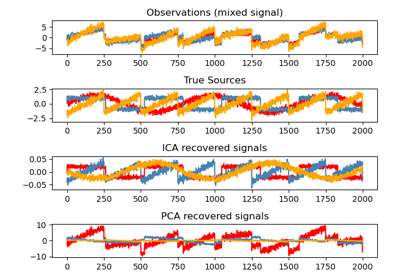
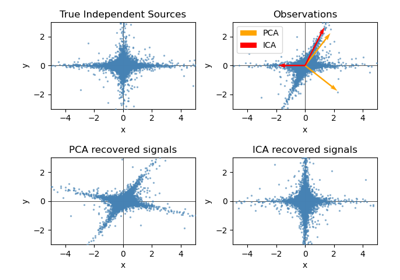
FastICA#
- class sklearn.decomposition.FastICA(n_components=None, *, algorithm='parallel', whiten='unit-variance', fun='logcosh', fun_args=None, max_iter=200, tol=0.0001, w_init=None, whiten_solver='svd', random_state=None)[Quelle]#
FastICA: Ein schneller Algorithmus für Independent Component Analysis.
Die Implementierung basiert auf [1].
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- n_componentsint, default=None
Anzahl der zu verwendenden Komponenten. Wenn None übergeben wird, werden alle verwendet.
- algorithm{‘parallel’, ‘deflation’}, default=’parallel’
Gibt an, welcher Algorithmus für FastICA verwendet werden soll.
- whitenstr or bool, default=’unit-variance’
Gibt die zu verwendende Whitening-Strategie an.
Wenn ‘arbitrary-variance’, wird ein Whitening mit beliebiger Varianz verwendet.
Wenn ‘unit-variance’, wird die Whitening-Matrix so skaliert, dass jede wiederhergestellte Quelle die Einheitsvarianz hat.
Wenn False, wird davon ausgegangen, dass die Daten bereits gewhitet sind und es wird kein Whitening durchgeführt.
Geändert in Version 1.3: Der Standardwert von
whitenwurde in Version 1.3 auf ‘unit-variance’ geändert.- fun{‘logcosh’, ‘exp’, ‘cube’} or callable, default=’logcosh’
Die funktionale Form der G-Funktion, die bei der Annäherung an die Negentropie verwendet wird. Kann ‘logcosh’, ‘exp’ oder ‘cube’ sein. Sie können auch Ihre eigene Funktion bereitstellen. Sie sollte ein Tupel zurückgeben, das den Wert der Funktion und ihrer Ableitung an diesem Punkt enthält. Die Ableitung sollte entlang ihrer letzten Dimension gemittelt werden. Beispiel
def my_g(x): return x ** 3, (3 * x ** 2).mean(axis=-1)
- fun_argsdict, default=None
Argumente, die an die funktionale Form übergeben werden sollen. Wenn leer oder None und wenn fun=’logcosh’, nimmt fun_args den Wert {‘alpha’ : 1.0} an.
- max_iterint, Standard=200
Maximale Anzahl von Iterationen während des Fits.
- tolfloat, Standard=1e-4
Eine positive Skalare, die die Toleranz angibt, bei der die entwirrende Matrix als konvergiert betrachtet wird.
- w_initarray-like of shape (n_components, n_components), default=None
Ursprüngliche entwirrende Matrix. Wenn
w_init=None, wird eine Matrix mit Werten aus einer Normalverteilung verwendet.- whiten_solver{“eigh”, “svd”}, default=”svd”
Der Solver, der für das Whitening verwendet werden soll.
„svd“ ist numerisch stabiler, wenn das Problem degeneriert ist, und oft schneller, wenn
n_samples <= n_features.„eigh“ ist im Allgemeinen speichereffizienter, wenn
n_samples >= n_features, und kann schneller sein, wennn_samples >= 50 * n_features.
Hinzugefügt in Version 1.2.
- random_stateint, RandomState-Instanz oder None, default=None
Wird verwendet, um
w_initzu initialisieren, wenn nicht angegeben, mit einer Normalverteilung. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- Attribute:
- components_ndarray der Form (n_components, n_features)
Der lineare Operator, der auf die Daten angewendet wird, um die unabhängigen Quellen zu erhalten. Dies entspricht der entwirrenden Matrix, wenn
whitenFalse ist, und entsprichtnp.dot(unmixing_matrix, self.whitening_), wennwhitenTrue ist.- mixing_ndarray of shape (n_features, n_components)
Die Pseudoinverse von
components_. Es ist der lineare Operator, der unabhängige Quellen auf die Daten abbildet.- mean_ndarray of shape(n_features,)
Der Mittelwert über die Merkmale. Nur gesetzt, wenn
self.whitenTrue ist.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_iter_int
Wenn der Algorithmus „deflation“ ist, ist n_iter die maximale Anzahl von Iterationen, die über alle Komponenten hinweg ausgeführt werden. Andernfalls ist es einfach die Anzahl der Iterationen bis zur Konvergenz.
- whitening_ndarray of shape (n_components, n_features)
Nur gesetzt, wenn whiten auf ‘True’ gesetzt ist. Dies ist die Pre-Whitening-Matrix, die die Daten auf die ersten
n_componentsHauptkomponenten projiziert.
Siehe auch
PCAHauptkomponentenanalyse (PCA).
IncrementalPCAInkrementelle Hauptkomponentenanalyse (IPCA).
KernelPCAKernel Hauptkomponentenanalyse (KPCA).
MiniBatchSparsePCAMini-Batch Sparse Principal Components Analysis.
SparsePCASparse Principal Components Analysis (SparsePCA).
Referenzen
[1]A. Hyvarinen und E. Oja, Independent Component Analysis: Algorithms and Applications, Neural Networks, 13(4-5), 2000, S. 411-430.
Beispiele
>>> from sklearn.datasets import load_digits >>> from sklearn.decomposition import FastICA >>> X, _ = load_digits(return_X_y=True) >>> transformer = FastICA(n_components=7, ... random_state=0, ... whiten='unit-variance') >>> X_transformed = transformer.fit_transform(X) >>> X_transformed.shape (1797, 7)
- fit(X, y=None)[Quelle]#
Passt das Modell an X an.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Trainingsdaten, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- Gibt zurück:
- selfobject
Gibt die Instanz selbst zurück.
- fit_transform(X, y=None)[Quelle]#
Passt das Modell an und stellt die Quellen aus X wieder her.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Trainingsdaten, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- Gibt zurück:
- X_newndarray der Form (n_samples, n_components)
Geschätzte Quellen, die durch Transformation der Daten mit der geschätzten entwirrenden Matrix erhalten wurden.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
Die Feature-Namen werden mit dem kleingeschriebenen Klassennamen präfixiert. Wenn der Transformer z.B. 3 Features ausgibt, dann sind die Feature-Namen:
["klassenname0", "klassenname1", "klassenname2"].- Parameter:
- input_featuresarray-like von str oder None, default=None
Wird nur verwendet, um die Feature-Namen mit den in
fitgesehenen Namen zu validieren.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X, copy=True)[Quelle]#
Transformiert die Quellen zurück in die gemischten Daten (Anwendung der Mixing-Matrix).
- Parameter:
- Xarray-ähnlich von der Form (n_samples, n_components)
Quellen, wobei
n_samplesdie Anzahl der Stichproben undn_componentsdie Anzahl der Komponenten ist.- copybool, Standard=True
Wenn False, können die an fit übergebenen Daten überschrieben werden. Standardmäßig True.
- Gibt zurück:
- X_originalndarray von der Form (n_samples, n_features)
Rekonstruierte Daten, die mit der Mixing-Matrix erhalten wurden.
- set_inverse_transform_request(*, copy: bool | None | str = '$UNCHANGED$') FastICA[Quelle]#
Konfiguriert, ob Metadaten für die Methode
inverse_transformangefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, aninverse_transformübergeben. Die Anfrage wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Estimator übergibt sie nicht aninverse_transform.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- copystr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
copyininverse_transform.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') FastICA[Quelle]#
Konfiguriert, ob Metadaten für die
transform-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, antransformweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht antransform.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- copystr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
copyintransform.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- transform(X, copy=True)[Quelle]#
Stellt die Quellen aus X wieder her (Anwendung der entwirrenden Matrix).
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Zu transformierende Daten, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- copybool, Standard=True
Wenn False, können die an fit übergebenen Daten überschrieben werden. Standardmäßig True.
- Gibt zurück:
- X_newndarray der Form (n_samples, n_components)
Geschätzte Quellen, die durch Transformation der Daten mit der geschätzten entwirrenden Matrix erhalten wurden.