Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Vergleich des Target Encoders mit anderen Encodern#
Der TargetEncoder verwendet den Wert des Ziels (target), um jedes kategoriale Merkmal zu kodieren. In diesem Beispiel werden wir drei verschiedene Ansätze zur Behandlung kategorialer Merkmale vergleichen: TargetEncoder, OrdinalEncoder, OneHotEncoder und das Verwerfen der Kategorie.
Hinweis
fit(X, y).transform(X) ist nicht gleich fit_transform(X, y), da in fit_transform ein Cross-Fitting-Schema für die Kodierung verwendet wird. Details finden Sie im Benutzerhandbuch.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Laden von Daten von OpenML#
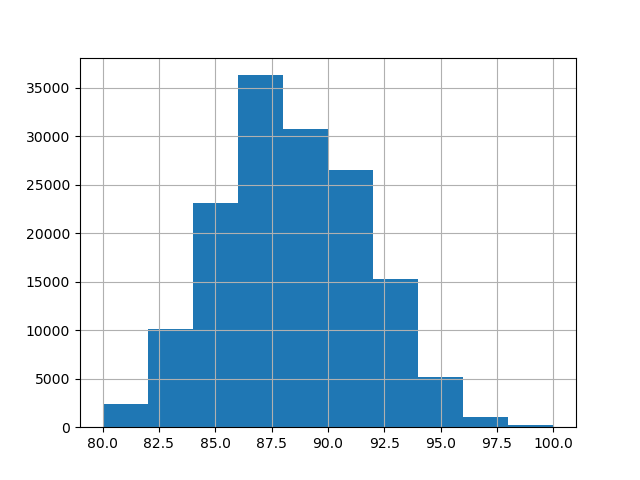
Zuerst laden wir den Weinbewertungsdatensatz, bei dem das Ziel die von einem Rezensenten vergebenen Punkte sind.
from sklearn.datasets import fetch_openml
wine_reviews = fetch_openml(data_id=42074, as_frame=True)
df = wine_reviews.frame
df.head()
Für dieses Beispiel verwenden wir die folgende Untermenge von numerischen und kategorialen Merkmalen in den Daten. Die Zielwerte sind kontinuierliche Werte von 80 bis 100.
numerical_features = ["price"]
categorical_features = [
"country",
"province",
"region_1",
"region_2",
"variety",
"winery",
]
target_name = "points"
X = df[numerical_features + categorical_features]
y = df[target_name]
_ = y.hist()
Trainieren und Bewerten von Pipelines mit verschiedenen Encodern#
In diesem Abschnitt werden wir Pipelines mit HistGradientBoostingRegressor mit verschiedenen Kodierungsstrategien auswerten. Zuerst listen wir die Encoder auf, die wir zur Vorverarbeitung der kategorialen Merkmale verwenden werden.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, TargetEncoder
categorical_preprocessors = [
("drop", "drop"),
("ordinal", OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1)),
(
"one_hot",
OneHotEncoder(handle_unknown="ignore", max_categories=20, sparse_output=False),
),
("target", TargetEncoder(target_type="continuous")),
]
Als Nächstes werten wir die Modelle anhand von Kreuzvalidierung aus und erfassen die Ergebnisse.
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.model_selection import cross_validate
from sklearn.pipeline import make_pipeline
n_cv_folds = 3
max_iter = 20
results = []
def evaluate_model_and_store(name, pipe):
result = cross_validate(
pipe,
X,
y,
scoring="neg_root_mean_squared_error",
cv=n_cv_folds,
return_train_score=True,
)
rmse_test_score = -result["test_score"]
rmse_train_score = -result["train_score"]
results.append(
{
"preprocessor": name,
"rmse_test_mean": rmse_test_score.mean(),
"rmse_test_std": rmse_train_score.std(),
"rmse_train_mean": rmse_train_score.mean(),
"rmse_train_std": rmse_train_score.std(),
}
)
for name, categorical_preprocessor in categorical_preprocessors:
preprocessor = ColumnTransformer(
[
("numerical", "passthrough", numerical_features),
("categorical", categorical_preprocessor, categorical_features),
]
)
pipe = make_pipeline(
preprocessor, HistGradientBoostingRegressor(random_state=0, max_iter=max_iter)
)
evaluate_model_and_store(name, pipe)
Native Unterstützung für kategoriale Merkmale#
In diesem Abschnitt bauen und bewerten wir eine Pipeline, die die native Unterstützung für kategoriale Merkmale in HistGradientBoostingRegressor verwendet, die nur bis zu 255 eindeutige Kategorien unterstützt. In unserem Datensatz haben die meisten kategorialen Merkmale mehr als 255 eindeutige Kategorien.
n_unique_categories = df[categorical_features].nunique().sort_values(ascending=False)
n_unique_categories
winery 14810
region_1 1236
variety 632
province 455
country 48
region_2 18
dtype: int64
Um die oben genannte Einschränkung zu umgehen, gruppieren wir die kategorialen Merkmale in Merkmale mit niedriger Kardinalität und Merkmale mit hoher Kardinalität. Die Merkmale mit hoher Kardinalität werden mit Target Encoding kodiert, und die Merkmale mit niedriger Kardinalität verwenden die native kategoriale Unterstützung im Gradient Boosting.
high_cardinality_features = n_unique_categories[n_unique_categories > 255].index
low_cardinality_features = n_unique_categories[n_unique_categories <= 255].index
mixed_encoded_preprocessor = ColumnTransformer(
[
("numerical", "passthrough", numerical_features),
(
"high_cardinality",
TargetEncoder(target_type="continuous"),
high_cardinality_features,
),
(
"low_cardinality",
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1),
low_cardinality_features,
),
],
verbose_feature_names_out=False,
)
# The output of the of the preprocessor must be set to pandas so the
# gradient boosting model can detect the low cardinality features.
mixed_encoded_preprocessor.set_output(transform="pandas")
mixed_pipe = make_pipeline(
mixed_encoded_preprocessor,
HistGradientBoostingRegressor(
random_state=0, max_iter=max_iter, categorical_features=low_cardinality_features
),
)
mixed_pipe
Schließlich werten wir die Pipeline anhand von Kreuzvalidierung aus und erfassen die Ergebnisse.
evaluate_model_and_store("mixed_target", mixed_pipe)
Darstellung der Ergebnisse#
In diesem Abschnitt zeigen wir die Ergebnisse, indem wir die Test- und Trainingsergebnisse plotten.
import matplotlib.pyplot as plt
import pandas as pd
results_df = (
pd.DataFrame(results).set_index("preprocessor").sort_values("rmse_test_mean")
)
fig, (ax1, ax2) = plt.subplots(
1, 2, figsize=(12, 8), sharey=True, constrained_layout=True
)
xticks = range(len(results_df))
name_to_color = dict(
zip((r["preprocessor"] for r in results), ["C0", "C1", "C2", "C3", "C4"])
)
for subset, ax in zip(["test", "train"], [ax1, ax2]):
mean, std = f"rmse_{subset}_mean", f"rmse_{subset}_std"
data = results_df[[mean, std]].sort_values(mean)
ax.bar(
x=xticks,
height=data[mean],
yerr=data[std],
width=0.9,
color=[name_to_color[name] for name in data.index],
)
ax.set(
title=f"RMSE ({subset.title()})",
xlabel="Encoding Scheme",
xticks=xticks,
xticklabels=data.index,
)
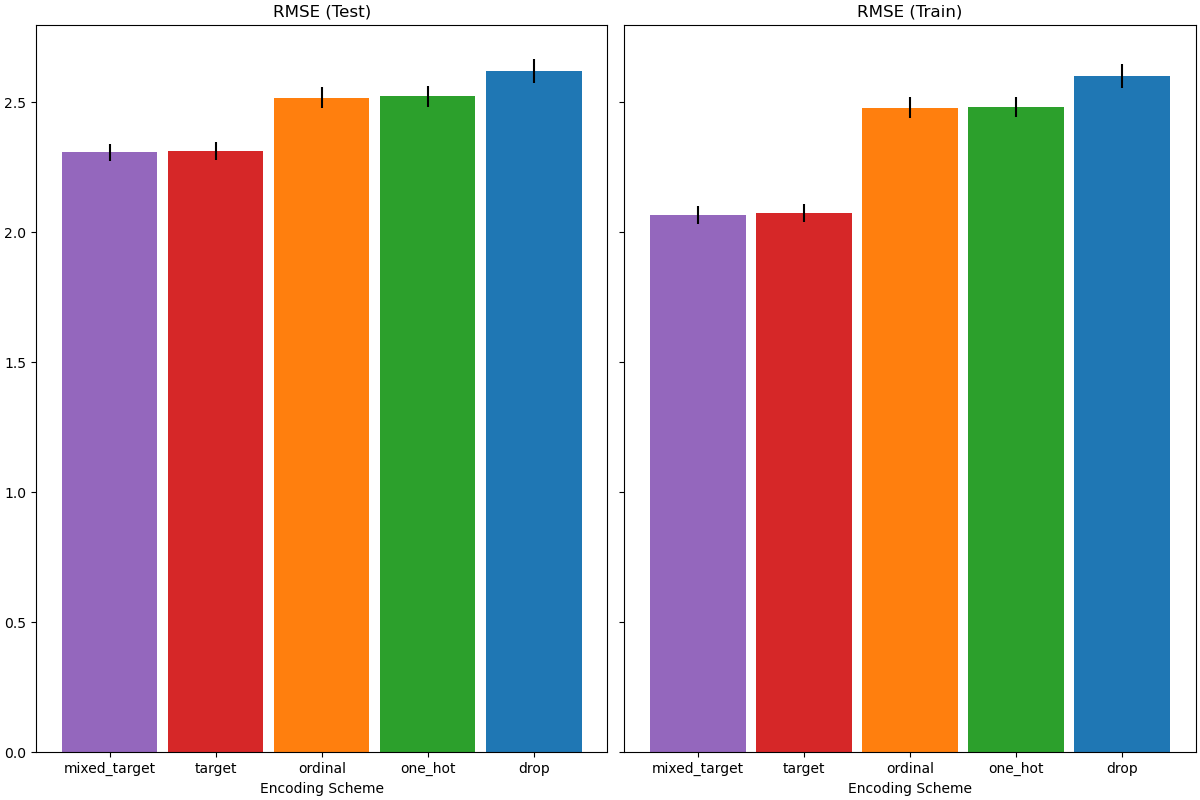
Bei der Bewertung der prädiktiven Leistung auf dem Testdatensatz schneidet das Verwerfen der Kategorien am schlechtesten ab, und die Target Encoder schneiden am besten ab. Dies lässt sich wie folgt erklären:
Das Verwerfen der kategorialen Merkmale macht die Pipeline weniger ausdrucksstark und führt zu Underfitting;
Aufgrund der hohen Kardinalität und zur Reduzierung der Trainingszeit verwendet das One-Hot-Encoding-Schema
max_categories=20, was verhindert, dass sich die Merkmale zu stark erweitern, was zu Underfitting führen kann.Wenn wir
max_categories=20nicht gesetzt hätten, hätte das One-Hot-Encoding-Schema wahrscheinlich zu Überanpassung geführt, da die Anzahl der Merkmale mit seltenen Kategorien explodiert, die zufällig mit dem Ziel korrelieren (nur im Trainingsdatensatz);Das Ordinal-Encoding erzwingt eine willkürliche Reihenfolge der Merkmale, die dann vom
HistGradientBoostingRegressorals numerische Werte behandelt werden. Da dieses Modell numerische Merkmale in 256 Bins pro Merkmal gruppiert, können viele nicht zusammenhängende Kategorien zusammen gruppiert werden, und als Ergebnis kann die gesamte Pipeline underfitten;Bei Verwendung des Target Encoders geschieht dasselbe Binning, aber da die kodierten Werte statistisch nach ihrer marginalen Assoziation mit der Zielvariablen geordnet sind, ist das Binning, das vom
HistGradientBoostingRegressorverwendet wird, sinnvoll und führt zu guten Ergebnissen: Die Kombination aus geglättetem Target Encoding und Binning wirkt als gute regularisierende Strategie gegen Überanpassung, ohne die Ausdrucksstärke der Pipeline zu sehr einzuschränken.
Gesamtlaufzeit des Skripts: (0 Minuten 21,022 Sekunden)
Verwandte Beispiele

Unterstützung für kategorische Merkmale in Gradient Boosting