accuracy_score#
- sklearn.metrics.accuracy_score(y_true, y_pred, *, normalize=True, sample_weight=None)[Quelle]#
Genauigkeits-Klassifikationsergebnis.
Bei der Multilabel-Klassifizierung berechnet diese Funktion die Subset-Genauigkeit: die Menge der für eine Stichprobe vorhergesagten Labels muss *exakt* mit der entsprechenden Menge der Labels in y_true übereinstimmen.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- y_true1D Array-ähnlich oder Label-Indikator-Array / Sparse Matrix
Grundwahrheits- (korrekte) Labels. Dünnbesetzte Matrizen werden nur unterstützt, wenn die Labels vom Typ Multilabel sind.
- y_pred1D Array-ähnlich oder Label-Indikator-Array / Sparse Matrix
Vorhergesagte Labels, wie sie von einem Klassifikator zurückgegeben werden. Dünnbesetzte Matrizen werden nur unterstützt, wenn die Labels vom Typ Multilabel sind.
- normalizebool, default=True
Wenn
False, wird die Anzahl der korrekt klassifizierten Stichproben zurückgegeben. Andernfalls wird der Anteil der korrekt klassifizierten Stichproben zurückgegeben.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Wenn
normalize == True, wird der Anteil der korrekt klassifizierten Stichproben zurückgegeben, andernfalls die Anzahl der korrekt klassifizierten Stichproben.Die beste Leistung ist 1.0 mit
normalize == Trueund die Anzahl der Stichproben mitnormalize == False.
Siehe auch
balanced_accuracy_scoreBerechnet die ausgewogene Genauigkeit zur Behandlung unausgeglichener Datensätze.
jaccard_scoreBerechnet den Jaccard-Ähnlichkeitskoeffizienten-Score.
hamming_lossBerechnet den durchschnittlichen Hamming-Verlust oder die Hamming-Distanz zwischen zwei Stichprobensätzen.
zero_one_lossBerechnet den Null-Eins-Klassifizierungsverlust. Standardmäßig gibt die Funktion den Prozentsatz der fehlerhaft vorhergesagten Teilmengen zurück.
Beispiele
>>> from sklearn.metrics import accuracy_score >>> y_pred = [0, 2, 1, 3] >>> y_true = [0, 1, 2, 3] >>> accuracy_score(y_true, y_pred) 0.5 >>> accuracy_score(y_true, y_pred, normalize=False) 2.0
Im Multilabel-Fall mit binären Label-Indikatoren
>>> import numpy as np >>> accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2))) 0.5
Galeriebeispiele#
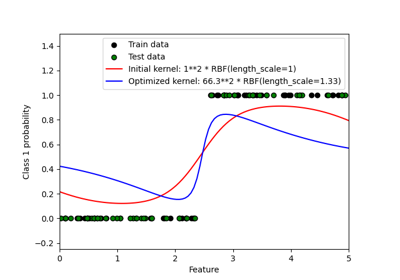
Probabilistische Vorhersagen mit Gauß-Prozess-Klassifikation (GPC)
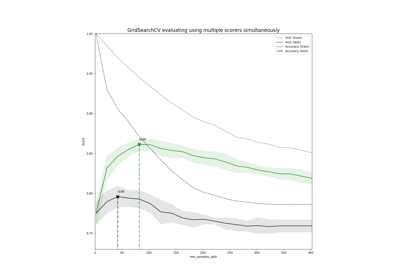
Demonstration von Multi-Metrik-Bewertung auf cross_val_score und GridSearchCV

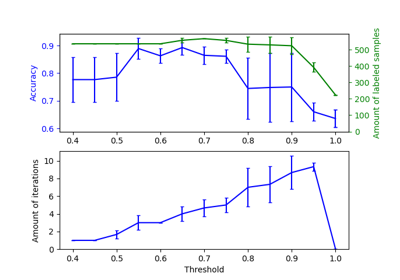
Auswirkung der Änderung des Schwellenwerts für Self-Training
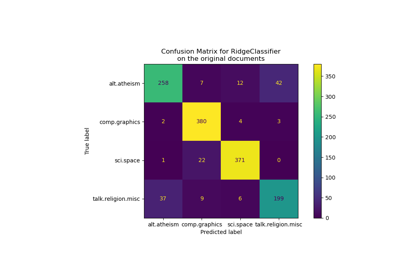
Klassifikation von Textdokumenten mit spärlichen Merkmalen