load_digits#
- sklearn.datasets.load_digits(*, n_class=10, return_X_y=False, as_frame=False)[source]#
Lädt und gibt den Ziffern Datensatz (Klassifikation) zurück.
Jeder Datenpunkt ist ein 8x8 Bild einer Ziffer.
Klassen
10
Stichproben pro Klasse
~180
Gesamtanzahl Samples
1797
Dimensionalität
64
Merkmale
ganze Zahlen 0-16
Dies ist eine Kopie des Testsets der UCI ML handgeschriebenen Ziffern Datensätze https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- n_classint, Standard=10
Die Anzahl der zurückzugebenden Klassen. Zwischen 0 und 10.
- return_X_ybool, Standard=False
Wenn True, wird ein Bunch-Objekt zurückgegeben, das
(data, target)enthält. Weitere Informationen zu den Objektendataundtargetfinden Sie unten.Hinzugefügt in Version 0.18.
- as_framebool, default=False
Wenn True, sind die Daten ein pandas DataFrame, einschließlich Spalten mit geeigneten dtypes (numerisch). Das Ziel ist ein pandas DataFrame oder eine Series, abhängig von der Anzahl der Zielspalten. Wenn
return_X_yTrue ist, dann sind (data,target) pandas DataFrames oder Series wie unten beschrieben.Hinzugefügt in Version 0.23.
- Gibt zurück:
- data
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- data{ndarray, dataframe} der Form (1797, 64)
Die geflattete Datenmatrix. Wenn
as_frame=True, istdataein pandas DataFrame.- target: {ndarray, Series} der Form (1797,)
Das Klassifizierungsziel. Wenn
as_frame=True, isttargeteine pandas Series.- feature_names: list
Die Namen der Datensatzspalten.
- target_names: list
Die Namen der Zielklassen.
Hinzugefügt in Version 0.20.
- frame: DataFrame der Form (1797, 65)
Nur vorhanden, wenn
as_frame=True. DataFrame mitdataundtarget.Hinzugefügt in Version 0.23.
- images: {ndarray} der Form (1797, 8, 8)
Die Rohbilddaten.
- DESCR: str
Die vollständige Beschreibung des Datensatzes.
- (data, target)tuple, wenn
return_X_yTrue ist Standardmäßig ein Tupel aus zwei ndarrays. Das erste enthält ein 2D-ndarray der Form (1797, 64), wobei jede Zeile eine Stichprobe und jede Spalte die Merkmale darstellt. Das zweite ndarray der Form (1797) enthält die Zielstichproben. Wenn
as_frame=True, sind beide Arrays pandas-Objekte, d.h.Xein DataFrame undyeine Series.Hinzugefügt in Version 0.18.
- data
Beispiele
So laden Sie die Daten und visualisieren Sie die Bilder
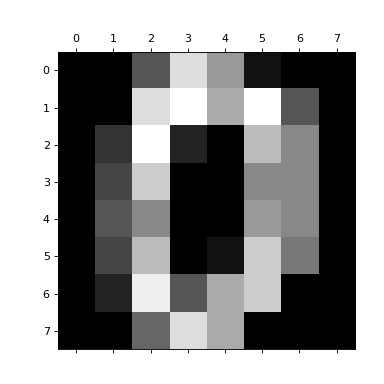
>>> from sklearn.datasets import load_digits >>> digits = load_digits() >>> print(digits.data.shape) (1797, 64) >>> import matplotlib.pyplot as plt >>> plt.matshow(digits.images[0], cmap="gray") <...> >>> plt.show()
Galeriebeispiele#
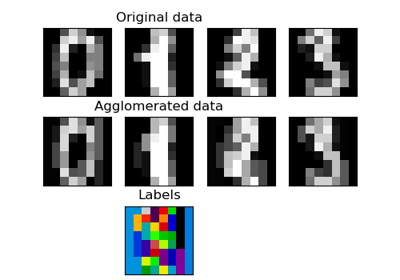
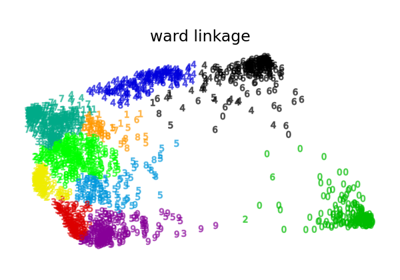
Verschiedenes Agglomeratives Clustering auf einer 2D-Einbettung von Ziffern
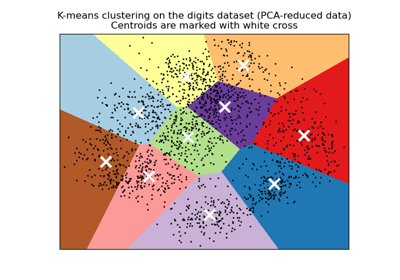
Eine Demo des K-Means Clusterings auf den handschriftlichen Zifferndaten
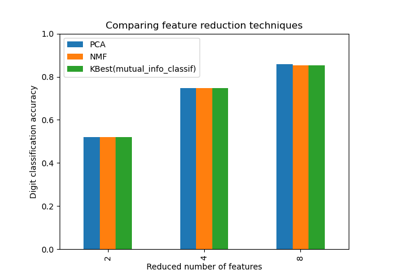
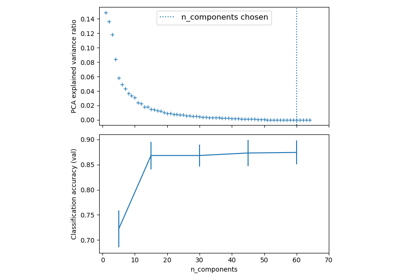
Dimensionsreduktion auswählen mit Pipeline und GridSearchCV
Pipelining: Verkettung einer PCA und einer logistischen Regression

Manifold Learning auf handschriftlichen Ziffern: Locally Linear Embedding, Isomap…
Die Johnson-Lindenstrauss-Schranke für Einbettung mit zufälligen Projektionen


Benutzerdefinierte Refit-Strategie einer Gitter-Suche mit Kreuzvalidierung
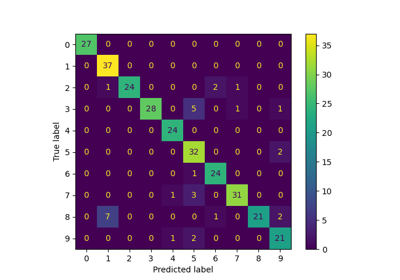
Modellkomplexität und kreuzvalidierter Score ausbalancieren
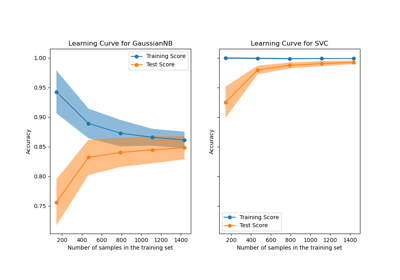
Lernkurven plotten und die Skalierbarkeit von Modellen prüfen

Vergleich von zufälliger Suche und Gitter-Suche zur Hyperparameter-Schätzung
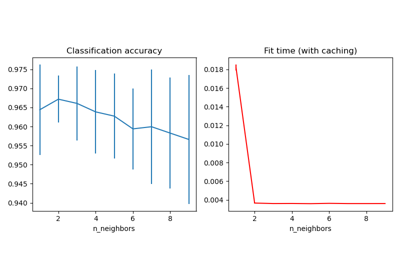
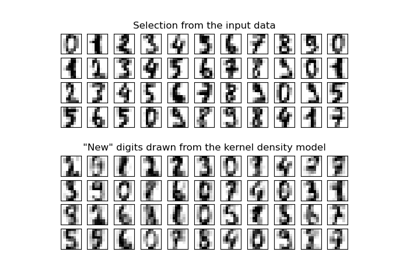
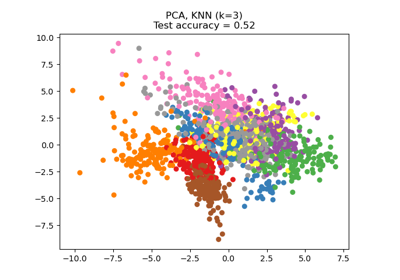
Dimensionsreduktion mit Neighborhood Components Analysis
Vergleich von stochastischen Lernstrategien für MLPClassifier

Restricted Boltzmann Machine Merkmale für Ziffernklassifikation