Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle#
In linearen Modellen wird der Zielwert als lineare Kombination der Merkmale modelliert (siehe die Sektion Lineare Modelle im Benutzerhandbuch für eine Beschreibung einer Reihe von in scikit-learn verfügbaren linearen Modellen). Koeffizienten in multiplen linearen Modellen stellen die Beziehung zwischen dem gegebenen Merkmal, \(X_i\), und dem Ziel, \(y\), dar, unter der Annahme, dass alle anderen Merkmale konstant bleiben (bedingte Abhängigkeit). Dies unterscheidet sich vom Plotten von \(X_i\) gegen \(y\) und dem Anpassen einer linearen Beziehung: In diesem Fall werden alle möglichen Werte der anderen Merkmale bei der Schätzung berücksichtigt (marginale Abhängigkeit).
Dieses Beispiel gibt einige Hinweise zur Interpretation von Koeffizienten in linearen Modellen und weist auf Probleme hin, die auftreten, wenn entweder das lineare Modell zur Beschreibung des Datensatzes nicht geeignet ist oder wenn Merkmale korreliert sind.
Hinweis
Beachten Sie, dass die Merkmale \(X\) und das Ergebnis \(y\) im Allgemeinen das Ergebnis eines Datengenerierungsprozesses sind, der uns unbekannt ist. Machine-Learning-Modelle werden trainiert, um die unbeobachtete mathematische Funktion, die \(X\) mit \(y\) verbindet, aus Stichprobendaten zu approximieren. Daher muss jede Interpretation eines Modells nicht unbedingt auf den wahren Datengenerierungsprozess verallgemeinert werden. Dies gilt insbesondere, wenn das Modell von schlechter Qualität ist oder wenn die Stichprobendaten nicht repräsentativ für die Population sind.
Wir verwenden Daten aus der „Current Population Survey“ von 1985, um den Lohn (wage) als Funktion verschiedener Merkmale wie Erfahrung (experience), Alter (age) oder Bildung (education) vorherzusagen.
# Authors: The scikit-learn developers# SPDX-License-Identifier: BSD-3-Clause
Anschließend identifizieren wir die Merkmale X und das Ziel y: Die Spalte WAGE ist unsere Zielvariable (d. h. die Variable, die wir vorhersagen wollen).
Beachten Sie, dass der Datensatz kategoriale und numerische Variablen enthält. Wir müssen dies bei der anschließenden Vorverarbeitung des Datensatzes berücksichtigen.
X.head()
BILDUNG
SÜDEN
GESCHLECHT
ERFAHRUNG
GEWERKSCHAFT
ALTER
RASSE
BERUF
SEKTOR
VERHEIRATET
0
8
no
weiblich
21
nicht Mitglied
35
Hispanic
Andere
Fertigung
Verheiratet
1
9
no
weiblich
42
nicht Mitglied
57
Weiß
Andere
Fertigung
Verheiratet
2
12
no
männlich
1
nicht Mitglied
19
Weiß
Andere
Fertigung
Unverheiratet
3
12
no
männlich
4
nicht Mitglied
22
Weiß
Andere
Andere
Unverheiratet
4
12
no
männlich
17
nicht Mitglied
35
Weiß
Andere
Andere
Verheiratet
Unser Ziel für die Vorhersage: der Lohn. Löhne werden als Gleitkommazahl in Dollar pro Stunde beschrieben.
Wir teilen die Stichprobe in einen Trainings- und einen Testdatensatz auf. Nur der Trainingsdatensatz wird in der folgenden explorativen Analyse verwendet. Dies ist eine Möglichkeit, eine reale Situation zu emulieren, in der Vorhersagen für ein unbekanntes Ziel durchgeführt werden und wir nicht möchten, dass unsere Analyse und Entscheidungen durch unser Wissen über die Testdaten verzerrt werden.
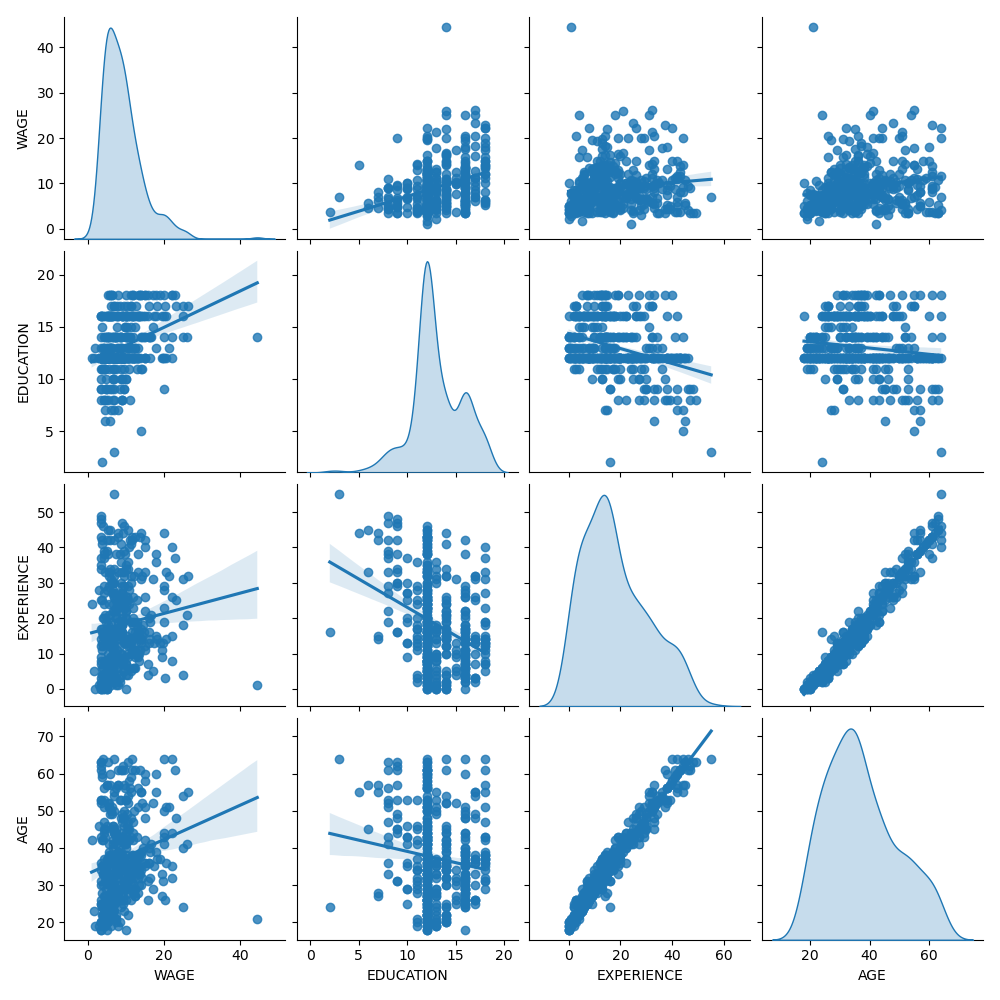
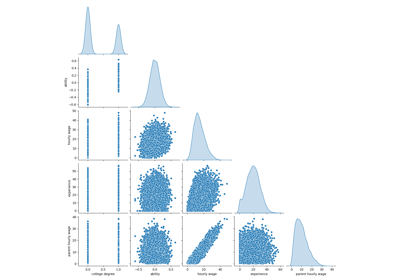
Zuerst erhalten wir einige Einblicke, indem wir uns die Verteilungen der Variablen und die paarweisen Beziehungen zwischen ihnen ansehen. Es werden nur numerische Variablen verwendet. In der folgenden Grafik stellt jeder Punkt eine Stichprobe dar.
Eine genauere Betrachtung der WAGE-Verteilung zeigt, dass sie einen langen Schwanz hat. Aus diesem Grund sollten wir ihren Logarithmus nehmen, um sie annähernd in eine Normalverteilung zu überführen (lineare Modelle wie Ridge oder Lasso funktionieren am besten bei einer Normalverteilung des Fehlers).
Das WAGE steigt mit steigender BILDUNG. Beachten Sie, dass die hier dargestellte Abhängigkeit zwischen WAGE und BILDUNG eine marginale Abhängigkeit ist, d. h. sie beschreibt das Verhalten einer bestimmten Variablen, ohne die anderen festzuhalten.
Außerdem sind ERFAHRUNG und ALTER stark linear korreliert.
Wie bereits gesehen, enthält der Datensatz Spalten mit unterschiedlichen Datentypen und wir müssen für jeden Datentyp eine spezifische Vorverarbeitung anwenden. Insbesondere kategoriale Variablen können nicht in lineare Modelle einbezogen werden, wenn sie nicht zuerst als ganze Zahlen kodiert sind. Um zu vermeiden, dass kategoriale Merkmale als geordnete Werte behandelt werden, müssen wir sie one-hot-kodieren. Unser Vorverarbeiter wird
die kategorialen Spalten one-hot-kodieren (d. h. eine Spalte pro Kategorie generieren), nur für nicht-binäre kategoriale Variablen;
als erster Ansatz (wir werden später sehen, wie sich die Normalisierung numerischer Werte auf unsere Diskussion auswirkt), die numerischen Werte unverändert lassen.
fromsklearn.composeimportmake_column_transformerfromsklearn.preprocessingimportOneHotEncodercategorical_columns=["RACE","OCCUPATION","SECTOR","MARR","UNION","SEX","SOUTH"]numerical_columns=["EDUCATION","EXPERIENCE","AGE"]preprocessor=make_column_transformer((OneHotEncoder(drop="if_binary"),categorical_columns),remainder="passthrough",verbose_feature_names_out=False,# avoid to prepend the preprocessor names)
Wir verwenden einen Ridge-Regressoren mit einer sehr geringen Regularisierung, um den Logarithmus des Lohns zu modellieren.
In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook. Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
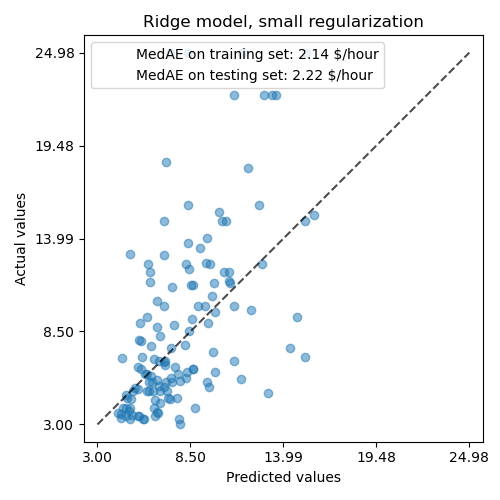
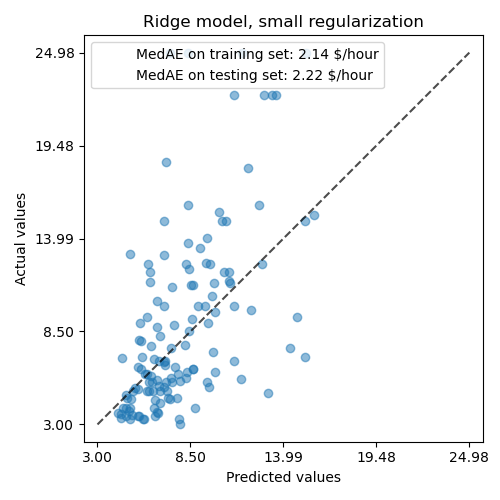
Dann prüfen wir die Leistung des berechneten Modells, indem wir seine Vorhersagen gegen die tatsächlichen Werte auf dem Testdatensatz plotten und den Median-Absolutfehler berechnen.
fromsklearn.metricsimportPredictionErrorDisplay,median_absolute_errormae_train=median_absolute_error(y_train,model.predict(X_train))y_pred=model.predict(X_test)mae_test=median_absolute_error(y_test,y_pred)scores={"MedAE on training set":f"{mae_train:.2f} $/hour","MedAE on testing set":f"{mae_test:.2f} $/hour",}
_,ax=plt.subplots(figsize=(5,5))display=PredictionErrorDisplay.from_predictions(y_test,y_pred,kind="actual_vs_predicted",ax=ax,scatter_kwargs={"alpha":0.5})ax.set_title("Ridge model, small regularization")forname,scoreinscores.items():ax.plot([],[]," ",label=f"{name}: {score}")ax.legend(loc="upper left")plt.tight_layout()
Das gelernte Modell ist weit davon entfernt, gute Vorhersagen zu treffen: Dies ist offensichtlich, wenn man sich die obige Grafik ansieht, wo gute Vorhersagen auf der schwarzen gestrichelten Linie liegen sollten.
Im folgenden Abschnitt interpretieren wir die Koeffizienten des Modells. Während wir dies tun, sollten wir bedenken, dass jede Schlussfolgerung, die wir ziehen, sich auf das von uns gebaute Modell bezieht und nicht auf den wahren (realen) Generierungsprozess der Daten.
Interpretation von Koeffizienten: Skalierung ist wichtig#
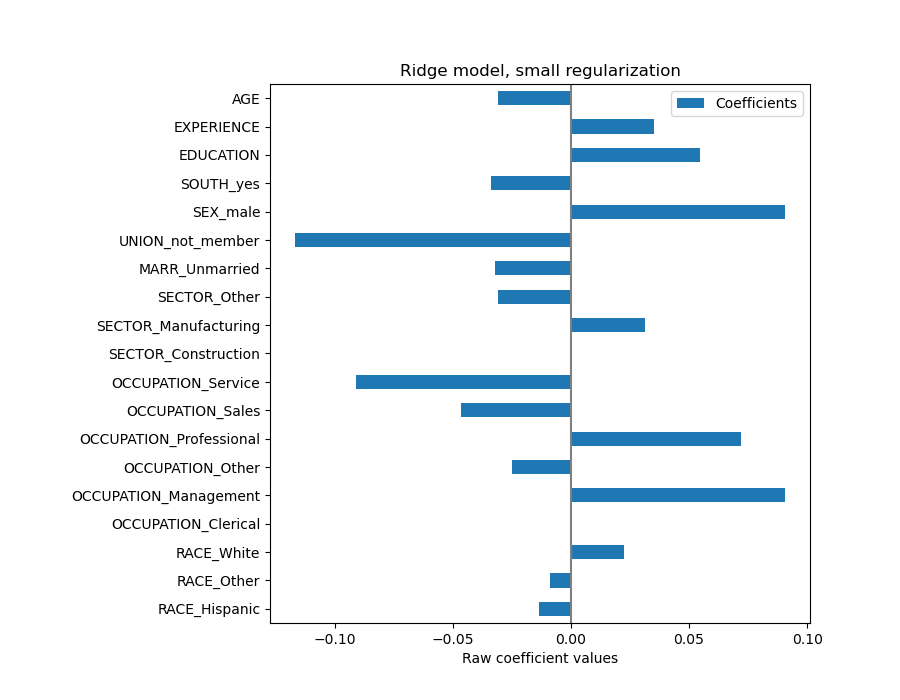
Zunächst einmal können wir uns die Werte der Koeffizienten des von uns angepassten Regressors ansehen.
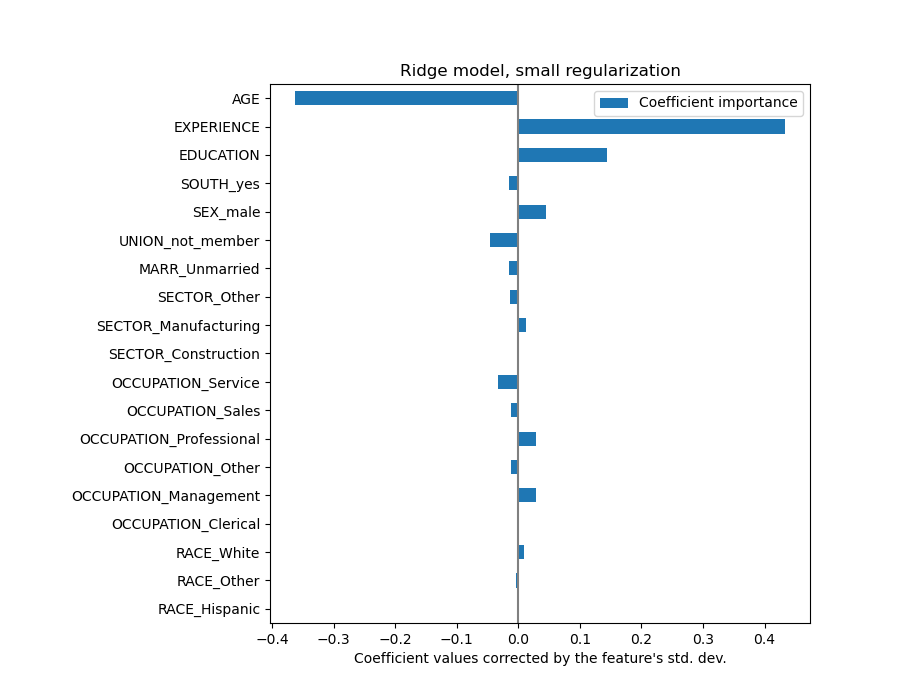
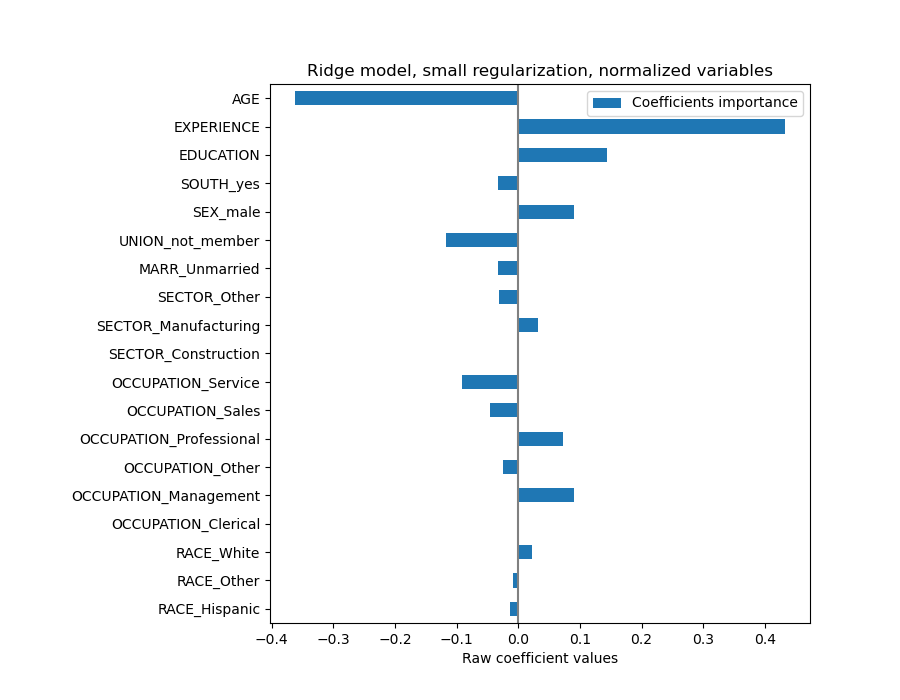
Der AGE-Koeffizient ist in „Dollar/Stunde pro Lebensjahr“ ausgedrückt, während der EDUCATION-Koeffizient in „Dollar/Stunde pro Bildungsjahr“ ausgedrückt wird. Diese Darstellung der Koeffizienten hat den Vorteil, dass die praktischen Vorhersagen des Modells klar ersichtlich sind: Eine Erhöhung des ALTER um \(1\) Jahr bedeutet eine Verringerung um \(0.030867\) Dollar/Stunde, während eine Erhöhung der BILDUNG um \(1\) Jahr eine Erhöhung um \(0.054699\) Dollar/Stunde bedeutet. Kategoriale Variablen (wie UNION oder SEX) sind dagegen dimensionlose Zahlen, die entweder den Wert 0 oder 1 annehmen. Ihre Koeffizienten werden in Dollar/Stunde ausgedrückt. Dann können wir die Größe verschiedener Koeffizienten nicht vergleichen, da die Merkmale aufgrund ihrer unterschiedlichen Maßeinheiten unterschiedliche natürliche Skalen und somit Wertebereiche haben. Dies wird deutlicher, wenn wir die Koeffizienten plotten.
Tatsächlich erscheint aus der obigen Grafik der wichtigste Faktor bei der Bestimmung des WAGE die Variable UNION zu sein, auch wenn unsere Intuition uns sagen könnte, dass Variablen wie ERFAHRUNG mehr Einfluss haben sollten.
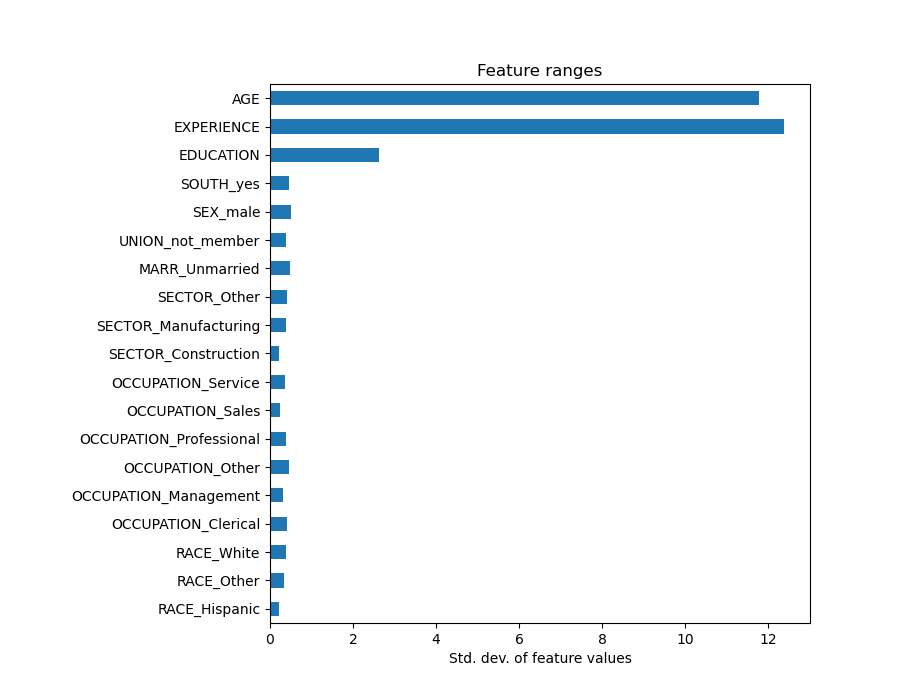
Die Betrachtung des Koeffizientenplots zur Beurteilung der Merkmalswichtigkeit kann irreführend sein, da einige davon auf einer kleinen Skala variieren, während andere, wie AGE, stark schwanken.
Dies wird deutlich, wenn wir die Standardabweichungen verschiedener Merkmale vergleichen.
X_train_preprocessed=pd.DataFrame(model[:-1].transform(X_train),columns=feature_names)X_train_preprocessed.std(axis=0).plot.barh(figsize=(9,7))plt.title("Feature ranges")plt.xlabel("Std. dev. of feature values")plt.subplots_adjust(left=0.3)
Das Multiplizieren der Koeffizienten mit der Standardabweichung des zugehörigen Merkmals würde alle Koeffizienten auf die gleiche Maßeinheit reduzieren. Wie wir später sehen werden, ist dies gleichbedeutend mit der Normalisierung numerischer Variablen auf ihre Standardabweichung, da \(y = \sum{coef_i \times X_i} = \sum{(coef_i \times std_i) \times (X_i / std_i)}\).
Auf diese Weise betonen wir, dass je größer die Varianz eines Merkmals ist, desto größer ist das Gewicht des entsprechenden Koeffizienten auf die Ausgabe, wenn alle anderen Faktoren gleich sind.
coefs=pd.DataFrame(model[-1].regressor_.coef_*X_train_preprocessed.std(axis=0),columns=["Coefficient importance"],index=feature_names,)coefs.plot(kind="barh",figsize=(9,7))plt.xlabel("Coefficient values corrected by the feature's std. dev.")plt.title("Ridge model, small regularization")plt.axvline(x=0,color=".5")plt.subplots_adjust(left=0.3)
Nachdem die Koeffizienten skaliert wurden, können wir sie sicher vergleichen.
Hinweis
Warum deutet die obige Grafik darauf hin, dass eine Zunahme des Alters zu einer Abnahme des Lohns führt? Warum besagt der anfängliche Pairplot das Gegenteil? Dieser Unterschied ist der Unterschied zwischen marginaler und bedingter Abhängigkeit.
Die obige Grafik gibt Auskunft über die Abhängigkeiten zwischen einem bestimmten Merkmal und dem Ziel, wenn alle anderen Merkmale konstant bleiben, d. h. über **bedingte Abhängigkeiten**. Eine Zunahme des ALTER führt zu einer Abnahme des LOHN, wenn alle anderen Merkmale konstant bleiben. Im Gegensatz dazu führt eine Zunahme der ERFAHRUNG zu einer Zunahme des LOHN, wenn alle anderen Merkmale konstant bleiben. Außerdem sind ALTER, ERFAHRUNG und BILDUNG die drei Variablen, die das Modell am meisten beeinflussen.
Interpretation von Koeffizienten: Vorsicht bei Kausalität#
Lineare Modelle sind ein großartiges Werkzeug zur Messung statistischer Zusammenhänge, aber wir sollten vorsichtig sein, wenn wir Aussagen über Kausalität treffen, da Korrelation nicht immer Kausalität impliziert. Dies ist in den Sozialwissenschaften besonders schwierig, da die Variablen, die wir beobachten, nur als Stellvertreter für den zugrundeliegenden kausalen Prozess dienen.
In unserem speziellen Fall können wir die BILDUNG eines Individuums als Stellvertreter für seine berufliche Eignung betrachten, die eigentliche Variable, an der wir interessiert sind, aber nicht beobachten können. Wir würden sicherlich gerne glauben, dass ein längerer Schulbesuch die technische Kompetenz erhöht, aber es ist auch gut möglich, dass die Kausalität in die andere Richtung geht. Das heißt, wer technisch kompetent ist, bleibt tendenziell länger in der Schule.
Ein Arbeitgeber wird sich wahrscheinlich nicht darum kümmern, welcher Fall vorliegt (oder ob es sich um eine Mischung aus beidem handelt), solange er davon überzeugt ist, dass eine Person mit mehr BILDUNG besser für den Job geeignet ist, wird er gerne einen höheren LOHN zahlen.
Diese Vermischung von Effekten wird problematisch, wenn man über eine Form von Intervention nachdenkt, z. B. staatliche Subventionen für Universitätsabschlüsse oder Werbematerialien, die Einzelpersonen ermutigen, ein Hochschulstudium aufzunehmen. Der Nutzen dieser Maßnahmen könnte sich als überbewertet erweisen, insbesondere wenn der Grad der Vermischung stark ist. Unser Modell sagt eine Erhöhung des Stundenlohns um \(0.054699\) für jedes Bildungsjahr voraus. Der tatsächliche kausale Effekt könnte aufgrund dieser Vermischung geringer sein.
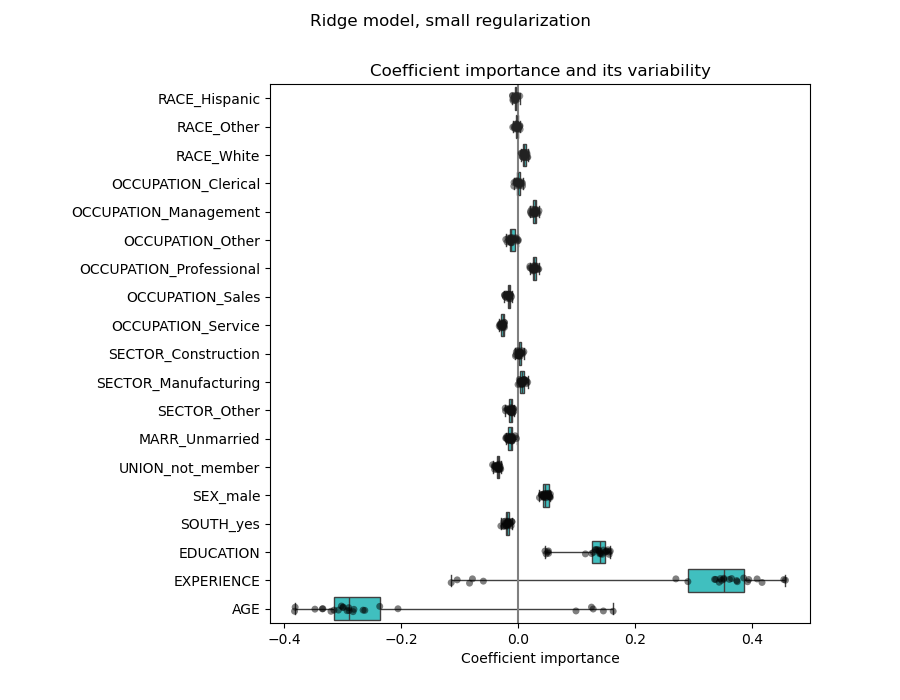
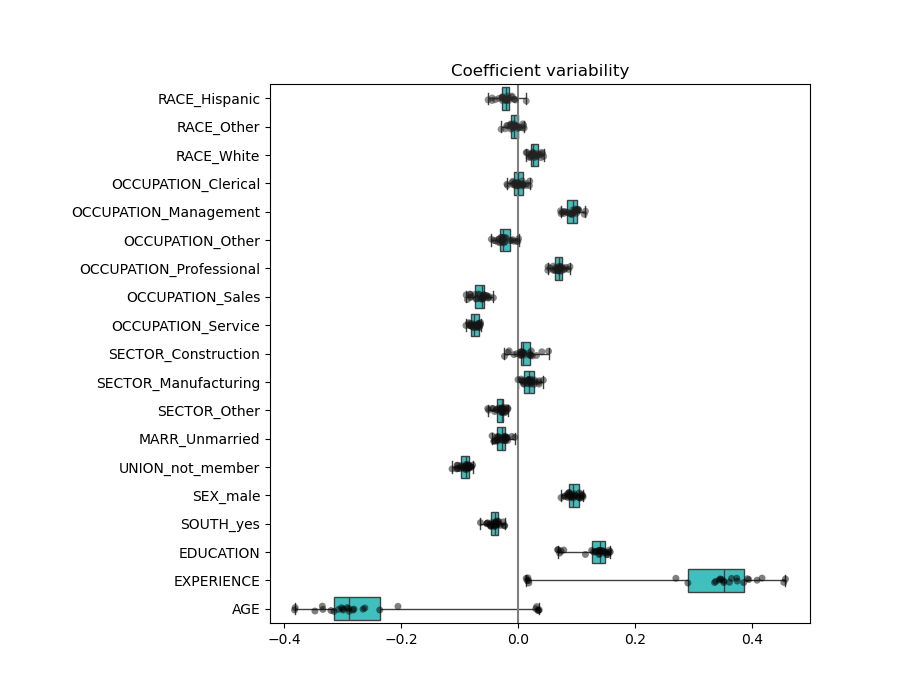
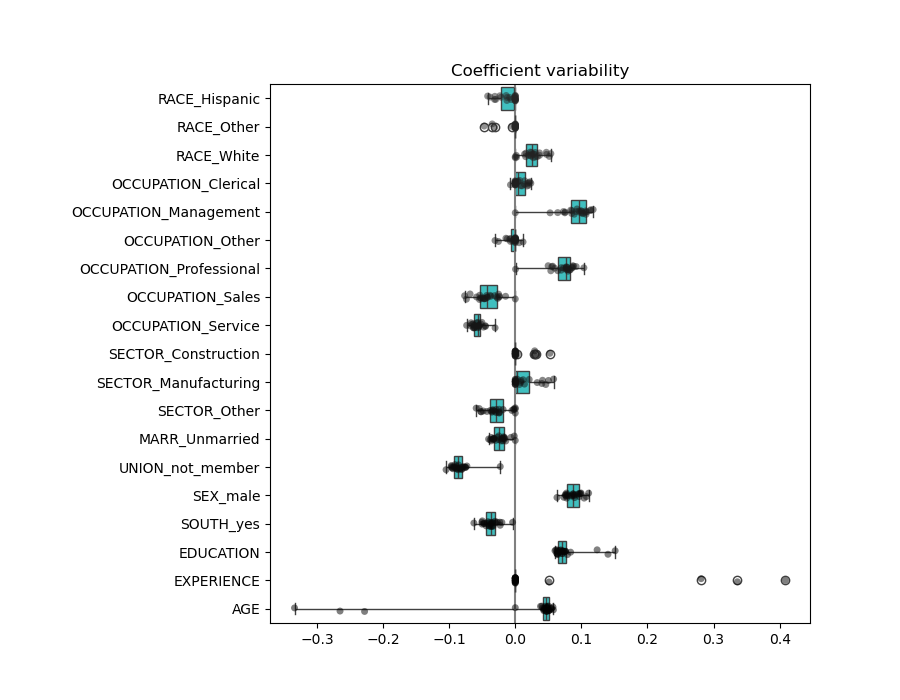
Wir können die Koeffizientenvariabilität mittels Kreuzvalidierung überprüfen: Es ist eine Form der Datenperturbation (verwandt mit Resampling).
Wenn die Koeffizienten bei Änderung des Eingabedatensatzes signifikant variieren, ist ihre Robustheit nicht garantiert, und sie sollten wahrscheinlich mit Vorsicht interpretiert werden.
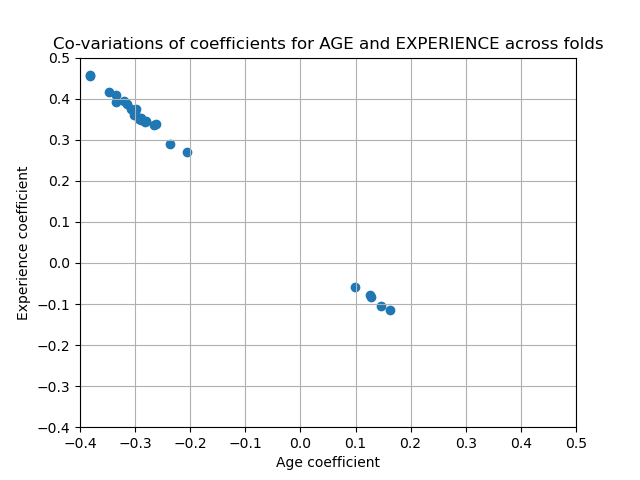
Die Koeffizienten für ALTER und ERFAHRUNG sind von starker Variabilität betroffen, was auf die Kollinearität zwischen den beiden Merkmalen zurückzuführen sein könnte: Da ALTER und ERFAHRUNG im Datensatz gemeinsam variieren, ist ihre Wirkung schwer auseinanderzuhalten.
Um diese Interpretation zu überprüfen, plotten wir die Variabilität des Koeffizienten für ALTER und ERFAHRUNG.
Die Schätzung des ERFAHRUNGS-Koeffizienten zeigt nun eine deutlich reduzierte Variabilität. ERFAHRUNG bleibt für alle während der Kreuzvalidierung trainierten Modelle wichtig.
Wie oben erwähnt (siehe „Die Machine-Learning-Pipeline“), könnten wir auch wählen, numerische Werte vor dem Training des Modells zu skalieren. Dies kann nützlich sein, wenn wir eine ähnliche Regularisierung auf alle anwenden, wie beim Ridge-Verfahren. Der Vorverarbeiter wird neu definiert, um den Mittelwert zu subtrahieren und die Variablen auf Einheitsvarianz zu skalieren.
In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook. Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Auch hier prüfen wir die Leistung des berechneten Modells anhand des Median-Absolutfehlers.
mae_train=median_absolute_error(y_train,model.predict(X_train))y_pred=model.predict(X_test)mae_test=median_absolute_error(y_test,y_pred)scores={"MedAE on training set":f"{mae_train:.2f} $/hour","MedAE on testing set":f"{mae_test:.2f} $/hour",}_,ax=plt.subplots(figsize=(5,5))display=PredictionErrorDisplay.from_predictions(y_test,y_pred,kind="actual_vs_predicted",ax=ax,scatter_kwargs={"alpha":0.5})ax.set_title("Ridge model, small regularization")forname,scoreinscores.items():ax.plot([],[]," ",label=f"{name}: {score}")ax.legend(loc="upper left")plt.tight_layout()
Für die Koeffizientenanalyse ist diesmal keine Skalierung erforderlich, da sie im Vorverarbeitungsschritt durchgeführt wurde.
coefs=pd.DataFrame(model[-1].regressor_.coef_,columns=["Coefficients importance"],index=feature_names,)coefs.plot.barh(figsize=(9,7))plt.title("Ridge model, small regularization, normalized variables")plt.xlabel("Raw coefficient values")plt.axvline(x=0,color=".5")plt.subplots_adjust(left=0.3)
Wir untersuchen nun die Koeffizienten über mehrere Kreuzvalidierungs-Folds.
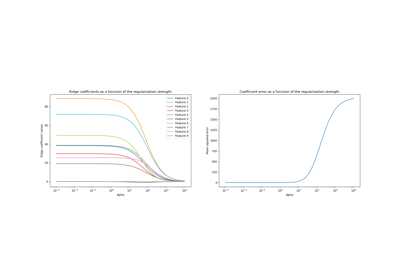
In der Praxis des maschinellen Lernens wird die Ridge-Regression häufiger mit nicht unerheblicher Regularisierung verwendet.
Oben haben wir diese Regularisierung auf einen sehr geringen Betrag beschränkt. Regularisierung verbessert die Konditionierung des Problems und reduziert die Varianz der Schätzungen. RidgeCV wendet Kreuzvalidierung an, um zu bestimmen, welcher Wert des Regularisierungsparameters (alpha) für die Vorhersage am besten geeignet ist.
In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook. Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
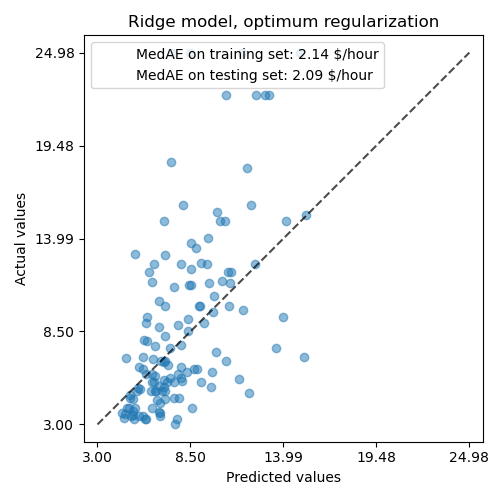
Zuerst prüfen wir, welcher Wert von \(\alpha\) ausgewählt wurde.
model[-1].regressor_.alpha_
10.0
Dann prüfen wir die Qualität der Vorhersagen.
mae_train=median_absolute_error(y_train,model.predict(X_train))y_pred=model.predict(X_test)mae_test=median_absolute_error(y_test,y_pred)scores={"MedAE on training set":f"{mae_train:.2f} $/hour","MedAE on testing set":f"{mae_test:.2f} $/hour",}_,ax=plt.subplots(figsize=(5,5))display=PredictionErrorDisplay.from_predictions(y_test,y_pred,kind="actual_vs_predicted",ax=ax,scatter_kwargs={"alpha":0.5})ax.set_title("Ridge model, optimum regularization")forname,scoreinscores.items():ax.plot([],[]," ",label=f"{name}: {score}")ax.legend(loc="upper left")plt.tight_layout()
Die Fähigkeit, die Daten des regulierten Modells zu reproduzieren, ist ähnlich der des nicht-regulierten Modells.
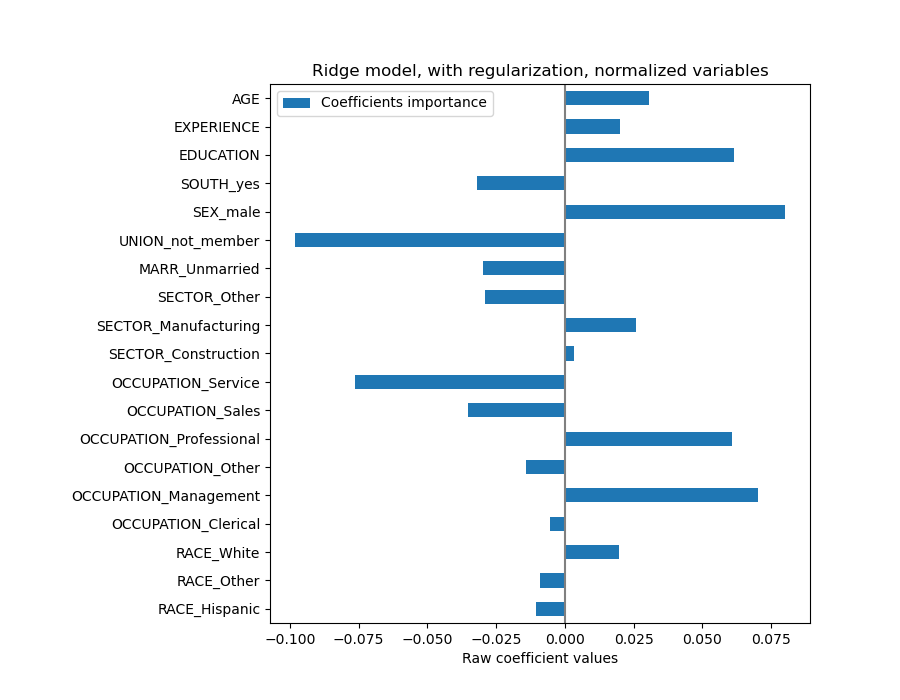
coefs=pd.DataFrame(model[-1].regressor_.coef_,columns=["Coefficients importance"],index=feature_names,)coefs.plot.barh(figsize=(9,7))plt.title("Ridge model, with regularization, normalized variables")plt.xlabel("Raw coefficient values")plt.axvline(x=0,color=".5")plt.subplots_adjust(left=0.3)
Die Koeffizienten sind signifikant unterschiedlich. Die Koeffizienten für ALTER und ERFAHRUNG sind beide positiv, aber sie haben nun weniger Einfluss auf die Vorhersage.
Die Regularisierung reduziert den Einfluss korrelierter Variablen auf das Modell, da das Gewicht zwischen den beiden prädiktiven Variablen geteilt wird, sodass keine von ihnen allein starke Gewichte hätte.
Auf der anderen Seite sind die mit Regularisierung erhaltenen Gewichte stabiler (siehe den Abschnitt Ridge-Regression und Klassifizierung im Benutzerhandbuch). Diese erhöhte Stabilität ist aus der Darstellung ersichtlich, die aus Datenperturbationen in einer Kreuzvalidierung gewonnen wurde. Diese Darstellung kann mit der vorherigen verglichen werden.
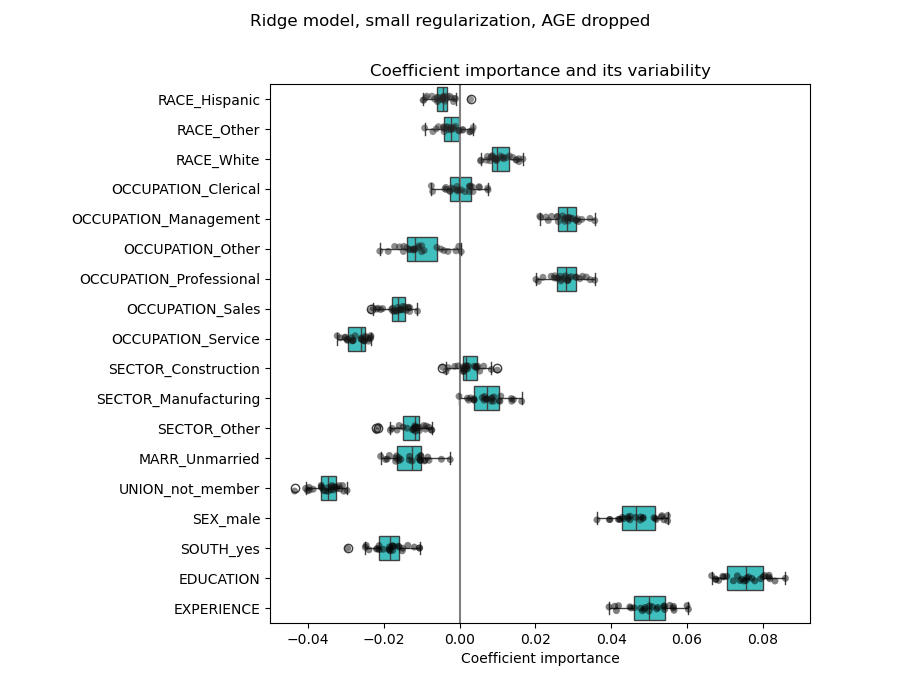
Eine weitere Möglichkeit, korrelierte Variablen im Datensatz zu berücksichtigen, ist die Schätzung von dünnbesetzten Koeffizienten. In gewisser Weise haben wir dies bereits manuell getan, als wir die AGE-Spalte in einer früheren Ridge-Schätzung verworfen haben.
Lasso-Modelle (siehe den Abschnitt Lasso im Benutzerhandbuch) schätzen dünnbesetzte Koeffizienten. LassoCV wendet Kreuzvalidierung an, um zu bestimmen, welcher Wert des Regularisierungsparameters (alpha) am besten für die Modellschätzung geeignet ist.
Zuerst überprüfen wir, welcher Wert von \(\alpha\) ausgewählt wurde.
model[-1].regressor_.alpha_
np.float64(0.001)
Dann prüfen wir die Qualität der Vorhersagen.
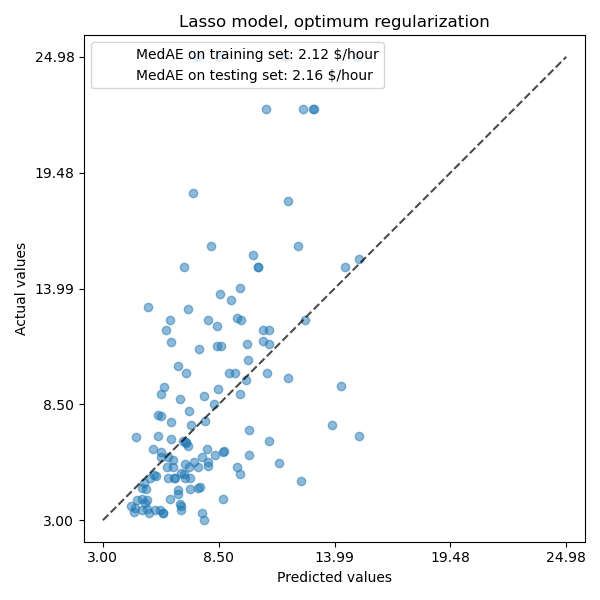
mae_train=median_absolute_error(y_train,model.predict(X_train))y_pred=model.predict(X_test)mae_test=median_absolute_error(y_test,y_pred)scores={"MedAE on training set":f"{mae_train:.2f} $/hour","MedAE on testing set":f"{mae_test:.2f} $/hour",}_,ax=plt.subplots(figsize=(6,6))display=PredictionErrorDisplay.from_predictions(y_test,y_pred,kind="actual_vs_predicted",ax=ax,scatter_kwargs={"alpha":0.5})ax.set_title("Lasso model, optimum regularization")forname,scoreinscores.items():ax.plot([],[]," ",label=f"{name}: {score}")ax.legend(loc="upper left")plt.tight_layout()
Für unseren Datensatz ist das Modell wieder nicht sehr prädiktiv.
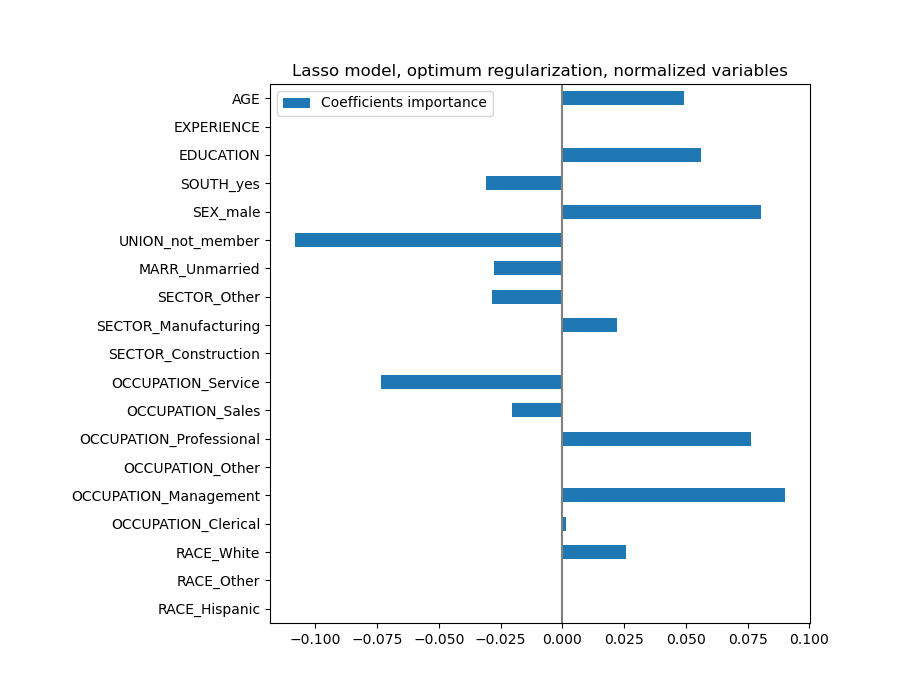
Ein Lasso-Modell identifiziert die Korrelation zwischen ALTER und ERFAHRUNG und unterdrückt eine davon zugunsten der Vorhersage.
Es ist wichtig zu bedenken, dass die verworfenen Koeffizienten möglicherweise selbst noch mit dem Ergebnis zusammenhängen: Das Modell hat sich entschieden, sie zu unterdrücken, weil sie auf den anderen Merkmalen wenig oder keine zusätzliche Information bringen. Darüber hinaus ist diese Auswahl bei korrelierten Merkmalen instabil und sollte mit Vorsicht interpretiert werden.
Tatsächlich können wir die Variabilität der Koeffizienten über die Folds hinweg überprüfen.
Politiker möchten vielleicht den Effekt von Bildung auf Lohn kennen, um zu beurteilen, ob eine bestimmte Politik zur Förderung von mehr Bildung wirtschaftlich sinnvoll wäre. Während Machine-Learning-Modelle hervorragend darin sind, statistische Zusammenhänge zu messen, sind sie im Allgemeinen nicht in der Lage, kausale Effekte zu inferieren.
Es könnte verlockend sein, den Koeffizienten von Bildung auf Lohn aus unserem letzten Modell (oder einem beliebigen Modell) zu betrachten und zu dem Schluss zu kommen, dass er den wahren Effekt einer Änderung der standardisierten Bildungs variable auf die Löhne erfasst.
Leider gibt es wahrscheinlich unbeobachtete Störvariablen, die diesen Koeffizienten entweder aufblähen oder verzerren. Eine Störvariable ist eine Variable, die sowohl BILDUNG als auch LOHN verursacht. Ein Beispiel für eine solche Variable ist die Fähigkeit. Vermutlich streben fähigere Personen eher eine höhere Bildung an und verdienen gleichzeitig wahrscheinlich einen höheren Stundenlohn bei jedem Bildungsniveau. In diesem Fall induziert die Fähigkeit eine positive verzerrte Variable (OVB) auf den Bildungs koeffizienten und übertreibt damit den Effekt von Bildung auf Löhne.
Koeffizienten müssen auf die gleiche Maßeinheit skaliert werden, um die Merkmalswichtigkeit wiederherzustellen. Eine Skalierung mit der Standardabweichung des Merkmals ist ein nützlicher Anhaltspunkt.
Koeffizienten in multivariaten linearen Modellen stellen die Abhängigkeit zwischen einem bestimmten Merkmal und dem Ziel dar, **bedingt** auf den anderen Merkmalen.
Korrelierte Merkmale induzieren Instabilitäten in den Koeffizienten linearer Modelle und ihre Effekte können nicht gut auseinandergezogen werden.
Unterschiedliche lineare Modelle reagieren unterschiedlich auf Merkmalskorrelationen, und die Koeffizienten können sich erheblich voneinander unterscheiden.
Die Inspektion von Koeffizienten über die Folds einer Kreuzvalidierungsschleife gibt eine Vorstellung von ihrer Stabilität.
Die Interpretation von Kausalität ist schwierig, wenn Stör effekte vorliegen. Wenn die Beziehung zwischen zwei Variablen auch von etwas Unbeobachtetem beeinflusst wird, sollten wir vorsichtig sein, wenn wir Schlussfolgerungen über Kausalität ziehen.
Gesamtlaufzeit des Skripts: (0 Minuten 9,893 Sekunden)