CountVectorizer#
- class sklearn.feature_extraction.text.CountVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.int64'>)[Quelle]#
Konvertiert eine Sammlung von Textdokumenten in eine Matrix von Token-Zählungen.
Diese Implementierung erzeugt eine spärliche Darstellung der Zählungen mithilfe von scipy.sparse.csr_matrix.
Wenn Sie kein a-priori-Wörterbuch bereitstellen und keinen Analysator verwenden, der eine Art von Merkmalsauswahl durchführt, dann ist die Anzahl der Merkmale gleich der durch die Analyse der Daten gefundenen Vokabulargröße.
Für einen Effizienzvergleich der verschiedenen Merkmalsextraktoren siehe Vergleich von HashingVectorizer und DictVectorizer.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- input{‘filename’, ‘file’, ‘content’}, standardmäßig=’content’
Wenn
'filename', wird erwartet, dass die als Argument an fit übergebene Sequenz eine Liste von Dateinamen ist, die gelesen werden müssen, um den zu analysierenden Rohinhalt abzurufen.Wenn
'file', müssen die Sequenzelemente eine „read“-Methode (dateiähnliches Objekt) haben, die aufgerufen wird, um die Bytes im Speicher abzurufen.Wenn
'content', wird erwartet, dass die Eingabe eine Sequenz von Elementen ist, die vom Typ String oder Byte sein können.
- encodingstr, standardmäßig=’utf-8’
Wenn Bytes oder Dateien zur Analyse übergeben werden, wird diese Kodierung zum Dekodieren verwendet.
- decode_error{‘strict’, ‘ignore’, ‘replace’}, standardmäßig=’strict’
Anweisung, was zu tun ist, wenn eine Byte-Sequenz zur Analyse übergeben wird, die Zeichen enthält, die nicht zur gegebenen
encodinggehören. Standardmäßig ist dies „strict“, was bedeutet, dass ein UnicodeDecodeError ausgelöst wird. Andere Werte sind „ignore“ und „replace“.- strip_accents{‘ascii’, ‘unicode’} oder aufrufbar, standardmäßig=None
Entfernt Akzente und führt während der Vorverarbeitung eine weitere Zeichennormalisierung durch. „ascii“ ist eine schnelle Methode, die nur für Zeichen funktioniert, die eine direkte ASCII-Entsprechung haben. „unicode“ ist eine etwas langsamere Methode, die für beliebige Zeichen funktioniert. None (Standard) bedeutet, dass keine Zeichennormalisierung durchgeführt wird.
Sowohl „ascii“ als auch „unicode“ verwenden die NFKD-Normalisierung von
unicodedata.normalize.- lowercasebool, standardmäßig=True
Konvertiert alle Zeichen vor der Tokenisierung in Kleinbuchstaben.
- preprocessoraufrufbar, standardmäßig=None
Überschreibt die Vorverarbeitungsstufe (strip_accents und lowercase) unter Beibehaltung der Schritte für Tokenisierung und N-Gramm-Generierung. Gilt nur, wenn
analyzernicht aufrufbar ist.- tokenizeraufrufbar, standardmäßig=None
Überschreibt den Zeichenketten-Tokenisierungsschritt unter Beibehaltung der Schritte für Vorverarbeitung und N-Gramm-Generierung. Gilt nur, wenn
analyzer == 'word'.- stop_words{‘english’}, list, standardmäßig=None
Wenn „english“, wird eine integrierte Stoppwortliste für Englisch verwendet. Es gibt mehrere bekannte Probleme mit „english“, und Sie sollten eine Alternative in Betracht ziehen (siehe Verwendung von Stoppwörtern).
Wenn eine Liste, wird angenommen, dass diese Liste Stoppwörter enthält, die alle aus den resultierenden Tokens entfernt werden. Gilt nur, wenn
analyzer == 'word'.Wenn None, werden keine Stoppwörter verwendet. In diesem Fall kann die Einstellung von
max_dfauf einen höheren Wert, wie z. B. im Bereich von (0.7, 1.0), dazu verwendet werden, Stoppwörter basierend auf der Dokumentfrequenz von Begriffen innerhalb des Korpus automatisch zu erkennen und zu filtern.- token_patternstr oder None, standardmäßig=r”(?u)\b\w\w+\b”
Regulärer Ausdruck, der angibt, was ein „Token“ ausmacht, nur verwendet, wenn
analyzer == 'word'. Der Standard-RegExp wählt Tokens aus 2 oder mehr alphanumerischen Zeichen aus (Satzzeichen werden vollständig ignoriert und immer als Token-Trennung behandelt).Wenn es eine Erfassungsgruppe im token_pattern gibt, dann wird der Inhalt der erfassten Gruppe und nicht der gesamte Treffer zum Token. Es ist höchstens eine Erfassungsgruppe zulässig.
- ngram_rangeTupel (min_n, max_n), standardmäßig=(1, 1)
Die untere und obere Grenze des Bereichs von n-Werten für verschiedene Wort-n-Gramme oder Zeichen-n-Gramme, die extrahiert werden sollen. Alle n-Werte, so dass min_n <= n <= max_n, werden verwendet. Zum Beispiel bedeutet ein
ngram_rangevon(1, 1)nur Unigramme,(1, 2)bedeutet Unigramme und Bigramme, und(2, 2)bedeutet nur Bigramme. Gilt nur, wennanalyzernicht aufrufbar ist.- analyzer{‘word’, ‘char’, ‘char_wb’} oder aufrufbar, standardmäßig=’word’
Ob das Merkmal aus Wort-n-Grammen oder Zeichen-n-Grammen gebildet werden soll. Die Option „char_wb“ erstellt Zeichen-n-Gramme nur aus Text innerhalb von Wortgrenzen; n-Gramme an den Rändern von Wörtern werden mit Leerzeichen aufgefüllt.
Wenn ein Aufrufbares übergeben wird, wird es verwendet, um die Sequenz von Merkmalen aus den rohen, unverarbeiteten Eingaben zu extrahieren.
Geändert in Version 0.21.
Seit v0.21 werden, wenn
inputfilenameoderfileist, die Daten zuerst aus der Datei gelesen und dann an den gegebenen aufrufbaren Analysator übergeben.- max_dffloat im Bereich [0.0, 1.0] oder int, standardmäßig=1.0
Beim Erstellen des Vokabulars werden Begriffe ignoriert, die eine Dokumenthäufigkeit haben, die strikt höher ist als der gegebene Schwellenwert (korpuspezifische Stoppwörter). Wenn float, repräsentiert der Parameter einen Anteil der Dokumente, bei ganzen Zahlen absolute Zählungen. Dieser Parameter wird ignoriert, wenn vocabulary nicht None ist.
- min_dffloat im Bereich [0.0, 1.0] oder int, standardmäßig=1
Beim Erstellen des Vokabulars werden Begriffe ignoriert, die eine Dokumenthäufigkeit haben, die strikt niedriger ist als der gegebene Schwellenwert. Dieser Wert wird in der Literatur auch als Cut-off bezeichnet. Wenn float, repräsentiert der Parameter einen Anteil der Dokumente, bei ganzen Zahlen absolute Zählungen. Dieser Parameter wird ignoriert, wenn vocabulary nicht None ist.
- max_featuresint, standardmäßig=None
Wenn nicht None, wird ein Vokabular erstellt, das nur die Top
max_featuresberücksichtigt, geordnet nach der Begriffshäufigkeit im gesamten Korpus. Andernfalls werden alle Merkmale verwendet.Dieser Parameter wird ignoriert, wenn vocabulary nicht None ist.
- vocabularyMapping oder iterierbar, standardmäßig=None
Entweder ein Mapping (z. B. ein Dict), bei dem die Schlüssel Begriffe und die Werte Indizes in der Merkmalsmatrix sind, oder ein iterierbares Objekt über Begriffe. Wenn nicht angegeben, wird ein Vokabular aus den Eingabedokumenten bestimmt. Die Indizes im Mapping sollten nicht wiederholt werden und sollten keine Lücke zwischen 0 und dem größten Index aufweisen.
- binarybool, standardmäßig=False
Wenn True, werden alle von Null verschiedenen Zählungen auf 1 gesetzt. Dies ist nützlich für diskrete probabilistische Modelle, die binäre Ereignisse anstelle von ganzzahligen Zählungen modellieren.
- dtypedtype, standardmäßig=np.int64
Typ der von fit_transform() oder transform() zurückgegebenen Matrix.
- Attribute:
- vocabulary_dict
Eine Zuordnung von Begriffen zu Merkmalsindizes.
- fixed_vocabulary_bool
True, wenn eine feste Zuordnung von Begriffen zu Indizes vom Benutzer bereitgestellt wird.
Siehe auch
HashingVectorizerKonvertiert eine Sammlung von Textdokumenten in eine Matrix von Token-Zählungen.
TfidfVectorizerKonvertiert eine Sammlung von Rohdokumenten in eine Matrix von TF-IDF-Merkmalen.
Beispiele
>>> from sklearn.feature_extraction.text import CountVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = CountVectorizer() >>> X = vectorizer.fit_transform(corpus) >>> vectorizer.get_feature_names_out() array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'], ...) >>> print(X.toarray()) [[0 1 1 1 0 0 1 0 1] [0 2 0 1 0 1 1 0 1] [1 0 0 1 1 0 1 1 1] [0 1 1 1 0 0 1 0 1]] >>> vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2)) >>> X2 = vectorizer2.fit_transform(corpus) >>> vectorizer2.get_feature_names_out() array(['and this', 'document is', 'first document', 'is the', 'is this', 'second document', 'the first', 'the second', 'the third', 'third one', 'this document', 'this is', 'this the'], ...) >>> print(X2.toarray()) [[0 0 1 1 0 0 1 0 0 0 0 1 0] [0 1 0 1 0 1 0 1 0 0 1 0 0] [1 0 0 1 0 0 0 0 1 1 0 1 0] [0 0 1 0 1 0 1 0 0 0 0 0 1]]
- build_analyzer()[Quelle]#
Gibt eine aufrufbare Funktion zurück, um Eingabedaten zu verarbeiten.
Die aufrufbare Funktion kümmert sich um Vorverarbeitung, Tokenisierung und N-Gramm-Generierung.
- Gibt zurück:
- analyzer: callable
Eine Funktion zur Verarbeitung von Vorverarbeitung, Tokenisierung und N-Gramm-Generierung.
- build_preprocessor()[Quelle]#
Gibt eine Funktion zurück, die den Text vor der Tokenisierung vorverarbeitet.
- Gibt zurück:
- preprocessor: callable
Eine Funktion, die den Text vor der Tokenisierung vorverarbeitet.
- build_tokenizer()[Quelle]#
Gibt eine Funktion zurück, die einen String in eine Sequenz von Tokens aufteilt.
- Gibt zurück:
- tokenizer: callable
Eine Funktion, die einen String in eine Sequenz von Tokens aufteilt.
- decode(doc)[Quelle]#
Dekodiert die Eingabe in einen String aus Unicode-Symbolen.
Die Dekodierungsstrategie hängt von den Parametern des Vektorisierers ab.
- Parameter:
- docbytes oder str
Der zu dekodierende String.
- Gibt zurück:
- doc: str
Ein String aus Unicode-Symbolen.
- fit(raw_documents, y=None)[Quelle]#
Lernt ein Vokabular-Wörterbuch aller Tokens in den Rohdokumenten.
- Parameter:
- raw_documentsiterierbar
Ein iterierbares Objekt, das entweder String-, Unicode- oder Dateiobjekte erzeugt.
- yNone
Dieser Parameter wird ignoriert.
- Gibt zurück:
- selfobject
Gefitteter Vektorisierer.
- fit_transform(raw_documents, y=None)[Quelle]#
Lernt das Vokabular-Wörterbuch und gibt die Dokument-Term-Matrix zurück.
Dies ist äquivalent zu fit gefolgt von transform, aber effizienter implementiert.
- Parameter:
- raw_documentsiterierbar
Ein iterierbares Objekt, das entweder String-, Unicode- oder Dateiobjekte erzeugt.
- yNone
Dieser Parameter wird ignoriert.
- Gibt zurück:
- XArray der Form (n_samples, n_features)
Dokument-Term-Matrix.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- get_stop_words()[Quelle]#
Erstellt oder ruft die effektive Stoppwortliste ab.
- Gibt zurück:
- stop_words: list oder None
Eine Liste von Stoppwörtern.
- inverse_transform(X)[Quelle]#
Gibt Begriffe pro Dokument mit Nicht-Null-Einträgen in X zurück.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Dokument-Term-Matrix.
- Gibt zurück:
- X_originalListe von Arrays der Form (n_samples,)
Liste von Arrays von Begriffen.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(raw_documents)[Quelle]#
Transformiert Dokumente in eine Dokument-Term-Matrix.
Extrahiert Begriffszählungen aus Roh-Textdokumenten unter Verwendung des mit fit gelernten Vokabulars oder des im Konstruktor bereitgestellten.
- Parameter:
- raw_documentsiterierbar
Ein iterierbares Objekt, das entweder String-, Unicode- oder Dateiobjekte erzeugt.
- Gibt zurück:
- Xspärliche Matrix der Form (n_samples, n_features)
Dokument-Term-Matrix.
Galeriebeispiele#
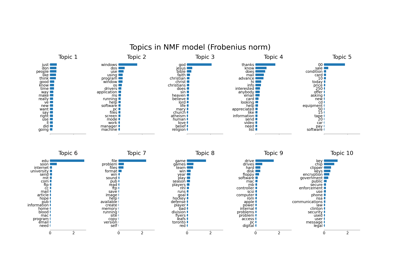
Themenextraktion mit Non-negative Matrix Factorization und Latent Dirichlet Allocation
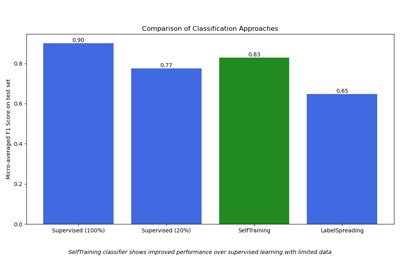
Semi-überwachte Klassifikation auf einem Textdatensatz