Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
L1-Strafe und Sparsity in der Logistischen Regression#
Vergleich der Sparsity (Prozentsatz der Nullkoeffizienten) von Lösungen bei Verwendung von L1, L2 und Elastic-Net-Strafe für verschiedene Werte von C. Man sieht, dass große Werte von C dem Modell mehr Freiheit geben. Umgekehrt schränken kleinere Werte von C das Modell stärker ein. Im Fall der L1-Strafe führt dies zu spärlicheren Lösungen. Wie erwartet liegt die Sparsity der Elastic-Net-Strafe zwischen der von L1 und L2.
Wir klassifizieren 8x8-Bilder von Ziffern in zwei Klassen: 0-4 gegen 5-9. Die Visualisierung zeigt die Koeffizienten der Modelle für verschiedene C-Werte.

C=1.00
Sparsity with L1 penalty: 4.69%
Sparsity with Elastic-Net penalty: 4.69%
Sparsity with L2 penalty: 4.69%
Score with L1 penalty: 0.90
Score with Elastic-Net penalty: 0.90
Score with L2 penalty: 0.90
C=0.10
Sparsity with L1 penalty: 29.69%
Sparsity with Elastic-Net penalty: 14.06%
Sparsity with L2 penalty: 4.69%
Score with L1 penalty: 0.90
Score with Elastic-Net penalty: 0.90
Score with L2 penalty: 0.90
C=0.01
Sparsity with L1 penalty: 84.38%
Sparsity with Elastic-Net penalty: 68.75%
Sparsity with L2 penalty: 4.69%
Score with L1 penalty: 0.86
Score with Elastic-Net penalty: 0.88
Score with L2 penalty: 0.89
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
X, y = datasets.load_digits(return_X_y=True)
X = StandardScaler().fit_transform(X)
# classify small against large digits
y = (y > 4).astype(int)
l1_ratio = 0.5 # L1 weight in the Elastic-Net regularization
fig, axes = plt.subplots(3, 3)
# Set regularization parameter
for i, (C, axes_row) in enumerate(zip((1, 0.1, 0.01), axes)):
# Increase tolerance for short training time
clf_l1_LR = LogisticRegression(C=C, l1_ratio=1, tol=0.01, solver="saga")
clf_l2_LR = LogisticRegression(C=C, l1_ratio=0, tol=0.01, solver="saga")
clf_en_LR = LogisticRegression(C=C, l1_ratio=l1_ratio, tol=0.01, solver="saga")
clf_l1_LR.fit(X, y)
clf_l2_LR.fit(X, y)
clf_en_LR.fit(X, y)
coef_l1_LR = clf_l1_LR.coef_.ravel()
coef_l2_LR = clf_l2_LR.coef_.ravel()
coef_en_LR = clf_en_LR.coef_.ravel()
# coef_l1_LR contains zeros due to the
# L1 sparsity inducing norm
sparsity_l1_LR = np.mean(coef_l1_LR == 0) * 100
sparsity_l2_LR = np.mean(coef_l2_LR == 0) * 100
sparsity_en_LR = np.mean(coef_en_LR == 0) * 100
print(f"C={C:.2f}")
print(f"{'Sparsity with L1 penalty:':<40} {sparsity_l1_LR:.2f}%")
print(f"{'Sparsity with Elastic-Net penalty:':<40} {sparsity_en_LR:.2f}%")
print(f"{'Sparsity with L2 penalty:':<40} {sparsity_l2_LR:.2f}%")
print(f"{'Score with L1 penalty:':<40} {clf_l1_LR.score(X, y):.2f}")
print(f"{'Score with Elastic-Net penalty:':<40} {clf_en_LR.score(X, y):.2f}")
print(f"{'Score with L2 penalty:':<40} {clf_l2_LR.score(X, y):.2f}")
if i == 0:
axes_row[0].set_title("L1 penalty")
axes_row[1].set_title("Elastic-Net\nl1_ratio = %s" % l1_ratio)
axes_row[2].set_title("L2 penalty")
for ax, coefs in zip(axes_row, [coef_l1_LR, coef_en_LR, coef_l2_LR]):
ax.imshow(
np.abs(coefs.reshape(8, 8)),
interpolation="nearest",
cmap="binary",
vmax=1,
vmin=0,
)
ax.set_xticks(())
ax.set_yticks(())
axes_row[0].set_ylabel(f"C = {C}")
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 0,376 Sekunden)
Verwandte Beispiele
MNIST-Klassifikation mittels multinomialer Logistik + L1
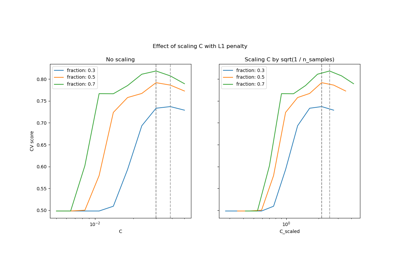
Skalierung des Regularisierungsparameters für SVCs