LinearDiscriminantAnalysis#
- class sklearn.discriminant_analysis.LinearDiscriminantAnalysis(solver='svd', shrinkage=None, priors=None, n_components=None, store_covariance=False, tol=0.0001, covariance_estimator=None)[Quelle]#
Lineare Diskriminanzanalyse.
Ein Klassifikator mit einer linearen Entscheidungsgrenze, der durch Anpassung klassenbedingter Dichten an die Daten und Anwendung der Bayes-Regel erzeugt wird.
Das Modell passt eine Gaußsche Dichte an jede Klasse an und nimmt an, dass alle Klassen eine gemeinsame Kovarianzmatrix teilen.
Das angepasste Modell kann auch verwendet werden, um die Dimensionalität der Eingabe zu reduzieren, indem sie mit der Methode
transformauf die diskriminativsten Richtungen projiziert wird.Hinzugefügt in Version 0.17.
Für einen Vergleich zwischen
LinearDiscriminantAnalysisundQuadraticDiscriminantAnalysissiehe Lineare und quadratische Diskriminanzanalyse mit Kovarianzellipsoiden.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- solver{‘svd’, ‘lsqr’, ‘eigen’}, default=’svd’
- Zu verwendender Solver, mögliche Werte
‘svd’: Singuläre Wertzerlegung (Standard). Berechnet nicht die Kovarianzmatrix, daher wird dieser Solver für Daten mit einer großen Anzahl von Merkmalen empfohlen.
‘lsqr’: Kleinste-Quadrate-Lösung. Kann mit Schrumpfung oder einem benutzerdefinierten Kovarianzschätzer kombiniert werden.
‘eigen’: Eigenwertzerlegung. Kann mit Schrumpfung oder einem benutzerdefinierten Kovarianzschätzer kombiniert werden.
Geändert in Version 1.2:
solver="svd"hat jetzt experimentelle Array-API-Unterstützung. Weitere Details finden Sie im Array-API-Benutzerhandbuch.- shrinkage‘auto’ oder float, default=None
- Schrumpfungsparameter, mögliche Werte
None: keine Schrumpfung (Standard).
‘auto’: automatische Schrumpfung gemäß dem Ledoit-Wolf-Lemma.
float zwischen 0 und 1: fester Schrumpfungsparameter.
Dies sollte auf None belassen werden, wenn
covariance_estimatorverwendet wird. Beachten Sie, dass die Schrumpfung nur mit den Solvern ‘lsqr’ und ‘eigen’ funktioniert.Ein Anwendungsbeispiel finden Sie unter Normale, Ledoit-Wolf und OAS Lineare Diskriminanzanalyse für die Klassifizierung.
- priorsarray-like von Form (n_classes,), default=None
Die Klassenvorwahrscheinlichkeiten. Standardmäßig werden die Klassenproportionen aus den Trainingsdaten abgeleitet.
- n_componentsint, default=None
Anzahl der Komponenten (<= min(n_classes - 1, n_features)) für die Dimensionsreduktion. Wenn None, wird sie auf min(n_classes - 1, n_features) gesetzt. Dieser Parameter beeinflusst nur die
transform-Methode.Ein Anwendungsbeispiel finden Sie unter Vergleich der 2D-Projektion von LDA und PCA des Iris-Datensatzes.
- store_covariancebool, default=False
Wenn True, wird die gewichtete Kovarianzmatrix innerhalb der Klassen explizit berechnet, wenn der Solver ‘svd’ ist. Die Matrix wird für die anderen Solver immer berechnet und gespeichert.
Hinzugefügt in Version 0.17.
- tolfloat, default=1.0e-4
Absolute Schwelle für einen singulären Wert von X, um als signifikant zu gelten, verwendet zur Schätzung des Rangs von X. Dimensionen mit nicht-signifikanten singulären Werten werden verworfen. Nur verwendet, wenn der Solver ‘svd’ ist.
Hinzugefügt in Version 0.17.
- covariance_estimatorKovarianzschätzer, default=None
Wenn nicht None, wird
covariance_estimatorverwendet, um die Kovarianzmatrizen zu schätzen, anstatt sich auf den empirischen Kovarianzschätzer (mit möglicher Schrumpfung) zu verlassen. Das Objekt sollte eine fit-Methode und eincovariance_-Attribut haben, ähnlich wie die Schätzer insklearn.covariance. Wenn None, steuert der Schrumpfungsparameter die Schätzung.Dies sollte auf None belassen werden, wenn
shrinkageverwendet wird. Beachten Sie, dasscovariance_estimatornur mit den Solvern ‘lsqr’ und ‘eigen’ funktioniert.Hinzugefügt in Version 0.24.
- Attribute:
- coef_ndarray von Form (n_features,) oder (n_classes, n_features)
Gewichtsvektor(en).
- intercept_ndarray von Form (n_classes,)
Achsenabschnittsterm.
- covariance_array-like von Form (n_features, n_features)
Gewichtete Kovarianzmatrix innerhalb der Klassen. Sie entspricht
sum_k prior_k * C_k, wobeiC_kdie Kovarianzmatrix der Stichproben in Klassekist. DieC_kwerden mit dem (möglicherweise geschrumpften) verzerrten Schätzer der Kovarianz geschätzt. Wenn der Solver ‘svd’ ist, existiert sie nur, wennstore_covarianceTrue ist.- explained_variance_ratio_ndarray der Form (n_components,)
Prozentsatz der von jeder der ausgewählten Komponenten erklärten Varianz. Wenn
n_componentsnicht gesetzt ist, werden alle Komponenten gespeichert und die Summe der erklärten Varianzen ist gleich 1.0. Nur verfügbar, wenn der Solver eigen oder svd verwendet wird.- means_array-like von Form (n_classes, n_features)
Klassenweise Mittelwerte.
- priors_array-like von Form (n_classes,)
Klassenvorwahrscheinlichkeiten (Summe ergibt 1).
- scalings_array-like von Form (rank, n_classes - 1)
Skalierung der Merkmale im Raum, der von den Klassenmittelpunkten aufgespannt wird. Nur verfügbar für die Solver ‘svd’ und ‘eigen’.
- xbar_array-like von Form (n_features,)
Gesamter Mittelwert. Nur vorhanden, wenn der Solver ‘svd’ ist.
- classes_array-like von Form (n_classes,)
Eindeutige Klassenbezeichnungen.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
QuadraticDiscriminantAnalysisQuadratische Diskriminanzanalyse.
Beispiele
>>> import numpy as np >>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = LinearDiscriminantAnalysis() >>> clf.fit(X, y) LinearDiscriminantAnalysis() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[Quelle]#
Anwenden der Entscheidungfunktion auf ein Array von Stichproben.
Die Entscheidungfunktion ist gleich (bis auf einen konstanten Faktor) dem Log-Posteriori des Modells, d.h.
log p(y = k | x). In einem binären Klassifizierungsszenario entspricht dies stattdessen der Differenzlog p(y = 1 | x) - log p(y = 0 | x). Siehe Mathematische Formulierung der LDA- und QDA-Klassifikatoren.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Array von Stichproben (Testvektoren).
- Gibt zurück:
- y_scoresndarray von Form (n_samples,) oder (n_samples, n_classes)
Entscheidungsfunktionswerte, die sich auf jede Klasse pro Stichprobe beziehen. Im Fall von zwei Klassen hat die Form
(n_samples,)und gibt das Log-Likelihood-Verhältnis der positiven Klasse an.
- fit(X, y)[Quelle]#
Passen Sie das Modell der linearen Diskriminanzanalyse an.
Geändert in Version 0.19:
store_covarianceundtolwurden in den Hauptkonstruktor verschoben.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Trainingsdaten.
- yarray-like von Form (n_samples,)
Zielwerte.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- fit_transform(X, y=None, **fit_params)[Quelle]#
An Daten anpassen, dann transformieren.
Passt den Transformer an
Xundymit optionalen Parameternfit_paramsan und gibt eine transformierte Version vonXzurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabestichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs), Standardwert=None
Zielwerte (None für unüberwachte Transformationen).
- **fit_paramsdict
Zusätzliche Fit-Parameter. Nur übergeben, wenn der Estimator zusätzliche Parameter in seiner
fit-Methode akzeptiert.
- Gibt zurück:
- X_newndarray array der Form (n_samples, n_features_new)
Transformiertes Array.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
Die Feature-Namen werden mit dem kleingeschriebenen Klassennamen präfixiert. Wenn der Transformer z.B. 3 Features ausgibt, dann sind die Feature-Namen:
["klassenname0", "klassenname1", "klassenname2"].- Parameter:
- input_featuresarray-like von str oder None, default=None
Wird nur verwendet, um die Feature-Namen mit den in
fitgesehenen Namen zu validieren.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersagen von Klassenbezeichnungen für Stichproben in X.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Datenmatrix, für die wir die Vorhersagen erhalten möchten.
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Vektor, der die Klassenbezeichnungen für jede Stichprobe enthält.
- predict_log_proba(X)[Quelle]#
Log-Wahrscheinlichkeit schätzen.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- Cndarray von Form (n_samples, n_classes)
Geschätzte Log-Wahrscheinlichkeiten.
- predict_proba(X)[Quelle]#
Wahrscheinlichkeit schätzen.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- Cndarray von Form (n_samples, n_classes)
Geschätzte Wahrscheinlichkeiten.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearDiscriminantAnalysis[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- transform(X)[Quelle]#
Daten zur Maximierung der Klassentrennung projizieren.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- X_newndarray von Form (n_samples, n_components) oder (n_samples, min(rank, n_components))
Transformierte Daten. Im Fall des ‘svd’-Solvers hat die Form (n_samples, min(rank, n_components)).
Galeriebeispiele#
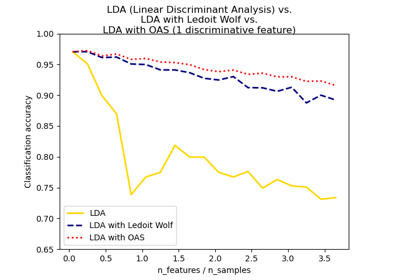
Normale, Ledoit-Wolf und OAS Lineare Diskriminanzanalyse zur Klassifikation
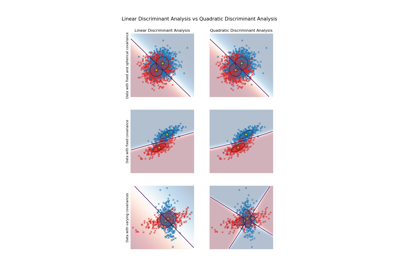
Lineare und Quadratische Diskriminanzanalyse mit Kovarianzellipsoid
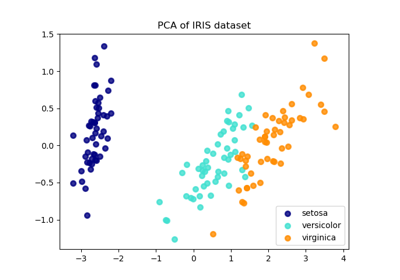
Vergleich von LDA und PCA 2D-Projektion des Iris-Datensatzes

Manifold Learning auf handschriftlichen Ziffern: Locally Linear Embedding, Isomap…
Dimensionsreduktion mit Neighborhood Components Analysis