SVC#
- class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)[source]#
C-Support Vector Klassifizierung.
Die Implementierung basiert auf libsvm. Die Trainingszeit skaliert mindestens quadratisch mit der Anzahl der Samples und kann bei mehr als zehntausend Samples unpraktisch werden. Für große Datensätze sollten stattdessen
LinearSVCoderSGDClassifierverwendet werden, möglicherweise nach einemNystroem-Transformer oder anderer Kernel-Approximation.Die Multiklassenunterstützung wird gemäß einem One-vs-One-Schema gehandhabt.
Details zur genauen mathematischen Formulierung der bereitgestellten Kernelfunktionen und wie
gamma,coef0unddegreemiteinander interagieren, finden Sie im entsprechenden Abschnitt der Dokumentation: Kernelfunktionen.Um zu lernen, wie man die Hyperparameter von SVC abstimmt, siehe das folgende Beispiel: Geschachtelte versus nicht geschachtelte Kreuzvalidierung
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- Cfloat, Standardwert=1.0
Regularisierungsparameter. Die Stärke der Regularisierung ist umgekehrt proportional zu C. Muss strikt positiv sein. Die Strafe ist eine quadrierte L2-Strafe. Für eine intuitive Visualisierung der Auswirkungen des Skalierens des Regularisierungsparameters C siehe Skalierung des Regularisierungsparameters für SVCs.
- kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} oder aufrufbar, Standard=’rbf’
Gibt den zu verwendenden Kernel-Typ im Algorithmus an. Wenn keiner angegeben ist, wird ‘rbf’ verwendet. Wenn eine aufrufbare Funktion angegeben ist, wird diese verwendet, um die Kernel-Matrix aus Datenmatrizen vorab zu berechnen; diese Matrix sollte ein Array der Form
(n_samples, n_samples)sein. Für eine intuitive Visualisierung verschiedener Kernel-Typen siehe Klassifikationsgrenzen mit verschiedenen SVM-Kernels plotten.- degreeint, Standard=3
Grad der Polynomkernfunktion (‘poly’). Muss nicht-negativ sein. Wird von allen anderen Kernels ignoriert.
- gamma{‘scale’, ‘auto’} oder float, Standard=’scale’
Kernel-Koeffizient für ‘rbf’, ‘poly’ und ‘sigmoid’.
Wenn
gamma='scale'(Standard) übergeben wird, wird 1 / (n_features * X.var()) als Wert für gamma verwendet,wenn ‘auto’, wird 1 / n_features verwendet
Wenn float, muss nicht-negativ sein.
Geändert in Version 0.22: Der Standardwert von
gammawurde von ‘auto’ auf ‘scale’ geändert.- coef0float, Standard=0.0
Unabhängiger Term in der Kernelfunktion. Er ist nur in ‘poly’ und ‘sigmoid’ signifikant.
- shrinkingbool, Standard=True
Ob die „shrinking“-Heuristik verwendet werden soll. Siehe Benutzerhandbuch.
- probabilitybool, Standard=False
Ob Wahrscheinlichkeitsschätzungen aktiviert werden sollen. Dies muss vor dem Aufruf von
fitaktiviert werden, verlangsamt diese Methode, da sie intern eine 5-fache Kreuzvalidierung verwendet, undpredict_probakann inkonsistent mitpredictsein. Lesen Sie mehr im Benutzerhandbuch.- tolfloat, Standard=1e-3
Toleranz für das Abbruchkriterium.
- cache_sizefloat, Standard=200
Gibt die Größe des Kernel-Caches an (in MB).
- class_weightdict oder ‘balanced’, Standard=None
Setzt den Parameter C der Klasse i auf class_weight[i]*C für SVC. Wenn nicht angegeben, werden alle Klassen als Gewicht eins angenommen. Der Modus „balanced“ verwendet die Werte von y, um die Gewichte automatisch umgekehrt proportional zu den Klassenhäufigkeiten in den Eingabedaten anzupassen, als
n_samples / (n_classes * np.bincount(y)).- verbosebool, default=False
Aktiviert ausführliche Ausgabe. Beachten Sie, dass diese Einstellung eine laufende Prozess-Einstellung in libsvm nutzt, die, wenn sie aktiviert ist, in einem Multithreading-Kontext möglicherweise nicht ordnungsgemäß funktioniert.
- max_iterint, Standard=-1
Harte Obergrenze für Iterationen innerhalb des Solvers oder -1 für keine Obergrenze.
- decision_function_shape{‘ovo’, ‘ovr’}, Standard=’ovr’
Gibt an, ob eine One-vs-Rest (‘ovr‘) Entscheidungsfunktion der Form (n_samples, n_classes) wie bei allen anderen Klassifikatoren zurückgegeben werden soll, oder die ursprüngliche One-vs-One (‘ovo‘) Entscheidungsfunktion von libsvm mit der Form (n_samples, n_classes * (n_classes - 1) / 2). Beachten Sie jedoch, dass intern immer One-vs-One (‘ovo‘) als Multiklassenstrategie zum Trainieren von Modellen verwendet wird; eine OVR-Matrix wird nur aus der OVO-Matrix konstruiert. Der Parameter wird für binäre Klassifizierung ignoriert.
Geändert in Version 0.19: decision_function_shape ist standardmäßig ‘ovr‘.
Hinzugefügt in Version 0.17: decision_function_shape=’ovr‘ wird empfohlen.
Geändert in Version 0.17: decision_function_shape=’ovo‘ und None sind veraltet.
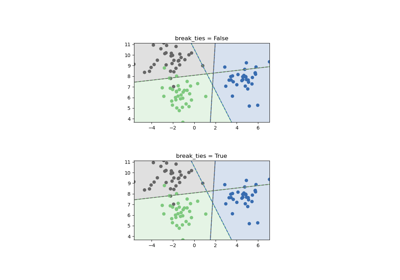
- break_tiesbool, Standard=False
Wenn true,
decision_function_shape='ovr'und die Anzahl der Klassen > 2 ist, wird predict die Unentschieden gemäß den Konfidenzwerten der decision_function auflösen; andernfalls wird die erste Klasse unter den gleichrangigen Klassen zurückgegeben. Bitte beachten Sie, dass das Auflösen von Unentschieden im Vergleich zu einem einfachen predict mit relativ hohen Rechenkosten verbunden ist. Siehe Beispiel zum Auflösen von SVM-Unentschieden für ein Beispiel der Verwendung mitdecision_function_shape='ovr'.Hinzugefügt in Version 0.22.
- random_stateint, RandomState-Instanz oder None, default=None
Steuert die Pseudo-Zufallszahlengenerierung zum Mischen der Daten für Wahrscheinlichkeitsschätzungen. Wird ignoriert, wenn
probabilityFalse ist. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- Attribute:
- class_weight_ndarray der Form (n_classes,)
Multiplikatoren des Parameters C für jede Klasse. Berechnet auf Basis des Parameters
class_weight.- classes_ndarray der Form (n_classes,)
Die Klassenbezeichnungen.
coef_ndarray der Form (n_classes * (n_classes - 1) / 2, n_features)Gewichte, die den Merkmalen zugeordnet sind, wenn
kernel="linear".- dual_coef_ndarray der Form (n_classes -1, n_SV)
Duale Koeffizienten des Support-Vektors in der Entscheidungsfunktion (siehe Mathematische Formulierung), multipliziert mit ihren Zielen. Für Multiklassen sind die Koeffizienten für alle 1-gegen-1-Klassifikatoren. Das Layout der Koeffizienten im Multiklassenfall ist etwas nicht trivial. Details finden Sie im Multiklassenabschnitt des Benutzerhandbuchs.
- fit_status_int
0, wenn korrekt angepasst, 1 andernfalls (löst eine Warnung aus)
- intercept_ndarray der Form (n_classes * (n_classes - 1) / 2,)
Konstanten in der Entscheidungsfunktion.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_iter_ndarray der Form (n_classes * (n_classes - 1) // 2,)
Anzahl der Iterationen, die von der Optimierungsroutine zur Anpassung des Modells ausgeführt wurden. Die Form dieses Attributs hängt von der Anzahl der optimierten Modelle ab, was wiederum von der Anzahl der Klassen abhängt.
Hinzugefügt in Version 1.1.
- support_ndarray der Form (n_SV)
Indizes der Support-Vektoren.
- support_vectors_ndarray der Form (n_SV, n_features)
Support-Vektoren. Ein leeres Array, wenn der Kernel vorab berechnet wurde.
n_support_ndarray der Form (n_classes,), dtype=int32Anzahl der Support-Vektoren pro Klasse.
probA_ndarray der Form (n_classes * (n_classes - 1) / 2)Parameter, der in der Platt-Skalierung gelernt wurde, wenn
probability=True.probB_ndarray der Form (n_classes * (n_classes - 1) / 2)Parameter, der in der Platt-Skalierung gelernt wurde, wenn
probability=True.- shape_fit_tuple von int der Form (n_dimensions_of_X,)
Array-Dimensionen des Trainingsvektors
X.
Siehe auch
Referenzen
Beispiele
>>> import numpy as np >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) >>> y = np.array([1, 1, 2, 2]) >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto')) >>> clf.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]])) [1]
Für einen Vergleich von SVC mit anderen Klassifikatoren siehe: Klassifikationswahrscheinlichkeit plotten.
- decision_function(X)[source]#
Evaluieren Sie die Entscheidungsfunktion für die Samples in X.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt zurück:
- Xndarray der Form (n_samples, n_classes * (n_classes-1) / 2)
Gibt die Entscheidungsfunktion des Samples für jede Klasse im Modell zurück. Wenn decision_function_shape=’ovr‘, hat die Form (n_samples, n_classes).
Anmerkungen
Wenn decision_function_shape=’ovo‘, sind die Funktionswerte proportional zum Abstand der Samples X zur trennenden Hyperebene. Wenn die genauen Abstände benötigt werden, dividieren Sie die Funktionswerte durch die Norm des Gewichtungsvektors (
coef_). Siehe auch diese Frage für weitere Details. Wenn decision_function_shape=’ovr‘, ist die Entscheidungsfunktion eine monotone Transformation der OVO-Entscheidungsfunktion.
- fit(X, y, sample_weight=None)[source]#
Passt das SVM-Modell an die gegebenen Trainingsdaten an.
- Parameter:
- X{array-artig, spärs matrix} der Form (n_samples, n_features) oder (n_samples, n_samples)
Trainingsvektoren, wobei
n_samplesdie Anzahl der Samples undn_featuresdie Anzahl der Merkmale ist. Für kernel="precomputed" hat X die erwartete Form (n_samples, n_samples).- yarray-like von Form (n_samples,)
Zielwerte (Klassenlabels bei Klassifizierung, reelle Zahlen bei Regression).
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Gewichte pro Sample. Skaliert C pro Sample neu. Höhere Gewichte zwingen den Klassifikator, mehr Betonung auf diese Punkte zu legen.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
Anmerkungen
Wenn X und y nicht C-geordnete und zusammenhängende Arrays von np.float64 sind und X keine scipy.sparse.csr_matrix ist, können X und/oder y kopiert werden.
Wenn X ein dichtes Array ist, unterstützen die anderen Methoden keine spärlichen Matrizen als Eingabe.
- get_metadata_routing()[source]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[source]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[source]#
Führt die Klassifizierung für Samples in X durch.
Für ein Ein-Klassen-Modell wird +1 oder -1 zurückgegeben.
- Parameter:
- X{array-artig, spärs matrix} der Form (n_samples, n_features) oder (n_samples_test, n_samples_train)
Für kernel="precomputed" hat X die erwartete Form (n_samples_test, n_samples_train).
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Klassenbezeichnungen für Samples in X.
- predict_log_proba(X)[source]#
Berechnet die Log-Wahrscheinlichkeiten möglicher Ergebnisse für Samples in X.
Das Modell muss Wahrscheinlichkeitsinformationen zur Trainingszeit berechnet haben: fit mit dem Attribut
probabilityauf True gesetzt.- Parameter:
- Xarray-artig der Form (n_samples, n_features) oder (n_samples_test, n_samples_train)
Für kernel="precomputed" hat X die erwartete Form (n_samples_test, n_samples_train).
- Gibt zurück:
- Tndarray der Form (n_samples, n_classes)
Gibt die Log-Wahrscheinlichkeiten des Samples für jede Klasse im Modell zurück. Die Spalten entsprechen den Klassen in sortierter Reihenfolge, wie sie im Attribut classes_ erscheinen.
Anmerkungen
Das Wahrscheinlichkeitsmodell wird mittels Kreuzvalidierung erstellt, daher können die Ergebnisse leicht von denen abweichen, die mit predict erzielt wurden. Außerdem liefert es auf sehr kleinen Datensätzen bedeutungslose Ergebnisse.
- predict_proba(X)[source]#
Berechnet Wahrscheinlichkeiten möglicher Ergebnisse für Samples in X.
Das Modell muss Wahrscheinlichkeitsinformationen zur Trainingszeit berechnet haben: fit mit dem Attribut
probabilityauf True gesetzt.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Für kernel="precomputed" hat X die erwartete Form (n_samples_test, n_samples_train).
- Gibt zurück:
- Tndarray der Form (n_samples, n_classes)
Gibt die Wahrscheinlichkeit des Samples für jede Klasse im Modell zurück. Die Spalten entsprechen den Klassen in sortierter Reihenfolge, wie sie im Attribut classes_ erscheinen.
Anmerkungen
Das Wahrscheinlichkeitsmodell wird mittels Kreuzvalidierung erstellt, daher können die Ergebnisse leicht von denen abweichen, die mit predict erzielt wurden. Außerdem liefert es auf sehr kleinen Datensätzen bedeutungslose Ergebnisse.
- score(X, y, sample_weight=None)[source]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[source]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[source]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[source]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
Gesichtserkennungsbeispiel mit Eigenfaces und SVMs


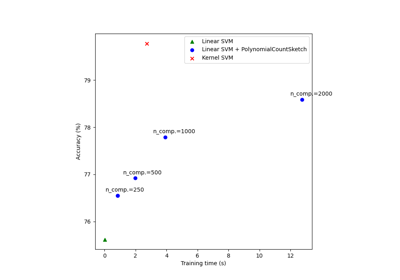
Skalierbares Lernen mit Polynom-Kernel-Approximation


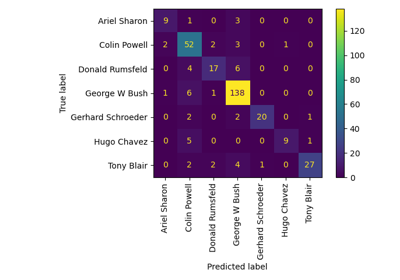
Leistung eines Klassifikators mit Konfusionsmatrix bewerten

Benutzerdefinierte Refit-Strategie einer Gitter-Suche mit Kreuzvalidierung
Statistischer Vergleich von Modellen mittels Gitter-Suche
Lernkurven plotten und die Skalierbarkeit von Modellen prüfen
Verschachtelte vs. nicht verschachtelte Kreuzvalidierung
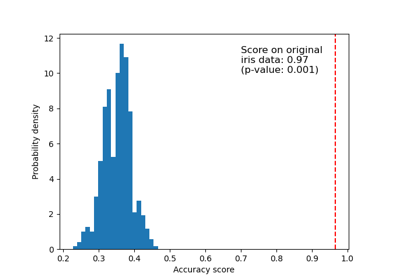
Testen der Signifikanz eines Klassifikations-Scores mit Permutationen
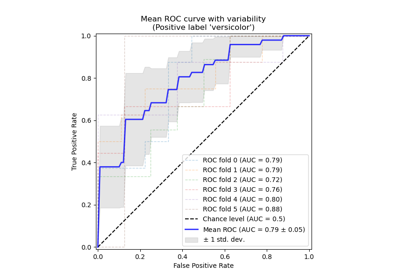
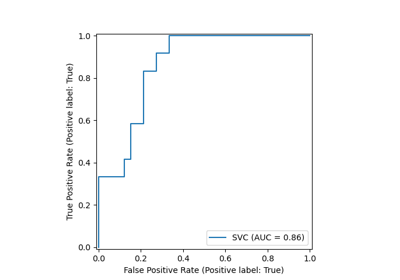
Receiver Operating Characteristic (ROC) mit Kreuzvalidierung
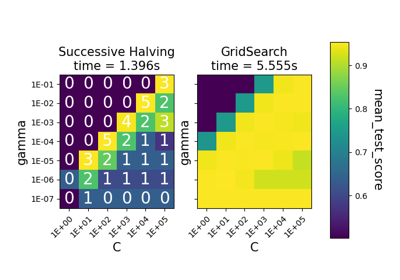
Vergleich zwischen Gitter-Suche und sukzessiver Halbierung

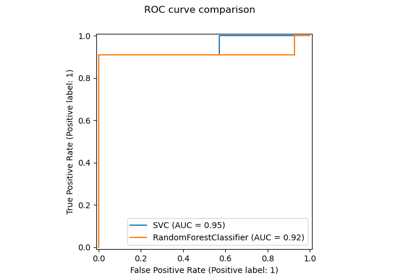
Auswirkung der Änderung des Schwellenwerts für Self-Training
Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz

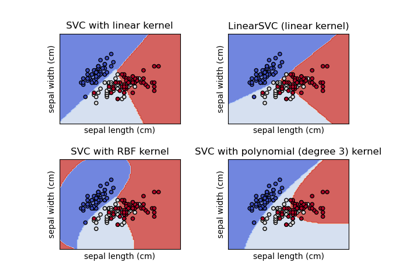
Verschiedene SVM-Klassifikatoren im Iris-Datensatz plotten
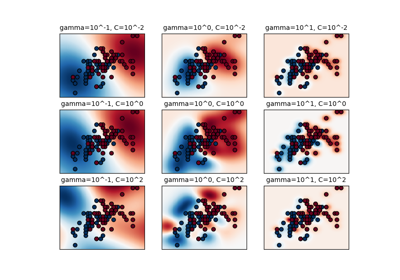
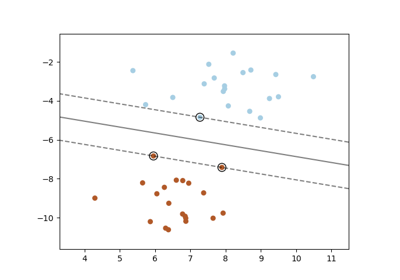
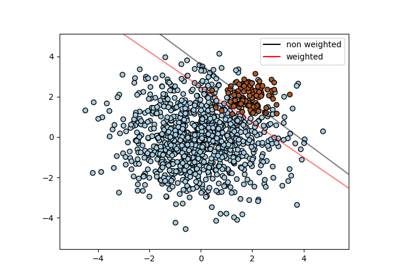
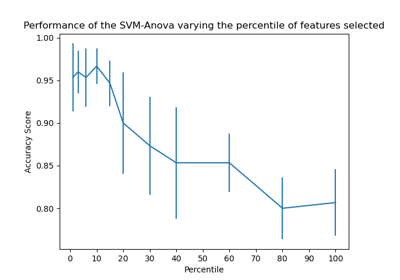
Klassifikationsgrenzen mit verschiedenen SVM-Kernen plotten