Hinweis
Zum Ende gehen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Frühes Stoppen des stochastischen Gradientenabstiegs#
Der stochastische Gradientenabstieg ist eine Optimierungstechnik, die eine Verlustfunktion auf stochastische Weise minimiert, indem sie einen Gradientenabstiegsschritt Stichprobe für Stichprobe durchführt. Insbesondere ist dies eine sehr effiziente Methode zur Anpassung von linearen Modellen.
Als stochastische Methode nimmt die Verlustfunktion nicht notwendigerweise bei jeder Iteration ab, und die Konvergenz ist nur im Erwartungswert garantiert. Aus diesem Grund kann die Überwachung der Konvergenz der Verlustfunktion schwierig sein.
Ein anderer Ansatz ist die Überwachung der Konvergenz anhand eines Validierungs-Scores. In diesem Fall wird die Eingabedatensatz in einen Trainingsdatensatz und einen Validierungsdatensatz aufgeteilt. Das Modell wird dann auf dem Trainingsdatensatz angepasst, und das Stoppkriterium basiert auf dem Vorhersagescore, der auf dem Validierungsdatensatz berechnet wird. Dies ermöglicht es uns, die geringste Anzahl von Iterationen zu finden, die ausreicht, um ein Modell zu erstellen, das gut auf ungesehene Daten generalisiert und die Wahrscheinlichkeit einer Überanpassung an die Trainingsdaten verringert.
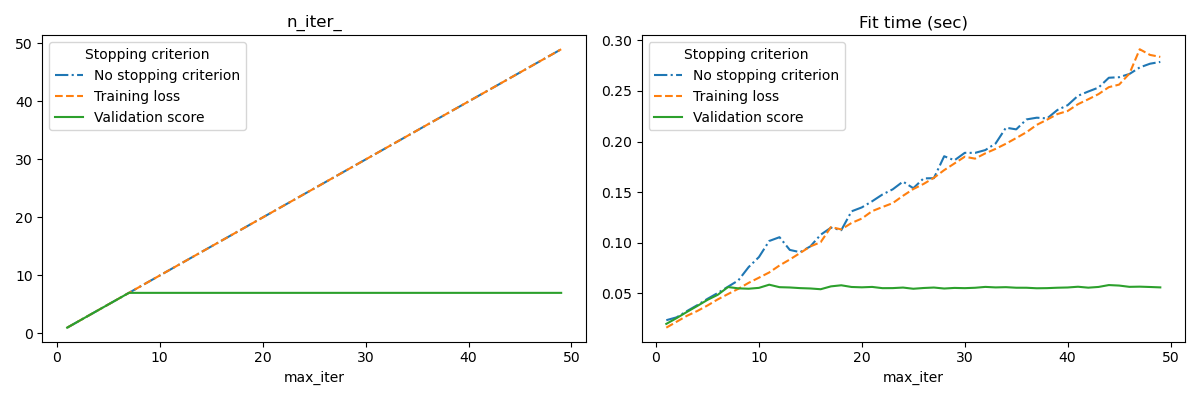
Diese Strategie des frühen Stoppens wird aktiviert, wenn early_stopping=True ist; andernfalls verwendet das Stoppkriterium nur den Trainingsverlust auf dem gesamten Eingabedatensatz. Um die Strategie des frühen Stoppens besser zu kontrollieren, können wir einen Parameter validation_fraction angeben, der den Anteil des Eingabedatensatzes festlegt, den wir zur Berechnung des Validierungs-Scores zurückhalten. Die Optimierung wird fortgesetzt, bis sich der Validierungs-Score in den letzten n_iter_no_change Iterationen nicht um mindestens tol verbessert hat. Die tatsächliche Anzahl der Iterationen ist unter dem Attribut n_iter_ verfügbar.
Dieses Beispiel veranschaulicht, wie frühes Stoppen im Modell SGDClassifier verwendet werden kann, um eine fast gleiche Genauigkeit wie bei einem Modell ohne frühes Stoppen zu erzielen. Dies kann die Trainingszeit erheblich reduzieren. Beachten Sie, dass die Scores zwischen den Stoppkriterien selbst in frühen Iterationen abweichen, da mit dem Validierungs-Stoppkriterium ein Teil der Trainingsdaten zurückgehalten wird.

No stopping criterion: .................................................
Training loss: .................................................
Validation score: .................................................
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import sys
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import linear_model
from sklearn.datasets import fetch_openml
from sklearn.exceptions import ConvergenceWarning
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.utils._testing import ignore_warnings
def load_mnist(n_samples=None, class_0="0", class_1="8"):
"""Load MNIST, select two classes, shuffle and return only n_samples."""
# Load data from http://openml.org/d/554
mnist = fetch_openml("mnist_784", version=1, as_frame=False)
# take only two classes for binary classification
mask = np.logical_or(mnist.target == class_0, mnist.target == class_1)
X, y = shuffle(mnist.data[mask], mnist.target[mask], random_state=42)
if n_samples is not None:
X, y = X[:n_samples], y[:n_samples]
return X, y
@ignore_warnings(category=ConvergenceWarning)
def fit_and_score(estimator, max_iter, X_train, X_test, y_train, y_test):
"""Fit the estimator on the train set and score it on both sets"""
estimator.set_params(max_iter=max_iter)
estimator.set_params(random_state=0)
start = time.time()
estimator.fit(X_train, y_train)
fit_time = time.time() - start
n_iter = estimator.n_iter_
train_score = estimator.score(X_train, y_train)
test_score = estimator.score(X_test, y_test)
return fit_time, n_iter, train_score, test_score
# Define the estimators to compare
estimator_dict = {
"No stopping criterion": linear_model.SGDClassifier(n_iter_no_change=3),
"Training loss": linear_model.SGDClassifier(
early_stopping=False, n_iter_no_change=3, tol=0.1
),
"Validation score": linear_model.SGDClassifier(
early_stopping=True, n_iter_no_change=3, tol=0.0001, validation_fraction=0.2
),
}
# Load the dataset
X, y = load_mnist(n_samples=10000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
results = []
for estimator_name, estimator in estimator_dict.items():
print(estimator_name + ": ", end="")
for max_iter in range(1, 50):
print(".", end="")
sys.stdout.flush()
fit_time, n_iter, train_score, test_score = fit_and_score(
estimator, max_iter, X_train, X_test, y_train, y_test
)
results.append(
(estimator_name, max_iter, fit_time, n_iter, train_score, test_score)
)
print("")
# Transform the results in a pandas dataframe for easy plotting
columns = [
"Stopping criterion",
"max_iter",
"Fit time (sec)",
"n_iter_",
"Train score",
"Test score",
]
results_df = pd.DataFrame(results, columns=columns)
# Define what to plot
lines = "Stopping criterion"
x_axis = "max_iter"
styles = ["-.", "--", "-"]
# First plot: train and test scores
fig, axes = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(12, 4))
for ax, y_axis in zip(axes, ["Train score", "Test score"]):
for style, (criterion, group_df) in zip(styles, results_df.groupby(lines)):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax, style=style)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
# Second plot: n_iter and fit time
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 4))
for ax, y_axis in zip(axes, ["n_iter_", "Fit time (sec)"]):
for style, (criterion, group_df) in zip(styles, results_df.groupby(lines)):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax, style=style)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 28,933 Sekunden)
Verwandte Beispiele