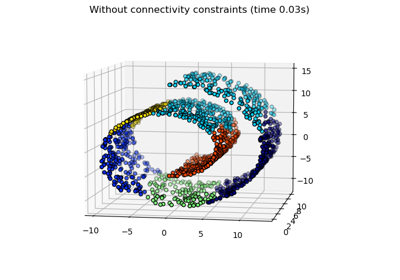
Agglomeratives Clustering mit verschiedenen Metriken
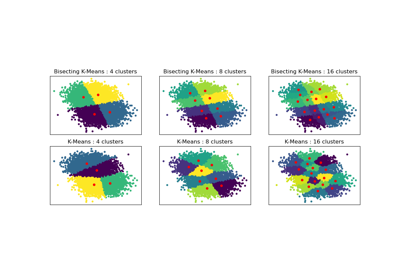
Vergleich der Leistung von Bisecting K-Means und Regular K-Means
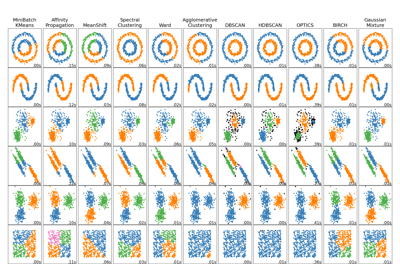
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen
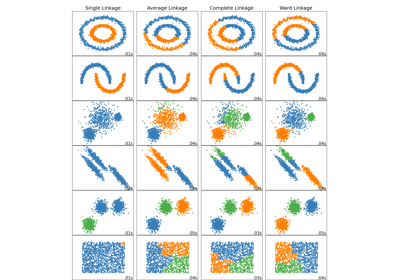
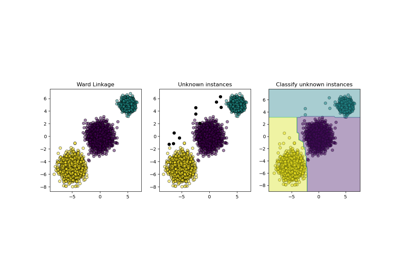
Vergleich verschiedener hierarchischer Linkage-Methoden auf Toy-Datensätzen
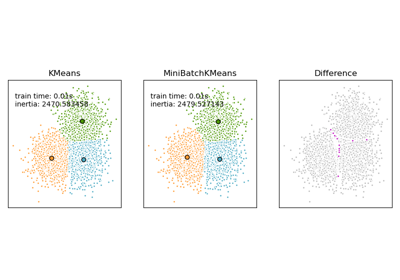
Vergleich der K-Means und MiniBatchKMeans Clustering-Algorithmen
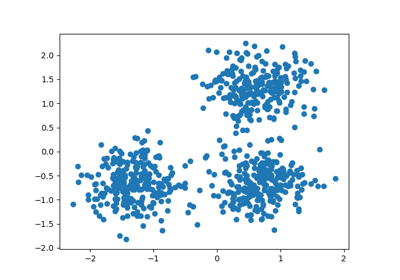
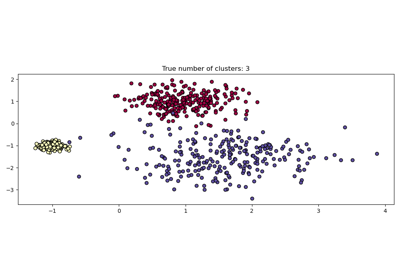
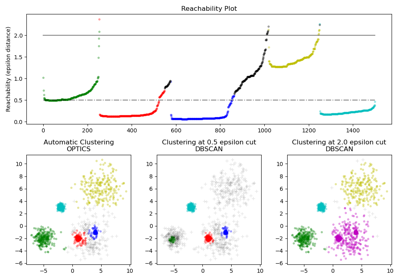
Demo des Affinity Propagation Clustering Algorithmus
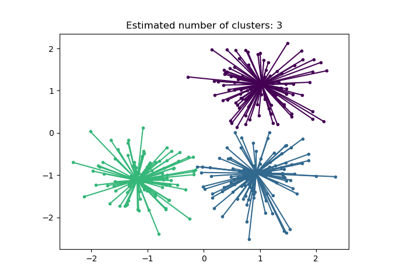
Empirische Auswertung des Einflusses der K-Means Initialisierung


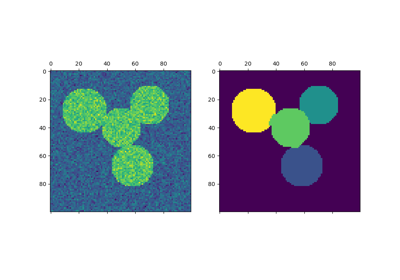
Segmentierung des Bildes von griechischen Münzen in Regionen
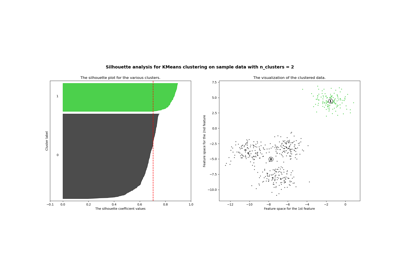
Auswahl der Anzahl von Clustern mit Silhouette-Analyse auf KMeans-Clustering
Verschiedenes Agglomeratives Clustering auf einer 2D-Einbettung von Ziffern
Kovarianzschätzung#
Beispiele zum sklearn.covariance Modul.
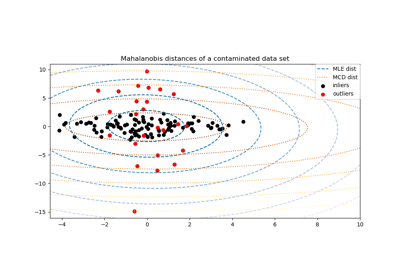
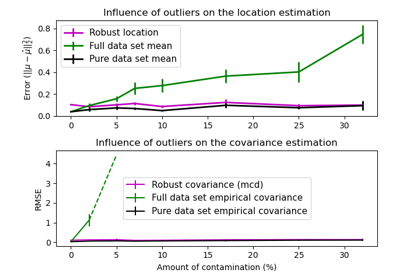
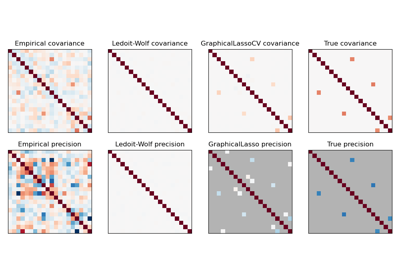
Robuste Kovarianzschätzung und Relevanz von Mahalanobis-Distanzen
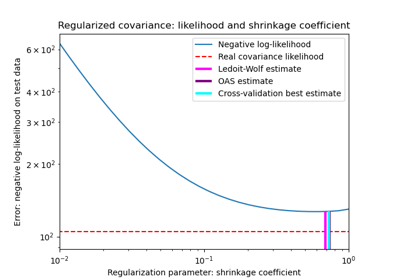
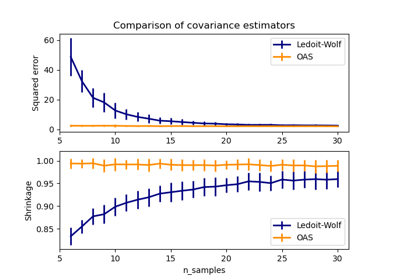
Schrumpfkovarianzschätzung: LedoitWolf vs OAS und Maximum-Likelihood
Kreuzzerlegung#
Beispiele zum sklearn.cross_decomposition Modul.
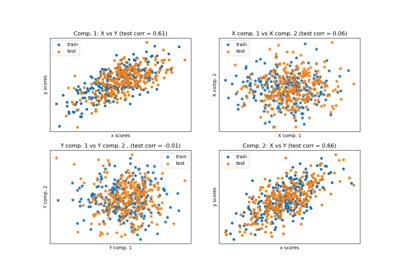
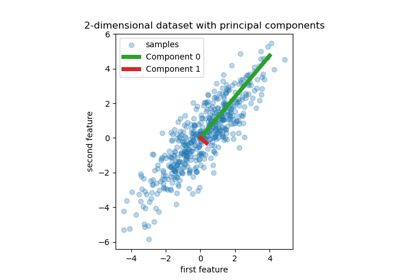
Principal Component Regression vs. Partial Least Squares Regression
Datensatzbeispiele#
Beispiele zum sklearn.datasets Modul.
Entscheidungsbäume#
Beispiele zum sklearn.tree Modul.
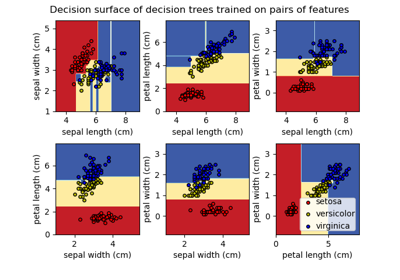
Entscheidungsfläche von Entscheidungsbäumen, trainiert auf dem Iris-Datensatz, plotten
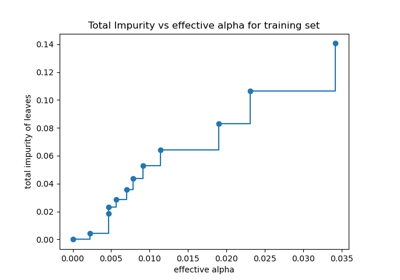
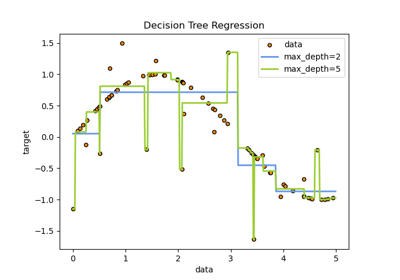
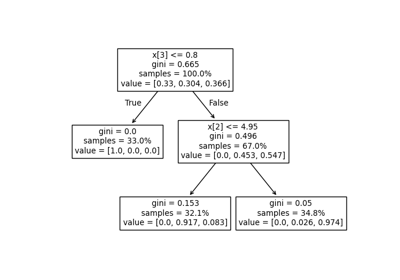
Post-Pruning Entscheidungsbäume mit Kostenkomplexität
Zerlegung#
Beispiele zum sklearn.decomposition Modul.
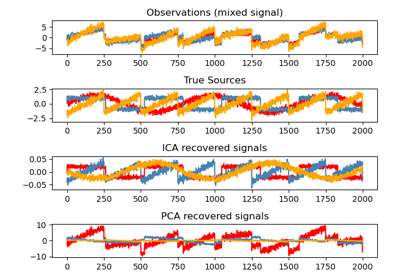
Vergleich von LDA und PCA 2D-Projektion des Iris-Datensatzes

Faktorenanalyse (mit Rotation) zur Visualisierung von Mustern
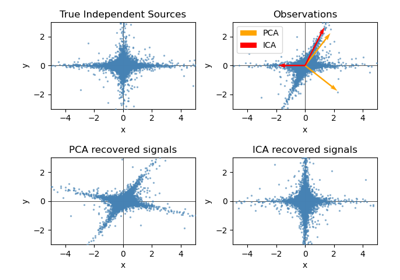

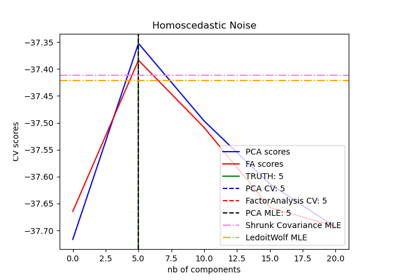
Modellauswahl mit Probabilistischem PCA und Faktorenanalyse (FA)
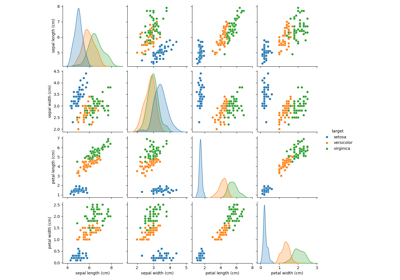
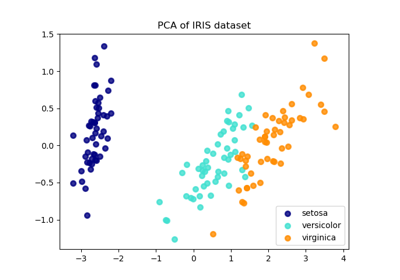
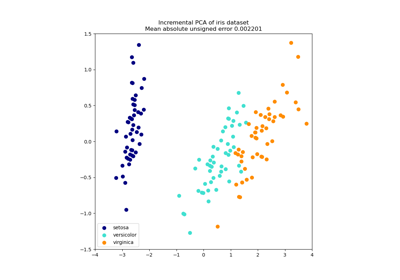
Principal Component Analysis (PCA) auf dem Iris-Datensatz

Sparse Coding mit einem voreingestellten Dictionary
Entwicklung von Estimatorn#
Beispiele zur Entwicklung benutzerdefinierter Estimator.

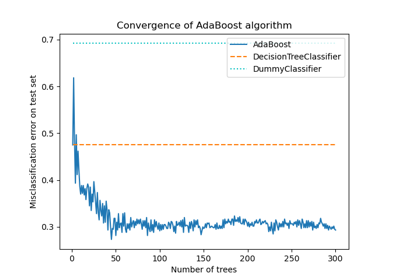
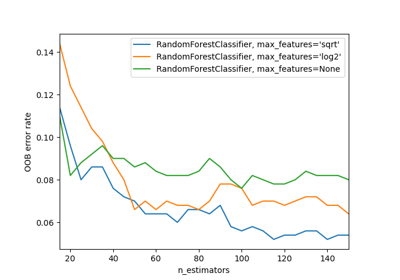
Ensemble-Methoden#
Beispiele zum sklearn.ensemble Modul.

Unterstützung für kategorische Merkmale in Gradient Boosting
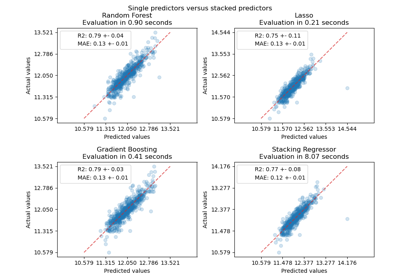

Vergleich von Random Forests und Histogram Gradient Boosting Modellen
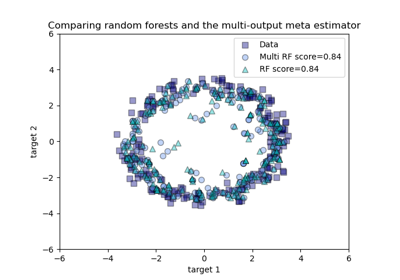
Vergleich von Random Forests und dem Multi-Output Meta-Estimator
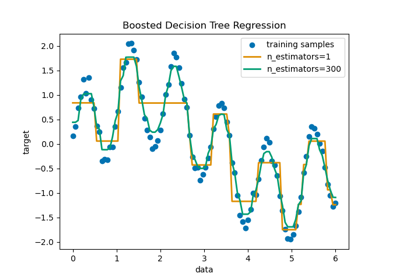
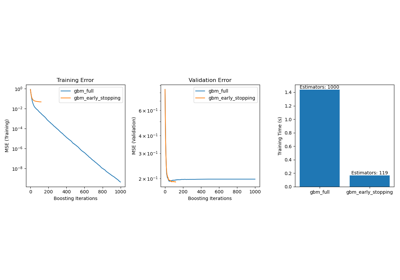
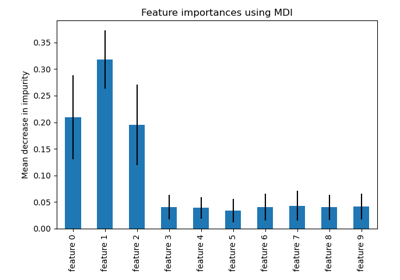
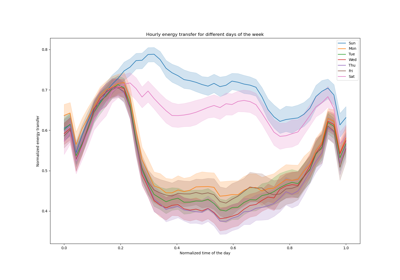
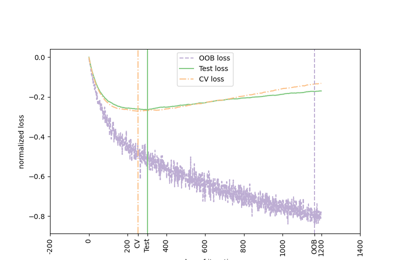
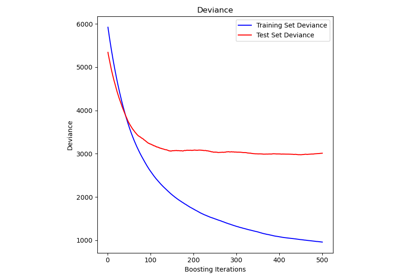
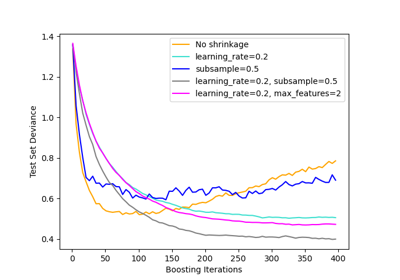
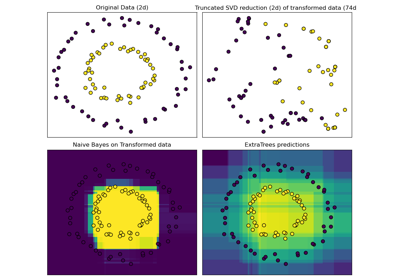
Hashing-Merkmals-Transformation mit Totally Random Trees
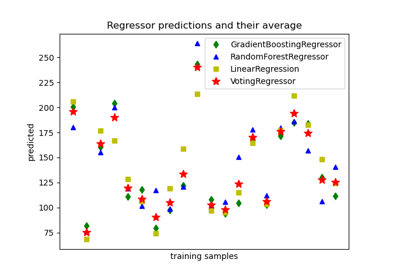
Vorhersagen von einzelnen und abstimmenden Regressionsmodellen plotten
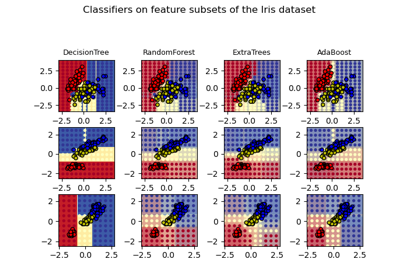
Entscheidungsflächen von Ensembles von Bäumen auf dem Iris-Datensatz plotten
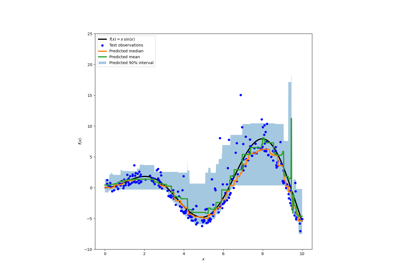
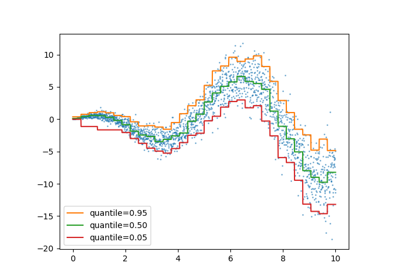
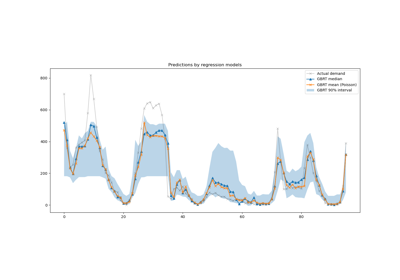
Vorhersageintervalle für Gradient Boosting Regression
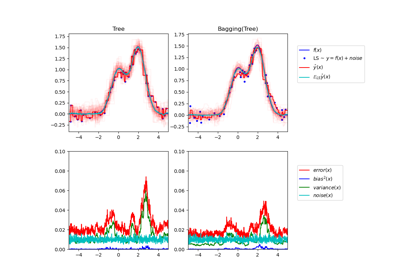
Einzelner Estimator versus Bagging: Bias-Varianz-Zerlegung
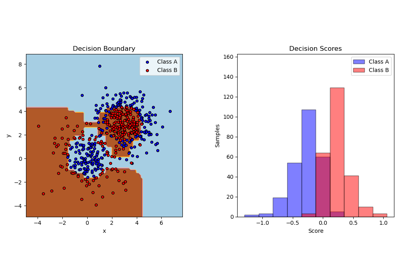
Visualisierung der probabilistischen Vorhersagen eines VotingClassifier
Beispiele basierend auf realen Datensätzen#
Anwendungen auf reale Probleme mit einigen mittelgroßen Datensätzen oder interaktiven Benutzeroberflächen.

Kompression Sensing: Tomographie-Rekonstruktion mit L1-Prior (Lasso)
Gesichtserkennungsbeispiel mit Eigenfaces und SVMs

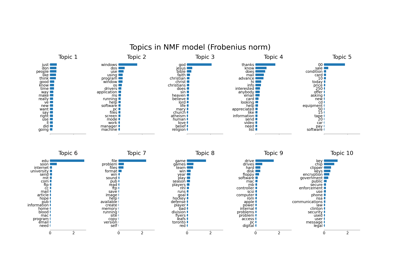
Themenextraktion mit Non-negative Matrix Factorization und Latent Dirichlet Allocation

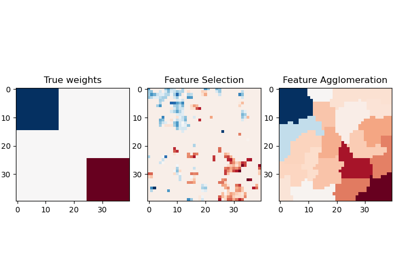
Merkmalsauswahl#
Beispiele zum sklearn.feature_selection Modul.
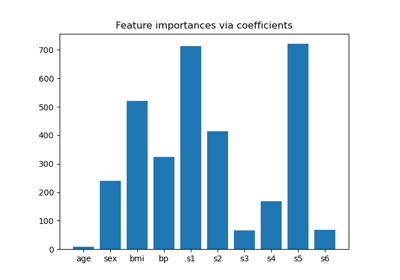

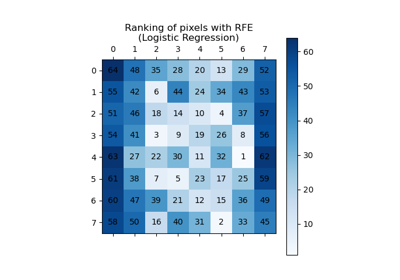
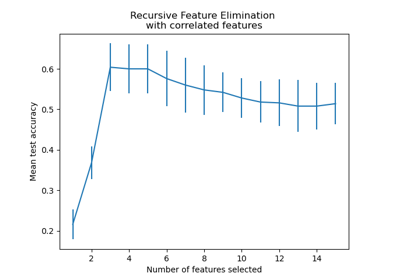
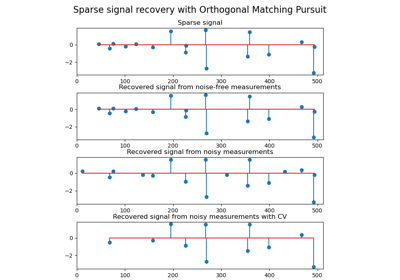
Rekursive Merkmalseliminierung mit Kreuzvalidierung
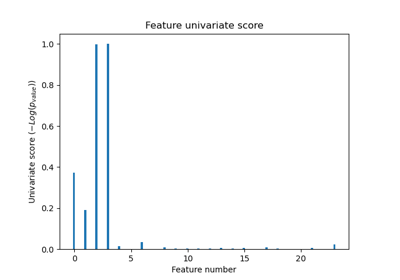
Eingefrorene Estimator#
Beispiele zum sklearn.frozen Modul.

Gaußsche Mischmodelle#
Beispiele zum sklearn.mixture Modul.
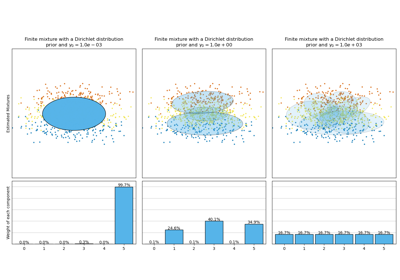
Analyse des Konzentrations-Prior-Typs der Variation im Bayes'schen Gaußschen Gemisch
Gaußsche Prozesse für maschinelles Lernen#
Beispiele zum sklearn.gaussian_process Modul.
Fähigkeit der Gauß-Prozess-Regression (GPR) zur Schätzung des Datenrauschpegels
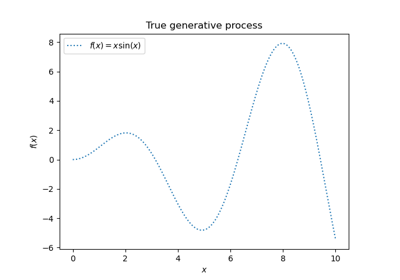
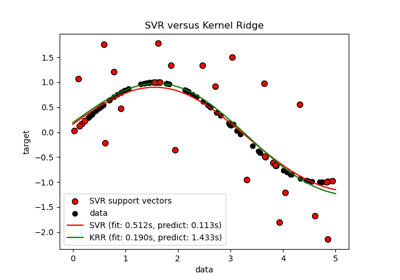
Vergleich von Kernel Ridge und Gauß-Prozess-Regression
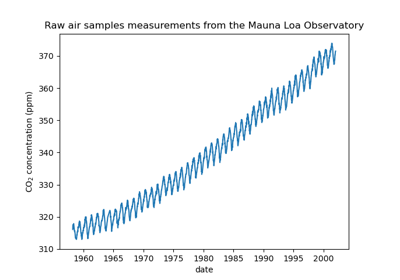
Prognose des CO2-Spiegels im Mona Loa Datensatz mittels Gauß-Prozess-Regression (GPR)
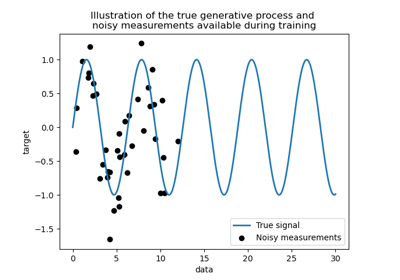
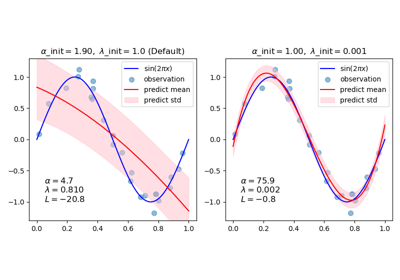
Gauß-Prozesse Regression: grundlegendes Einführungsexempel
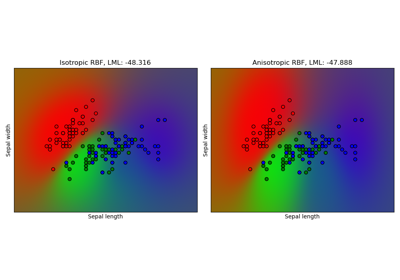
Gauß-Prozess-Klassifikation (GPC) auf dem Iris-Datensatz
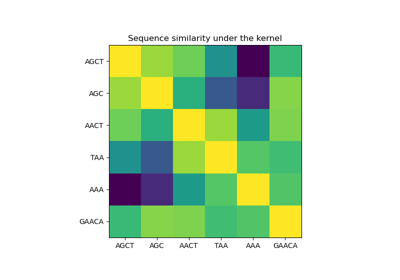
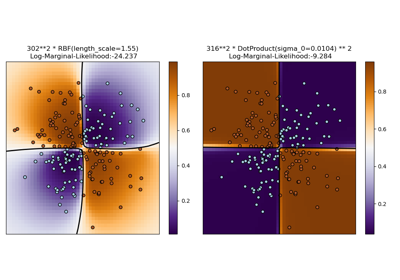
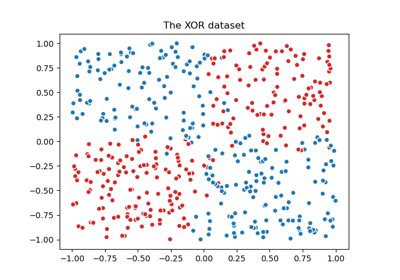
Illustration der Gauß-Prozess-Klassifikation (GPC) auf dem XOR-Datensatz
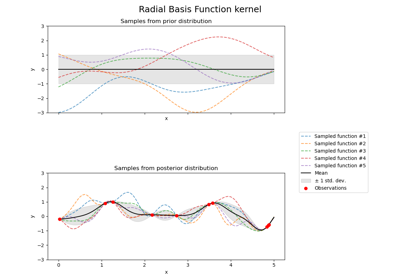
Illustration von Prior und Posterior Gauß-Prozess für verschiedene Kerne
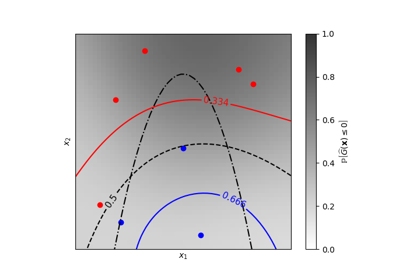
Iso-Wahrscheinlichkeitslinien für Gauß-Prozesse Klassifikation (GPC)
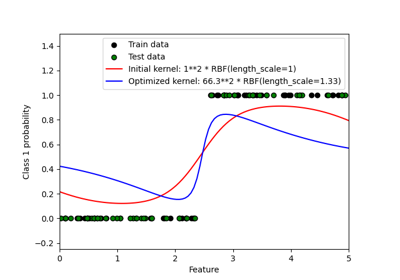
Probabilistische Vorhersagen mit Gauß-Prozess-Klassifikation (GPC)
Generalisierte lineare Modelle#
Beispiele zum sklearn.linear_model Modul.
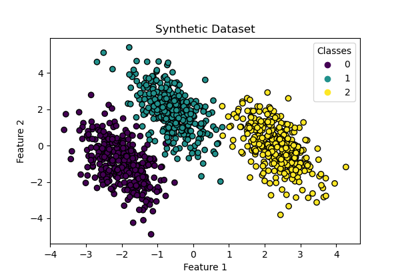
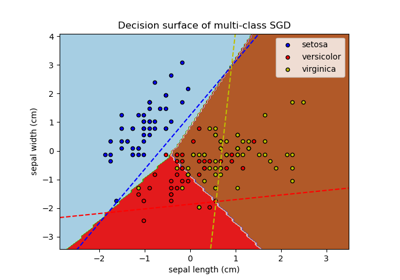
Entscheidungsgrenzen von multinomialer und One-vs-Rest Logistischer Regression

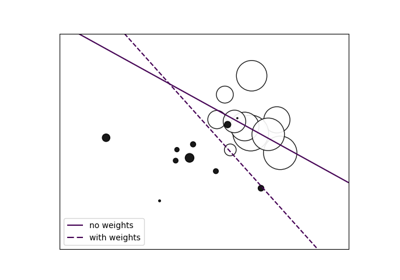
Anpassen eines Elastic Net mit einer voreingestellten Gram-Matrix und gewichteten Stichproben
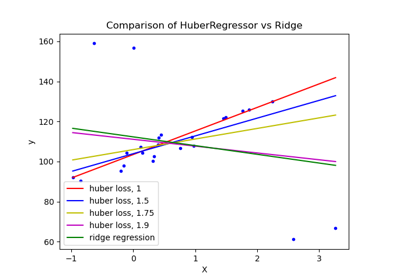
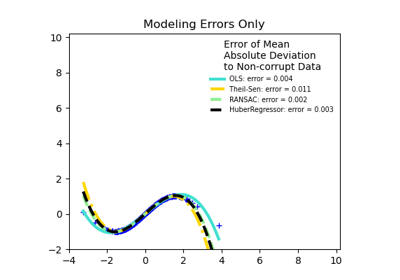
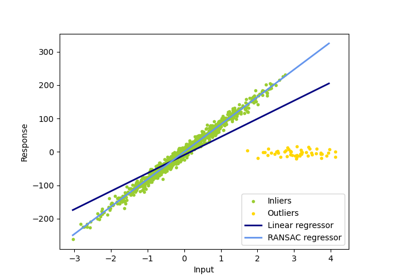
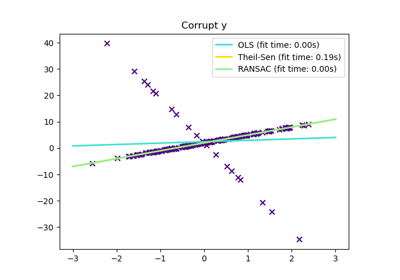
HuberRegressor vs Ridge auf Datensatz mit starken Ausreißern

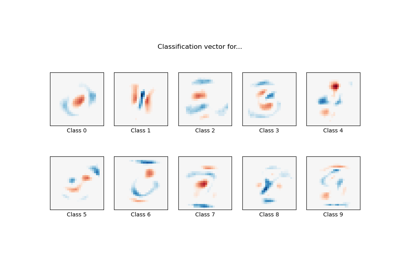
MNIST-Klassifikation mittels multinomialer Logistik + L1
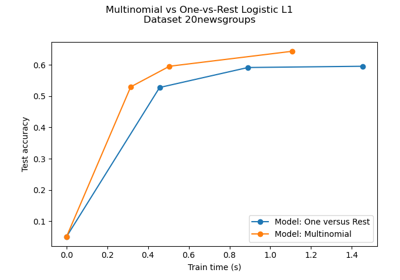
Multiklassen-Sparse-Logistische-Regression auf 20newgroups
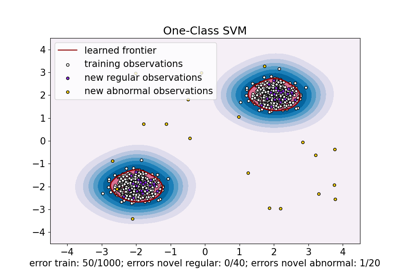
One-Class SVM vs. One-Class SVM mittels Stochastic Gradient Descent
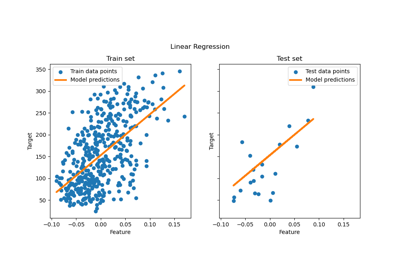
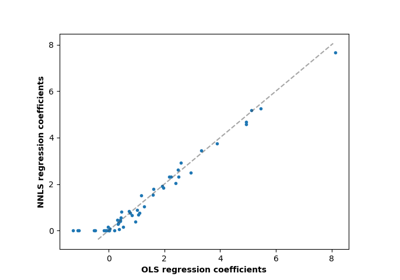
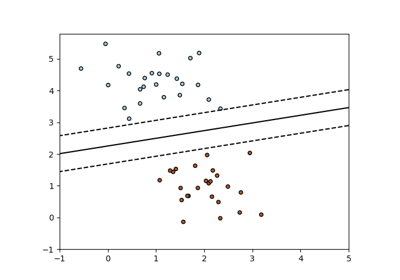
Gewöhnliche kleinste Quadrate und Ridge Regression
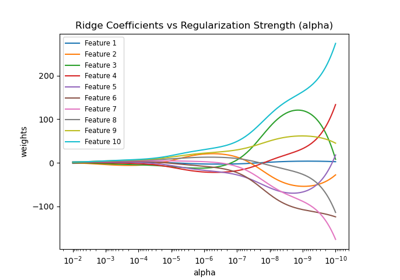
Ridge-Koeffizienten als Funktion der Regularisierung plotten

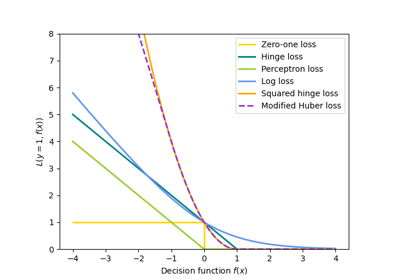
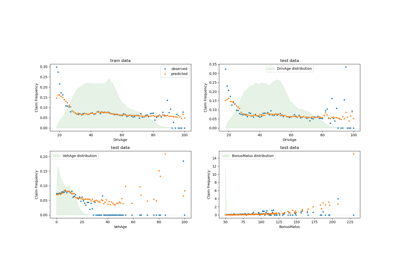
Poisson-Regression und nicht-normale Verlustfunktion
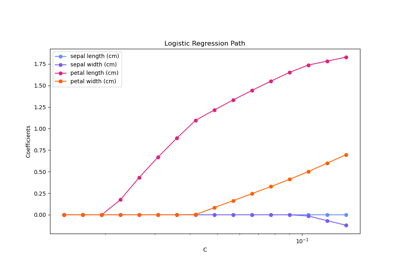
Regularisierungspfad der L1-Logistischen Regression
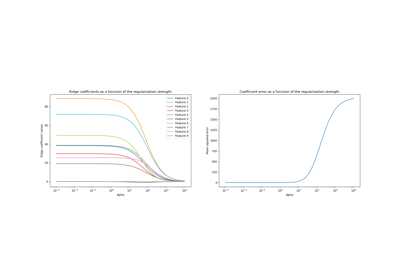
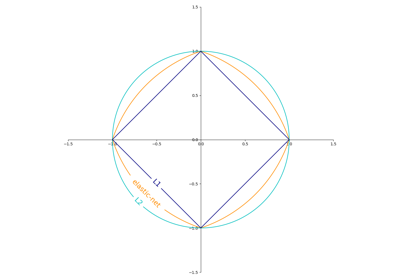
Ridge-Koeffizienten als Funktion der L2-Regularisierung
Inspektion#
Beispiele im Zusammenhang mit dem sklearn.inspection Modul.
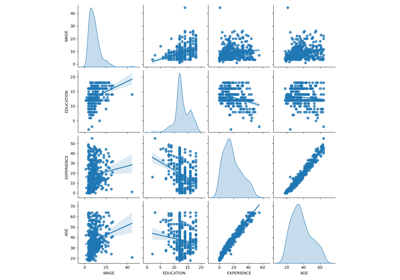
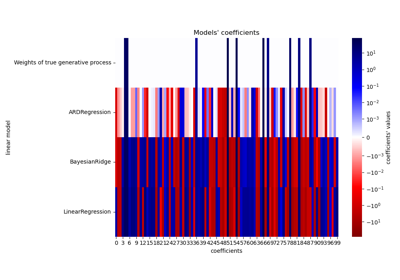
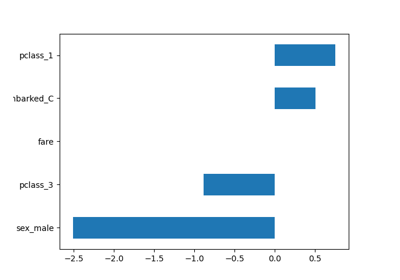
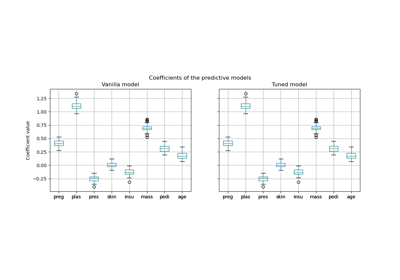
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle
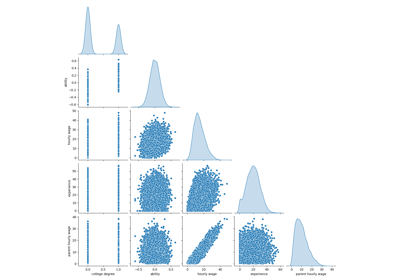
Versagen des maschinellen Lernens bei der Inferenz kausaler Effekte

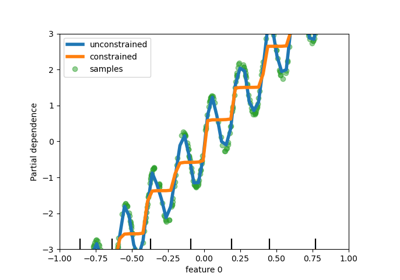
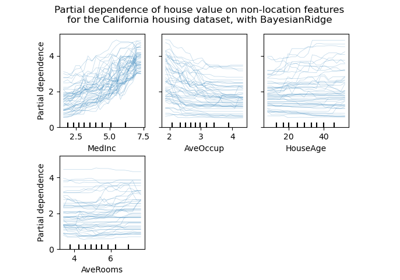
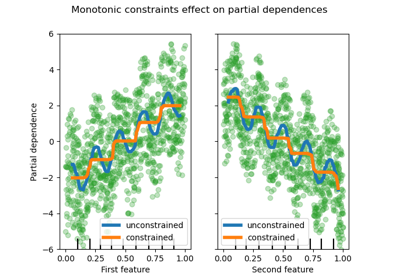
Partial Dependence und Individual Conditional Expectation Plots

Permutations-Wichtigkeit vs. Random Forest Merkmals-Wichtigkeit (MDI)
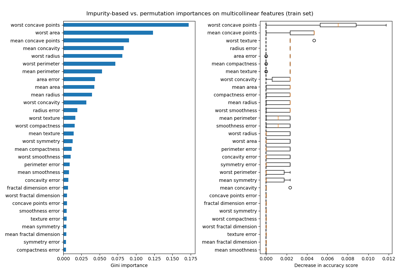
Permutations-Wichtigkeit bei multikollinearen oder korrelierten Merkmalen
Kernel-Approximation#
Beispiele zum sklearn.kernel_approximation Modul.
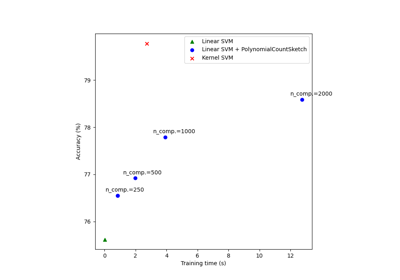
Skalierbares Lernen mit Polynom-Kernel-Approximation
Manifold-Lernen#
Beispiele zum sklearn.manifold Modul.
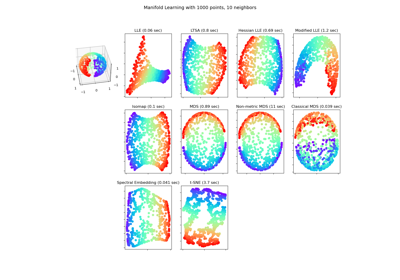
Manifold Learning Methoden auf einer abgetrennten Sphäre

Manifold Learning auf handschriftlichen Ziffern: Locally Linear Embedding, Isomap…
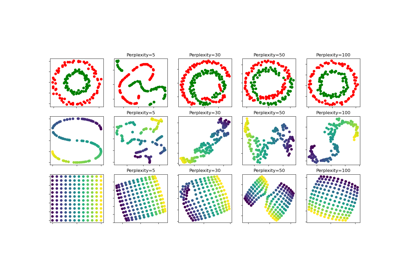
t-SNE: Der Effekt verschiedener Perplexitätswerte auf die Form
Sonstiges#
Sonstige und einführende Beispiele für scikit-learn.

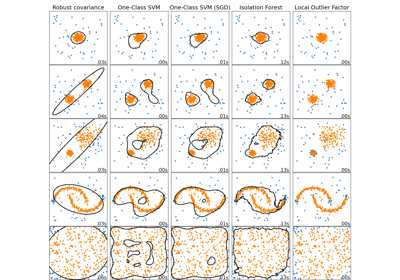
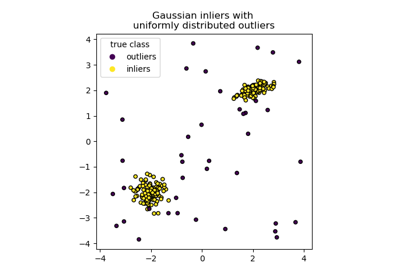
Vergleich von Anomalieerkennungsalgorithmen zur Ausreißererkennung auf Toy-Datensätzen





Gesichtsvervollständigung mit Multi-Output-Schätzern

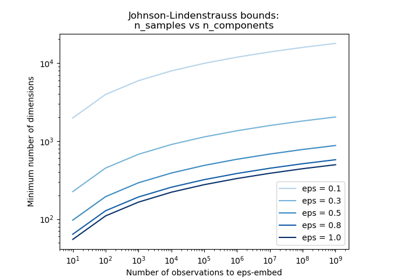
Die Johnson-Lindenstrauss-Schranke für Einbettung mit zufälligen Projektionen
Imputation fehlender Werte#
Beispiele zum sklearn.impute Modul.

Fehlende Werte imputieren, bevor ein Schätzer erstellt wird
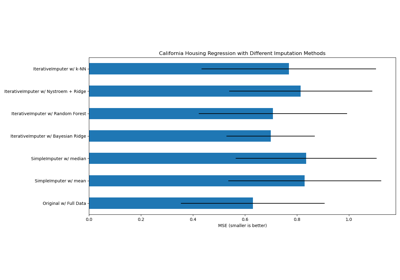
Fehlende Werte mit Varianten von IterativeImputer imputieren
Modellauswahl#
Beispiele im Zusammenhang mit dem sklearn.model_selection Modul.
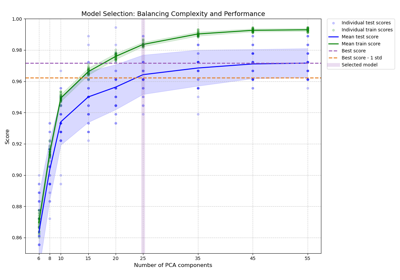
Modellkomplexität und kreuzvalidierter Score ausbalancieren
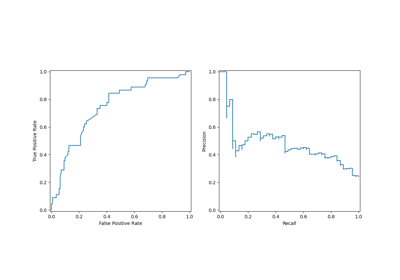
Klassen-Likelihood-Verhältnisse zur Messung der Klassifikationsleistung

Vergleich von zufälliger Suche und Gitter-Suche zur Hyperparameter-Schätzung
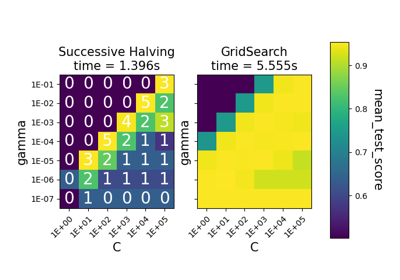
Vergleich zwischen Gitter-Suche und sukzessiver Halbierung

Benutzerdefinierte Refit-Strategie einer Gitter-Suche mit Kreuzvalidierung
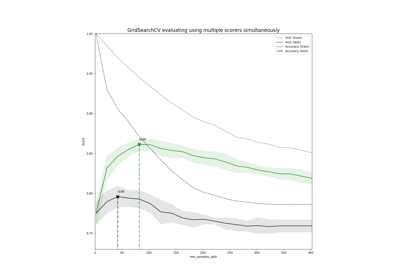
Demonstration von Multi-Metrik-Bewertung auf cross_val_score und GridSearchCV
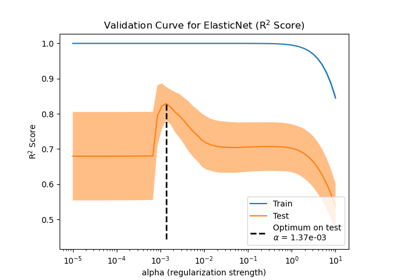
Auswirkung der Modellregularisierung auf Trainings- und Testfehler
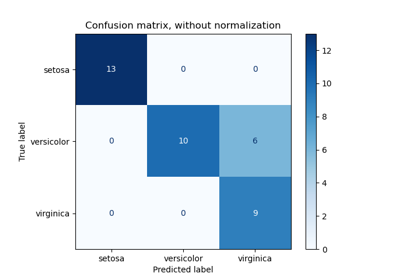
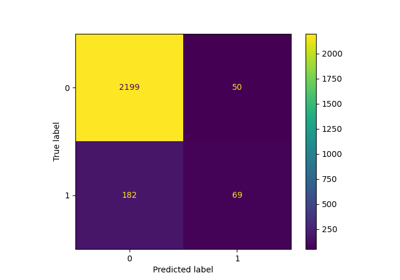
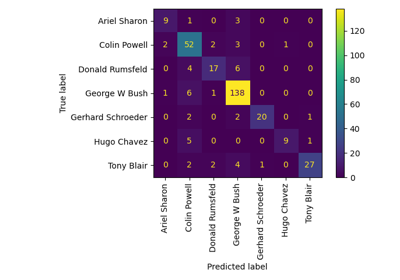
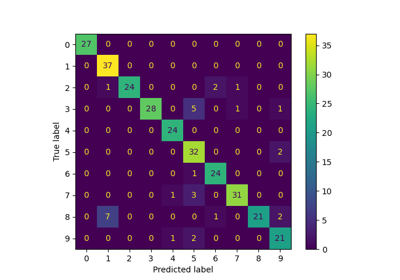
Leistung eines Klassifikators mit Konfusionsmatrix bewerten
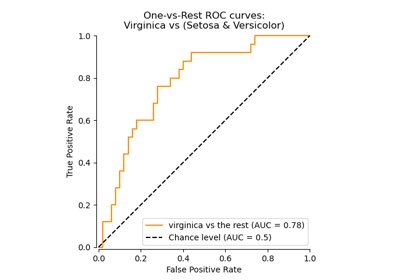
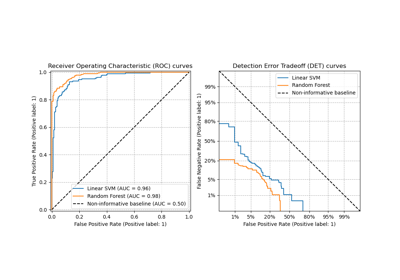
Multiklassen-Receiver Operating Characteristic (ROC)
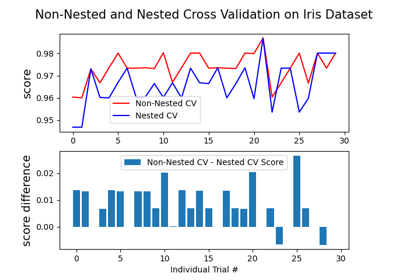
Verschachtelte vs. nicht verschachtelte Kreuzvalidierung
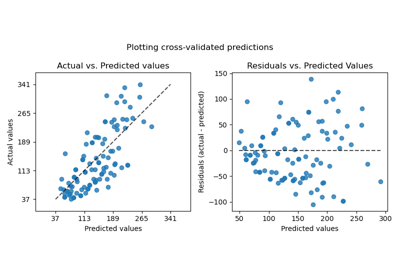
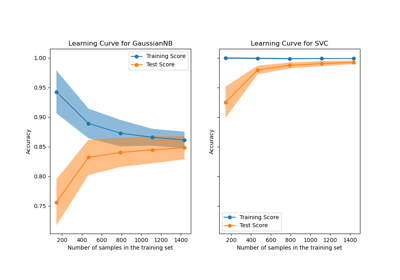
Lernkurven plotten und die Skalierbarkeit von Modellen prüfen
Post-hoc-Anpassung des Cut-off-Punkts der Entscheidungskfunktion
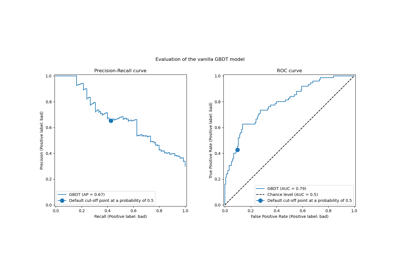
Post-Hoc-Anpassung des Entscheidungsschwellenwerts für kostenempfindliches Lernen
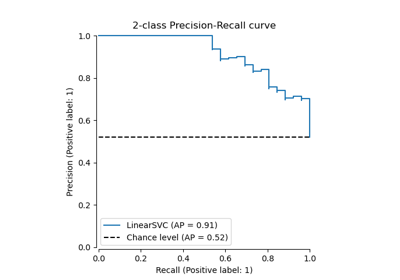
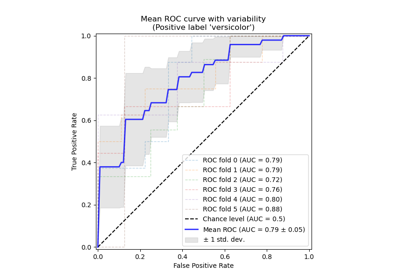
Receiver Operating Characteristic (ROC) mit Kreuzvalidierung

Beispiel-Pipeline für Textmerkmal-Extraktion und -Bewertung
Statistischer Vergleich von Modellen mittels Gitter-Suche
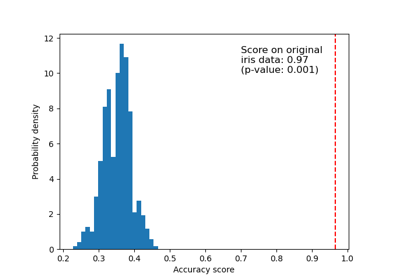
Testen der Signifikanz eines Klassifikations-Scores mit Permutationen
Visualisierung des Kreuzvalidierungsverhaltens in scikit-learn
Multiklassen-Methoden#
Beispiele zum sklearn.multiclass Modul.
Übersicht über Multiklassen-Training Meta-Estimator
Multi-Output-Methoden#
Beispiele zum sklearn.multioutput Modul.
Multilabel-Klassifikation mit einem Klassifikator-Ketten
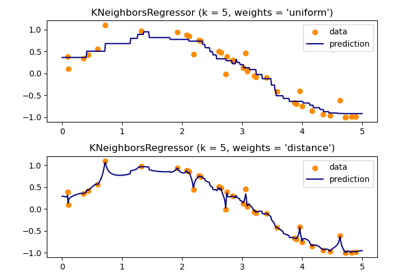
Nächste Nachbarn#
Beispiele zum sklearn.neighbors Modul.

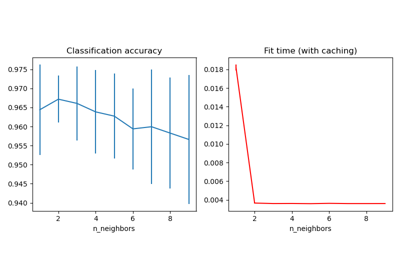
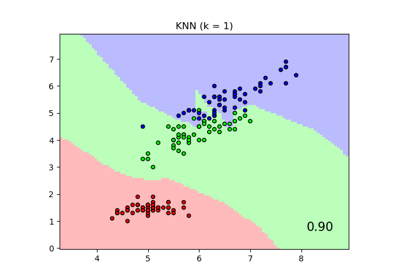
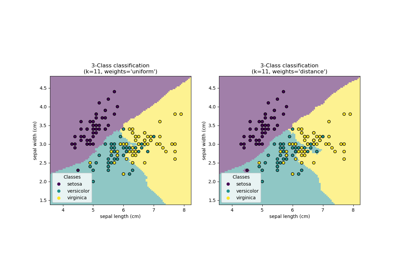
Vergleich von Nächsten Nachbarn mit und ohne Neighborhood Components Analysis
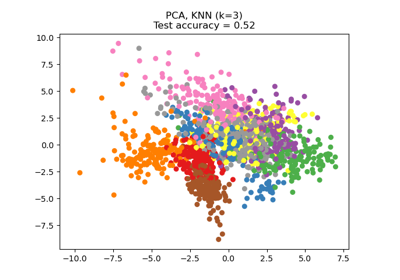
Dimensionsreduktion mit Neighborhood Components Analysis
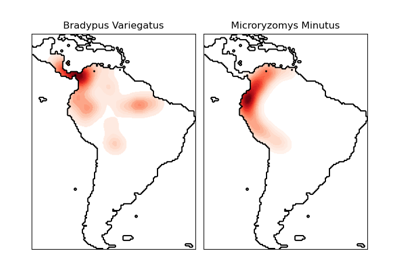
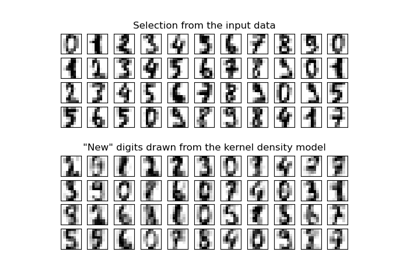

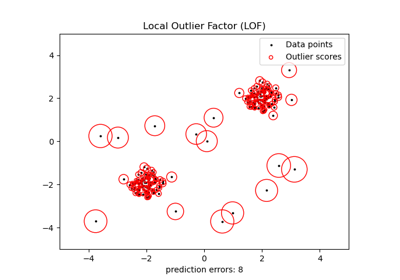
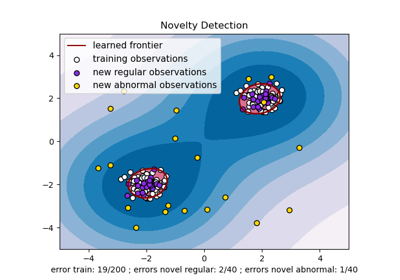
Neuartigkeitserkennung mit Local Outlier Factor (LOF)
Neuronale Netze#
Beispiele zum sklearn.neural_network Modul.
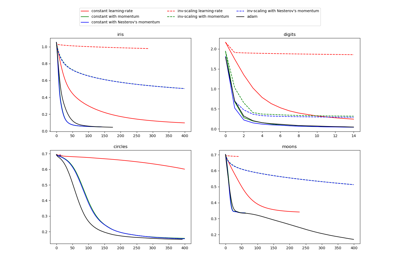
Vergleich von stochastischen Lernstrategien für MLPClassifier

Restricted Boltzmann Machine Merkmale für Ziffernklassifikation
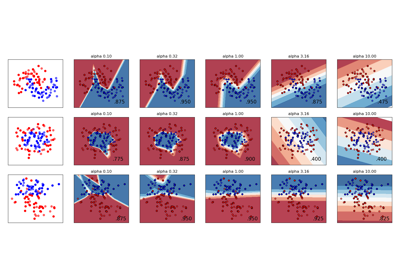
Variierende Regularisierung im Multi-Layer Perceptron

Pipelines und zusammengesetzte Estimator#
Beispiele, wie Transformer und Pipelines aus anderen Estimatorn zusammengesetzt werden. Siehe das Benutzerhandbuch.

Auswirkung der Transformation der Ziele in einem Regressionsmodell
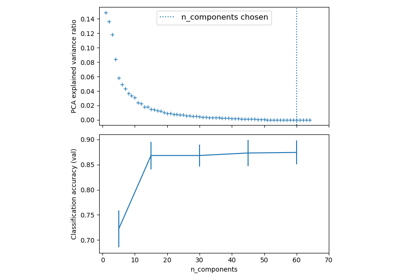
Pipelining: Verkettung einer PCA und einer logistischen Regression
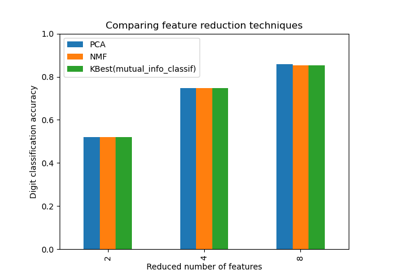
Dimensionsreduktion auswählen mit Pipeline und GridSearchCV
Vorverarbeitung#
Beispiele zum sklearn.preprocessing Modul.

Vergleich der Auswirkungen verschiedener Skalierer auf Daten mit Ausreißern

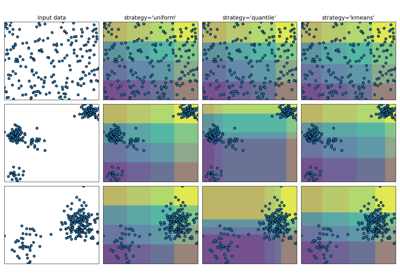
Demonstration der verschiedenen Strategien von KBinsDiscretizer





Verwendung von KBinsDiscretizer zur Diskretisierung kontinuierlicher Merkmale
Semi-überwachte Klassifizierung#
Beispiele zum sklearn.semi_supervised Modul.
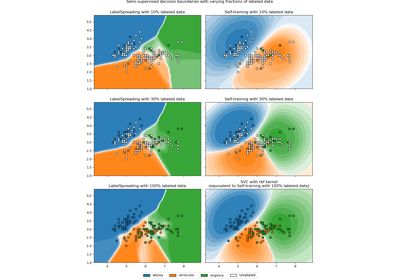
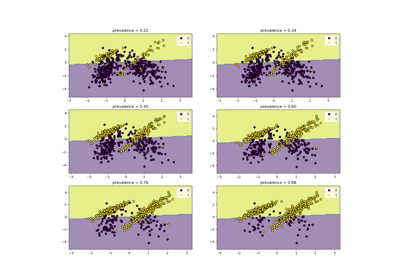
Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz
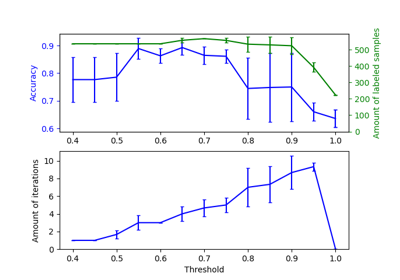
Auswirkung der Änderung des Schwellenwerts für Self-Training
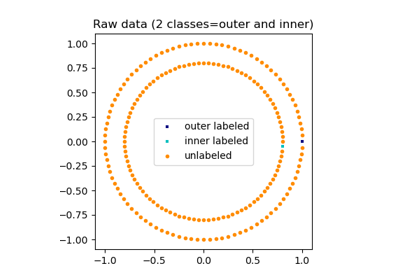
Label Propagation Kreise: Lernen einer komplexen Struktur

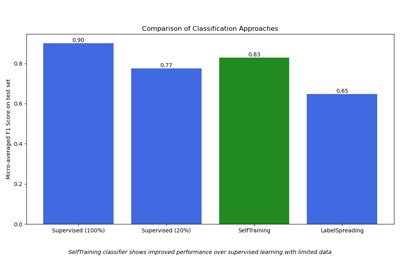
Semi-überwachte Klassifikation auf einem Textdatensatz
Support Vector Machines#
Beispiele zum sklearn.svm Modul.
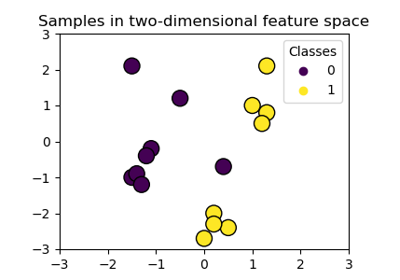
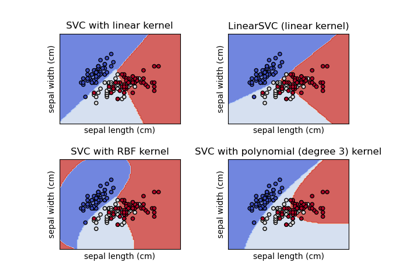
Klassifikationsgrenzen mit verschiedenen SVM-Kernen plotten
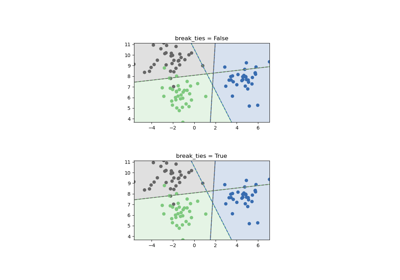
Verschiedene SVM-Klassifikatoren im Iris-Datensatz plotten
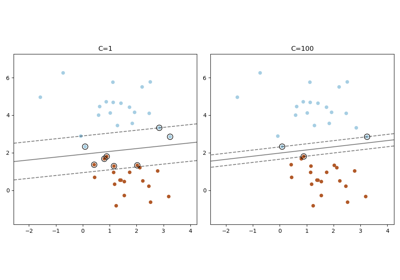
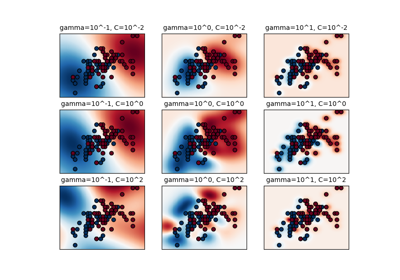
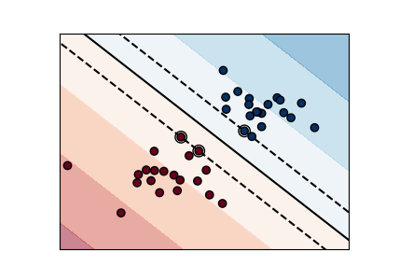

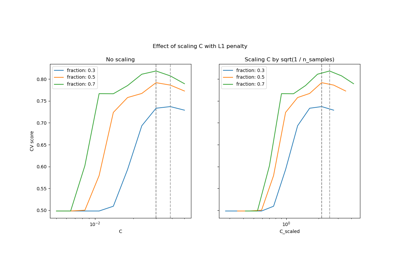
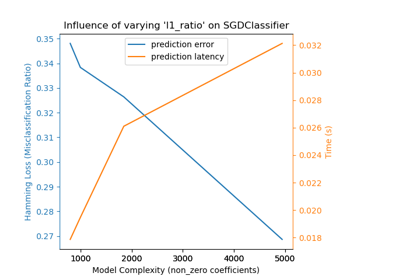
Skalierung des Regularisierungsparameters für SVCs
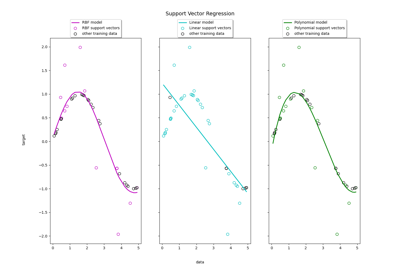
Support Vector Regression (SVR) mit linearen und nicht-linearen Kernen
Arbeiten mit Textdokumenten#
Beispiele zum sklearn.feature_extraction.text Modul.
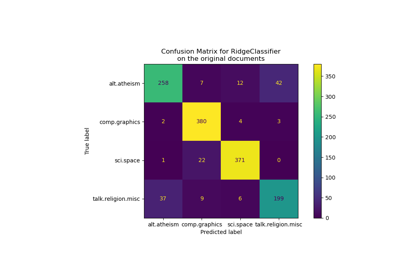
Klassifikation von Textdokumenten mit spärlichen Merkmalen