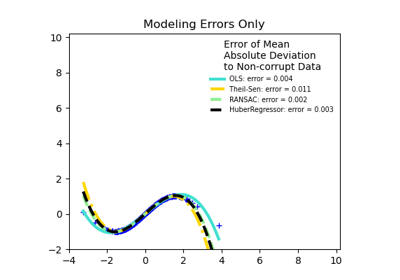
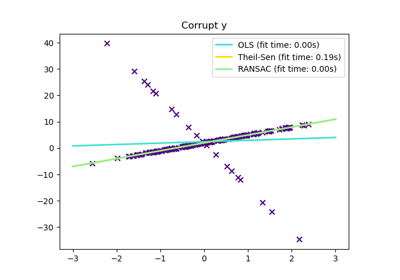
TheilSenRegressor#
- class sklearn.linear_model.TheilSenRegressor(*, fit_intercept=True, max_subpopulation=10000.0, n_subsamples=None, max_iter=300, tol=0.001, random_state=None, n_jobs=None, verbose=False)[Quelle]#
Theil-Sen Estimator: robuster multivariater Regressionsmodell.
Der Algorithmus berechnet Least-Squares-Lösungen auf Teilmengen der Größe n_subsamples der Stichproben in X. Jeder Wert von n_subsamples zwischen der Anzahl der Merkmale und der Anzahl der Stichproben führt zu einem Schätzer mit einem Kompromiss zwischen Robustheit und Effizienz. Da die Anzahl der Least-Squares-Lösungen "n_samples choose n_subsamples" beträgt, kann sie extrem groß sein und daher mit max_subpopulation begrenzt werden. Wenn diese Grenze erreicht ist, werden die Teilmengen zufällig ausgewählt. In einem letzten Schritt wird der räumliche Median (oder L1-Median) aller Least-Squares-Lösungen berechnet.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- fit_interceptbool, Standardwert=True
Ob der Achsenabschnitt für dieses Modell berechnet werden soll. Wenn auf false gesetzt, wird kein Achsenabschnitt für die Berechnungen verwendet.
- max_subpopulationint, default=1e4
Anstatt mit einer Menge der Kardinalität „n choose k“ zu rechnen, wobei n die Anzahl der Stichproben und k die Anzahl der Teilstichproben (mindestens die Anzahl der Merkmale) ist, wird nur eine stochastische Teilpopulation einer gegebenen maximalen Größe berücksichtigt, wenn „n choose k“ größer als max_subpopulation ist. Für andere als kleine Problemgrößen bestimmt dieser Parameter den Speicherverbrauch und die Laufzeit, wenn n_subsamples nicht geändert wird. Beachten Sie, dass der Datentyp int sein sollte, aber auch Gleitkommazahlen wie 1e4 akzeptiert werden können.
- n_subsamplesint, default=None
Anzahl der Stichproben zur Berechnung der Parameter. Dies ist mindestens die Anzahl der Merkmale (plus 1, wenn fit_intercept=True) und maximal die Anzahl der Stichproben. Eine niedrigere Zahl führt zu einem höheren Zerfallspunkt und einer geringen Effizienz, während eine hohe Zahl zu einem niedrigen Zerfallspunkt und einer hohen Effizienz führt. Wenn None, wird die minimale Anzahl von Teilstichproben genommen, die maximale Robustheit gewährleistet. Wenn n_subsamples auf n_samples gesetzt ist, ist Theil-Sen identisch mit der kleinsten Quadrate.
- max_iterint, Standard=300
Maximale Anzahl von Iterationen für die Berechnung des räumlichen Medians.
- tolfloat, Standard=1e-3
Toleranz bei der Berechnung des räumlichen Medians.
- random_stateint, RandomState-Instanz oder None, default=None
Eine Zufallszahlengenerator-Instanz zur Definition des Zustands des Zufallspermutationsgenerators. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- n_jobsint, default=None
Anzahl der CPUs, die während der Kreuzvalidierung verwendet werden sollen.
Nonebedeutet 1, außer in einemjoblib.parallel_backend-Kontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.- verbosebool, default=False
Verbose-Modus beim Anpassen des Modells.
- Attribute:
- coef_ndarray von Form (n_features,)
Koeffizienten des Regressionsmodells (Median der Verteilung).
- intercept_float
Geschätzter Achsenabschnitt des Regressionsmodells.
- breakdown_float
Angenäherter Zerfallspunkt.
- n_iter_int
Anzahl der für den räumlichen Median benötigten Iterationen.
- n_subpopulation_int
Anzahl der berücksichtigten Kombinationen aus „n choose k“, wobei n die Anzahl der Stichproben und k die Anzahl der Teilstichproben ist.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
HuberRegressorLineares Regressionsmodell, das robust gegenüber Ausreißern ist.
RANSACRegressorRANSAC (RANdom SAmple Consensus) Algorithmus.
SGDRegressorAngepasst durch Minimierung eines regulierten empirischen Verlusts mit SGD.
Referenzen
Theil-Sen Estimators in a Multiple Linear Regression Model, 2009 Xin Dang, Hanxiang Peng, Xueqin Wang und Heping Zhang http://home.olemiss.edu/~xdang/papers/MTSE.pdf
Beispiele
>>> from sklearn.linear_model import TheilSenRegressor >>> from sklearn.datasets import make_regression >>> X, y = make_regression( ... n_samples=200, n_features=2, noise=4.0, random_state=0) >>> reg = TheilSenRegressor(random_state=0).fit(X, y) >>> reg.score(X, y) 0.9884 >>> reg.predict(X[:1,]) array([-31.5871])
- fit(X, y)[Quelle]#
Lineares Modell anpassen.
- Parameter:
- Xndarray der Form (n_samples, n_features)
Trainingsdaten.
- yndarray der Form (n_samples,)
Zielwerte.
- Gibt zurück:
- selfgibt eine Instanz von self zurück.
Angepasster
TheilSenRegressor-Schätzer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersage mit dem linearen Modell.
- Parameter:
- Xarray-like oder sparse matrix, Form (n_samples, n_features)
Stichproben.
- Gibt zurück:
- Carray, Form (n_samples,)
Gibt vorhergesagte Werte zurück.
- score(X, y, sample_weight=None)[Quelle]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmtheitskoeffizient \(R^2\) ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen ist
((y_true - y_pred)** 2).sum()und \(v\) die Summe der quadrierten Abweichungen vom Mittelwert ist((y_true - y_true.mean()) ** 2).sum(). Der bestmögliche Score ist 1,0 und er kann negativ sein (weil das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den Erwartungswert vonyvorhersagt, unabhängig von den Eingabemerkmalen, würde einen \(R^2\)-Score von 0,0 erzielen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der beim Aufruf von
scoreauf einem Regressor verwendet wird, verwendetmultioutput='uniform_average'ab Version 0.23, um konsistent mit dem Standardwert vonr2_scorezu sein. Dies beeinflusst diescore-Methode aller Multi-Output-Regressoren (außerMultiOutputRegressor).
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') TheilSenRegressor[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.