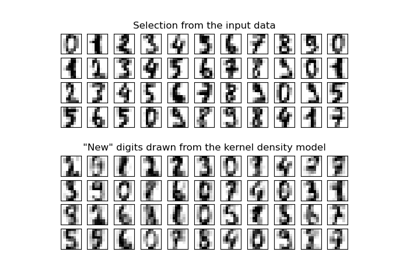
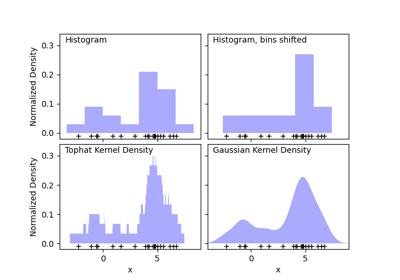
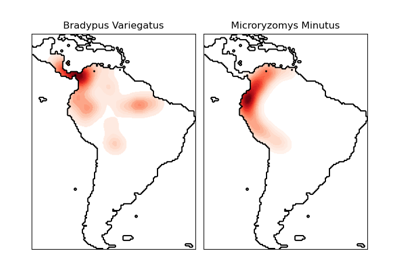
KernelDensity#
- class sklearn.neighbors.KernelDensity(*, bandwidth=1.0, algorithm='auto', kernel='gaussian', metric='euclidean', atol=0, rtol=0, breadth_first=True, leaf_size=40, metric_params=None)[Quelle]#
Kernel-Dichte-Schätzung.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- bandwidthfloat oder {“scott”, “silverman”}, Standard=1.0
Die Bandbreite des Kernels. Wenn bandwidth ein Float ist, definiert es die Bandbreite des Kernels. Wenn bandwidth eine Zeichenkette ist, wird eine der Schätzmethoden implementiert.
- algorithm{‘kd_tree’, ‘ball_tree’, ‘auto’}, Standard=’auto’
Der zu verwendende Baum-Algorithmus.
- kernel{‘gaussian’, ‘tophat’, ‘epanechnikov’, ‘exponential’, ‘linear’, ‘cosine’}, Standard=’gaussian’
Der zu verwendende Kernel.
- metricstr, Standard=’euclidean’
Zu verwendende Metrik für die Distanzberechnung. Siehe die Dokumentation von scipy.spatial.distance und die in
distance_metricsaufgeführten Metriken für gültige Metrikwerte.Nicht alle Metriken sind mit allen Algorithmen gültig: siehe die Dokumentation von
BallTreeundKDTree. Beachten Sie, dass die Normalisierung der Dichteausgabe nur für die euklidische Distanzmetrik korrekt ist.- atolFloat, Standard=0
Die gewünschte absolute Toleranz des Ergebnisses. Eine größere Toleranz führt im Allgemeinen zu einer schnelleren Ausführung.
- rtolfloat, Standard=0
Die gewünschte relative Toleranz des Ergebnisses. Eine größere Toleranz führt im Allgemeinen zu einer schnelleren Ausführung.
- breadth_firstbool, Standard=True
Wenn wahr (Standard), wird ein Breitensuche-Ansatz für das Problem verwendet. Andernfalls wird ein Tiefensuche-Ansatz verwendet.
- leaf_sizeint, Standard=40
Geben Sie die Blattgröße des zugrunde liegenden Baums an. Details finden Sie unter
BallTreeoderKDTree.- metric_paramsdict, Standard=None
Zusätzliche Parameter, die an den Baum übergeben werden, um sie mit der Metrik zu verwenden. Weitere Informationen finden Sie in der Dokumentation von
BallTreeoderKDTree.
- Attribute:
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- tree_
BinaryTreeInstanz Der Baum-Algorithmus für schnelle N-Punkt-Probleme.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.- bandwidth_float
Wert der Bandbreite, direkt durch den Parameter bandwidth gegeben oder mit der Methode ‘scott’ oder ‘silverman’ geschätzt.
Hinzugefügt in Version 1.0.
Siehe auch
sklearn.neighbors.KDTreeK-dimensionaler Baum für schnelle N-Punkt-Probleme.
sklearn.neighbors.BallTreeBall-Baum für schnelle N-Punkt-Probleme.
Beispiele
Berechnet eine Gaußsche Kerndichteschätzung mit fester Bandbreite.
>>> from sklearn.neighbors import KernelDensity >>> import numpy as np >>> rng = np.random.RandomState(42) >>> X = rng.random_sample((100, 3)) >>> kde = KernelDensity(kernel='gaussian', bandwidth=0.5).fit(X) >>> log_density = kde.score_samples(X[:3]) >>> log_density array([-1.52955942, -1.51462041, -1.60244657])
- fit(X, y=None, sample_weight=None)[Quelle]#
Anpassen des Kerndichte-Modells an die Daten.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Liste von n_dimensions-dimensionalen Datenpunkten. Jede Zeile entspricht einem einzelnen Datenpunkt.
- yNone
Ignoriert. Dieser Parameter existiert nur zur Kompatibilität mit
Pipeline.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Liste der Stichprobengewichte, die den Daten X zugeordnet sind.
Hinzugefügt in Version 0.20.
- Gibt zurück:
- selfobject
Gibt die Instanz selbst zurück.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- sample(n_samples=1, random_state=None)[Quelle]#
Generiere zufällige Stichproben aus dem Modell.
Derzeit ist dies nur für Gaußsche und Tophat-Kernel implementiert.
- Parameter:
- n_samplesint, Standard=1
Anzahl der zu generierenden Stichproben.
- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung zur Erzeugung zufälliger Stichproben. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- Gibt zurück:
- Xarray-like der Form (n_samples, n_features)
Liste von Stichproben.
- score(X, y=None)[Quelle]#
Berechnet die gesamte Log-Wahrscheinlichkeit unter dem Modell.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Liste von n_dimensions-dimensionalen Datenpunkten. Jede Zeile entspricht einem einzelnen Datenpunkt.
- yNone
Ignoriert. Dieser Parameter existiert nur zur Kompatibilität mit
Pipeline.
- Gibt zurück:
- logprobfloat
Gesamte Log-Wahrscheinlichkeit der Daten in X. Diese wird als Wahrscheinlichkeitsdichte normalisiert, daher sind die Werte für hochdimensionale Daten niedrig.
- score_samples(X)[Quelle]#
Berechnet die Log-Wahrscheinlichkeit jeder Stichprobe unter dem Modell.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eine Menge von Punkten zum Abfragen. Die letzte Dimension sollte mit der Dimension der Trainingsdaten (n_features) übereinstimmen.
- Gibt zurück:
- densityndarray der Form (n_samples,)
Log-Wahrscheinlichkeit jeder Stichprobe in
X. Diese werden als Wahrscheinlichkeitsdichte normalisiert, daher sind die Werte für hochdimensionale Daten niedrig.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KernelDensity[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.