KBinsDiscretizer#
- class sklearn.preprocessing.KBinsDiscretizer(n_bins=5, *, encode='onehot', strategy='quantile', quantile_method='warn', dtype=None, subsample=200000, random_state=None)[Quelle]#
Teilt kontinuierliche Daten in Intervalle auf.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.20.
- Parameter:
- n_binsint oder array-ähnlich mit Form (n_features,), Standardwert=5
Die Anzahl der zu erzeugenden Binns. Löst ValueError aus, wenn
n_bins < 2.- encode{‘onehot’, ‘onehot-dense’, ‘ordinal’}, Standardwert=’onehot’
Methode zur Kodierung des transformierten Ergebnisses.
‘onehot’: Kodiert das transformierte Ergebnis mit One-Hot-Kodierung und gibt eine sparse Matrix zurück. Ignorierte Features werden immer nach rechts angehängt.
‘onehot-dense’: Kodiert das transformierte Ergebnis mit One-Hot-Kodierung und gibt ein dichtes Array zurück. Ignorierte Features werden immer nach rechts angehängt.
‘ordinal’: Gibt die Bin-ID als ganzzahligen Wert zurück.
- strategy{‘uniform’, ‘quantile’, ‘kmeans’}, Standardwert=’quantile’
Strategie zur Bestimmung der Breiten der Bins.
‘uniform’: Alle Bins in jedem Feature haben die gleiche Breite.
‘quantile’: Alle Bins in jedem Feature haben die gleiche Anzahl von Punkten.
‘kmeans’: Werte in jedem Bin haben denselben nächsten Zentrum eines 1D-K-Means-Clusters.
Ein Beispiel für die verschiedenen Strategien finden Sie unter: Demonstration der verschiedenen Strategien von KBinsDiscretizer.
- quantile_method{“inverted_cdf”, “averaged_inverted_cdf”,
“closest_observation”, “interpolated_inverted_cdf”, “hazen”, “weibull”, “linear”, “median_unbiased”, “normal_unbiased”}, Standardwert=”linear” Methode, die an die np.percentile-Berechnung übergeben wird, wenn strategy=”quantile” verwendet wird. Nur
averaged_inverted_cdfundinverted_cdfunterstützen die Verwendung vonsample_weight != None, wenn keine Unterabtastung aktiv ist.Hinzugefügt in Version 1.7.
- dtype{np.float32, np.float64}, Standardwert=None
Der gewünschte Datentyp für die Ausgabe. Wenn None, ist der Ausgabedatentyp mit dem Eingabedatentyp konsistent. Nur np.float32 und np.float64 werden unterstützt.
Hinzugefügt in Version 0.24.
- subsampleint oder None, Standardwert=200_000
Maximale Anzahl von Samples, die zur Anpassung des Modells verwendet werden, aus Gründen der rechnerischen Effizienz.
subsample=Nonebedeutet, dass alle Trainingssamples zur Berechnung der Quantile verwendet werden, die die Binning-Schwellenwerte bestimmen. Da die Quantilberechnung auf dem Sortieren jeder Spalte vonXberuht und das Sortieren eine Zeitkomplexität vonn log(n)hat, wird die Unterabtastung bei Datensätzen mit einer sehr großen Anzahl von Samples empfohlen.Geändert in Version 1.3: Der Standardwert von
subsamplewurde vonNoneauf200_000geändert, wennstrategy="quantile".Geändert in Version 1.5: Der Standardwert von
subsamplewurde vonNoneauf200_000geändert, wennstrategy="uniform"oderstrategy="kmeans".- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung für die Unterabtastung. Geben Sie eine Ganzzahl an, um reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg zu erzielen. Siehe den Parameter
subsamplefür weitere Details. Siehe Glossar.Hinzugefügt in Version 1.1.
- Attribute:
- bin_edges_ndarray mit Form (n_features,) von ndarrays
Die Kanten jedes Bins. Enthält Arrays mit unterschiedlichen Formen
(n_bins_, ). Ignorierte Features haben leere Arrays.- n_bins_ndarray mit Form (n_features,), dtype=np.int64
Anzahl der Bins pro Feature. Bins, deren Breite zu klein ist (d. h. <= 1e-8), werden mit einer Warnung entfernt.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
BinarizerKlasse, die zur Binning von Werten als
0oder1basierend auf einem Parameterthresholdverwendet wird.
Anmerkungen
Eine Visualisierung der Diskretisierung auf verschiedenen Datensätzen finden Sie unter Feature-Diskretisierung. Zur Auswirkung der Diskretisierung auf lineare Modelle siehe: Verwendung von KBinsDiscretizer zur Diskretisierung kontinuierlicher Features.
In den Bin-Kanten für Feature
iwerden der erste und letzte Wert nur fürinverse_transformverwendet. Während der Transformation werden die Bin-Kanten erweitert aufnp.concatenate([-np.inf, bin_edges_[i][1:-1], np.inf])
Sie können
KBinsDiscretizermitColumnTransformerkombinieren, wenn Sie nur einen Teil der Features vorverarbeiten möchten.KBinsDiscretizerkann konstante Features erzeugen (z. B. wennencode = 'onehot'und bestimmte Bins keine Daten enthalten). Diese Features können mit Algorithmen zur Feature-Auswahl entfernt werden (z. B.VarianceThreshold).Beispiele
>>> from sklearn.preprocessing import KBinsDiscretizer >>> X = [[-2, 1, -4, -1], ... [-1, 2, -3, -0.5], ... [ 0, 3, -2, 0.5], ... [ 1, 4, -1, 2]] >>> est = KBinsDiscretizer( ... n_bins=3, encode='ordinal', strategy='uniform' ... ) >>> est.fit(X) KBinsDiscretizer(...) >>> Xt = est.transform(X) >>> Xt array([[ 0., 0., 0., 0.], [ 1., 1., 1., 0.], [ 2., 2., 2., 1.], [ 2., 2., 2., 2.]])
Manchmal kann es nützlich sein, die Daten zurück in den ursprünglichen Feature-Raum zu konvertieren. Die Funktion
inverse_transformkonvertiert die gebinnten Daten zurück in den ursprünglichen Feature-Raum. Jeder Wert wird gleich dem Mittelwert der beiden Bin-Kanten sein.>>> est.bin_edges_[0] array([-2., -1., 0., 1.]) >>> est.inverse_transform(Xt) array([[-1.5, 1.5, -3.5, -0.5], [-0.5, 2.5, -2.5, -0.5], [ 0.5, 3.5, -1.5, 0.5], [ 0.5, 3.5, -1.5, 1.5]])
Obwohl dieser Vorverarbeitungsschritt eine Optimierung sein kann, ist es wichtig zu beachten, dass das von
inverse_transformzurückgegebene Array intern den Typnp.float64odernp.float32hat, was durch das Eingabeargumentdtypebestimmt wird. Dies kann den Speicherbedarf des Arrays drastisch erhöhen. Sehen Sie sich das Beispiel zur Vektorisierung an, bei demKBinsDescretizerzur Clusterbildung des Bildes in Bins verwendet wird und die Größe des Bildes um das 8-fache erhöht.- fit(X, y=None, sample_weight=None)[Quelle]#
Passt den Schätzer an.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Zu diskretisierende Daten.
- yNone
Ignoriert. Dieser Parameter existiert nur zur Kompatibilität mit
Pipeline.- sample_weightndarray mit Form (n_samples,)
Enthält Gewichtungswerte, die jedem Sample zugeordnet werden.
Hinzugefügt in Version 1.3.
Geändert in Version 1.7: Unterstützung für strategy=”uniform” hinzugefügt.
- Gibt zurück:
- selfobject
Gibt die Instanz selbst zurück.
- fit_transform(X, y=None, **fit_params)[Quelle]#
An Daten anpassen, dann transformieren.
Passt den Transformer an
Xundymit optionalen Parameternfit_paramsan und gibt eine transformierte Version vonXzurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabestichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs), Standardwert=None
Zielwerte (None für unüberwachte Transformationen).
- **fit_paramsdict
Zusätzliche Fit-Parameter. Nur übergeben, wenn der Estimator zusätzliche Parameter in seiner
fit-Methode akzeptiert.
- Gibt zurück:
- X_newndarray array der Form (n_samples, n_features_new)
Transformiertes Array.
- get_feature_names_out(input_features=None)[Quelle]#
Gibt die Ausgabefeature-Namen zurück.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
Wenn
input_featuresNoneist, werdenfeature_names_in_als Merkmalnamen verwendet. Wennfeature_names_in_nicht definiert ist, werden die folgenden Eingabemerkmalsnamen generiert:["x0", "x1", ..., "x(n_features_in_ - 1)"].Wenn
input_featuresein Array-ähnliches Objekt ist, mussinput_featuresmitfeature_names_in_übereinstimmen, wennfeature_names_in_definiert ist.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X)[Quelle]#
Transformiert diskretisierte Daten zurück in den ursprünglichen Feature-Raum.
Beachten Sie, dass diese Funktion die Originaldaten aufgrund der Diskretisierungsrundung nicht wiederherstellt.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Transformierte Daten im Bin-Raum.
- Gibt zurück:
- X_originalndarray, dtype={np.float32, np.float64}
Daten im ursprünglichen Feature-Raum.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KBinsDiscretizer[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(X)[Quelle]#
Diskretisiert die Daten.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Zu diskretisierende Daten.
- Gibt zurück:
- Xt{ndarray, sparse matrix}, dtype={np.float32, np.float64}
Daten im Bin-Raum. Wird eine sparse Matrix sein, wenn
self.encode='onehot', andernfalls ein ndarray.
Galeriebeispiele#

Poisson-Regression und nicht-normale Verlustfunktion

Verwendung von KBinsDiscretizer zur Diskretisierung kontinuierlicher Merkmale

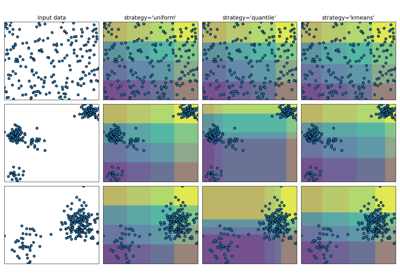
Demonstration der verschiedenen Strategien von KBinsDiscretizer

