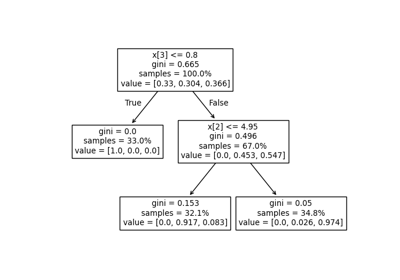
plot_tree#
- sklearn.tree.plot_tree(decision_tree, *, max_depth=None, feature_names=None, class_names=None, label='all', filled=False, impurity=True, node_ids=False, proportion=False, rounded=False, precision=3, ax=None, fontsize=None)[Quelle]#
Plottet einen Entscheidungsbaum.
Die angezeigten Stichprobenerhebungen werden mit eventuell vorhandenen Stichprobengewichten gewichtet.
Die Visualisierung wird automatisch an die Größe der Achse angepasst. Verwenden Sie die Argumente
figsizeoderdpivonplt.figure, um die Größe des Renderings zu steuern.Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.21.
- Parameter:
- decision_treeEntscheidungsbaum-Regressor oder -Klassifikator
Der zu plottende Entscheidungsbaum.
- max_depthint, Standard=None
Die maximale Tiefe der Darstellung. Wenn None, wird der Baum vollständig generiert.
- feature_namesArray-ähnlich von str, Standard=None
Namen jedes der Merkmale. Wenn None, werden generische Namen verwendet ("x[0]", "x[1]", ...).
- class_namesArray-ähnlich von str oder True, Standard=None
Namen jeder der Zielklassen in aufsteigender numerischer Reihenfolge. Nur relevant für Klassifizierung und nicht für Multi-Output unterstützt. Wenn
True, wird eine symbolische Darstellung des Klassennamens angezeigt.- label{‘all’, ‘root’, ‘none’}, Standard=’all’
Ob informative Bezeichnungen für Unreinheit usw. angezeigt werden sollen. Optionen sind 'all', um sie an jedem Knoten anzuzeigen, 'root', um sie nur am obersten Wurzelknoten anzuzeigen, oder 'none', um sie an keinem Knoten anzuzeigen.
- filledbool, Standard=False
Wenn auf
Truegesetzt, werden Knoten eingefärbt, um die Mehrheitsklasse für die Klassifizierung, die Extremwerte für die Regression oder die Reinheit des Knotens für Multi-Output anzuzeigen.- impuritybool, Standard=True
Wenn auf
Truegesetzt, wird die Unreinheit an jedem Knoten angezeigt.- node_idsbool, Standard=False
Wenn auf
Truegesetzt, wird die ID-Nummer an jedem Knoten angezeigt.- proportionbool, Standard=False
Wenn auf
Truegesetzt, wird die Anzeige von 'values' und/oder 'samples' in Proportionen bzw. Prozente geändert.- roundedbool, Standard=False
Wenn auf
Truegesetzt, werden Knotenboxen mit abgerundeten Ecken gezeichnet und Helvetica-Schriften anstelle von Times-Roman verwendet.- precisionint, Standard=3
Anzahl der Dezimalstellen für Gleitkommazahlen in den Werten der Attribute impurity, threshold und value jedes Knotens.
- axmatplotlib-Achse, Standard=None
Zu plottende Achsen. Wenn None, wird die aktuelle Achse verwendet. Vorhandener Inhalt wird gelöscht.
- fontsizeint, Standard=None
Schriftgröße des Textes. Wenn None, wird die Größe automatisch bestimmt, um in die Abbildung zu passen.
- Gibt zurück:
- annotationsListe von Künstlern
Liste, die die Künstler für die Annotationsboxen enthält, aus denen der Baum besteht.
Beispiele
>>> from sklearn.datasets import load_iris >>> from sklearn import tree
>>> clf = tree.DecisionTreeClassifier(random_state=0) >>> iris = load_iris()
>>> clf = clf.fit(iris.data, iris.target) >>> tree.plot_tree(clf) [...]
Galeriebeispiele#
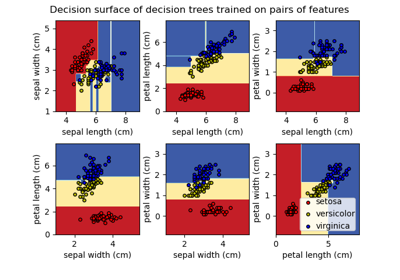
Entscheidungsfläche von Entscheidungsbäumen, trainiert auf dem Iris-Datensatz, plotten