DictVectorizer#
- class sklearn.feature_extraction.DictVectorizer(*, dtype=<class 'numpy.float64'>, separator='=', sparse=True, sort=True)[Quelle]#
Transformiert Listen von Merkmalswertzuordnungen in Vektoren.
Dieser Transformer wandelt Listen von Abbildungen (dict-ähnliche Objekte) von Merkmalnamen in Merkmalwerte in Numpy-Arrays oder scipy.sparse Matrizen zur Verwendung mit scikit-learn Estimators um.
Wenn Merkmalwerte Zeichenketten sind, führt dieser Transformer eine binäre One-Hot (auch bekannt als One-of-K) Kodierung durch: für jeden möglichen Zeichenkettenwert, den ein Merkmal annehmen kann, wird ein boolesches Merkmal konstruiert. Zum Beispiel wird ein Merkmal „f“, das die Werte „ham“ und „spam“ annehmen kann, in zwei Merkmale in der Ausgabe umgewandelt, eines, das „f=ham“ bedeutet, und das andere „f=spam“.
Wenn ein Merkmalwert eine Sequenz oder ein Set von Zeichenketten ist, iteriert dieser Transformer über die Werte und zählt die Vorkommen jedes Zeichenkettenwertes.
Beachten Sie jedoch, dass dieser Transformer nur dann eine binäre One-Hot-Kodierung durchführt, wenn die Merkmalwerte vom Typ Zeichenkette sind. Wenn kategoriale Merkmale als numerische Werte wie int oder als iterierbare Zeichenketten dargestellt werden, kann der DictVectorizer durch
OneHotEncoderergänzt werden, um die binäre One-Hot-Kodierung abzuschließen.Merkmale, die in einer Stichprobe (Abbildung) nicht vorkommen, erhalten in der resultierenden Array/Matrix den Wert Null.
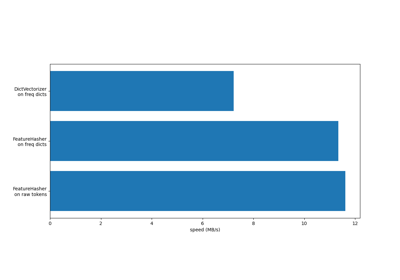
Für einen Effizienzvergleich der verschiedenen Merkmalsextraktoren siehe Vergleich von HashingVectorizer und DictVectorizer.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- dtypedtype, Standardwert=np.float64
Der Typ der Merkmalwerte. Wird als dtype-Argument an die Konstruktoren von Numpy-Array/scipy.sparse Matrix übergeben.
- separatorstr, Standardwert=”=”
Trennzeichen, das beim Konstruieren neuer Merkmale für die One-Hot-Kodierung verwendet wird.
- sparsebool, Standardwert=True
Gibt an, ob transform eine scipy.sparse Matrix erzeugen soll.
- sortbool, Standardwert=True
Gibt an, ob
feature_names_undvocabulary_beim Anpassen sortiert werden sollen.
- Attribute:
- vocabulary_dict
Ein Dictionary, das Merkmalnamen auf Merkmalindizes abbildet.
- feature_names_list
Eine Liste der Länge n_features, die die Merkmalnamen enthält (z.B. „f=ham“ und „f=spam“).
Siehe auch
FeatureHasherFührt die Vektorisierung nur unter Verwendung einer Hash-Funktion durch.
sklearn.preprocessing.OrdinalEncoderBehandelt nominale/kategoriale Merkmale, die als Spalten beliebiger Datentypen kodiert sind.
Beispiele
>>> from sklearn.feature_extraction import DictVectorizer >>> v = DictVectorizer(sparse=False) >>> D = [{'foo': 1, 'bar': 2}, {'foo': 3, 'baz': 1}] >>> X = v.fit_transform(D) >>> X array([[2., 0., 1.], [0., 1., 3.]]) >>> v.inverse_transform(X) == [{'bar': 2.0, 'foo': 1.0}, ... {'baz': 1.0, 'foo': 3.0}] True >>> v.transform({'foo': 4, 'unseen_feature': 3}) array([[0., 0., 4.]])
- fit(X, y=None)[Quelle]#
Lernt eine Liste von Abbildungen von Merkmalnamen zu Indizes.
- Parameter:
- XAbbildung oder Iterable von Abbildungen
Dict(s) oder Mapping(s) von Merkmalnamen (beliebige Python-Objekte) zu Merkmalwerten (Zeichenketten oder in dtype konvertierbar).
Geändert in Version 0.24: Akzeptiert mehrere Zeichenkettenwerte für ein kategoriales Merkmal.
- y(ignoriert)
Ignorierter Parameter.
- Gibt zurück:
- selfobject
Instanz der Klasse DictVectorizer.
- fit_transform(X, y=None)[Quelle]#
Lernt eine Liste von Abbildungen von Merkmalnamen zu Indizes und transformiert X.
Ähnlich wie fit(X), gefolgt von transform(X), erfordert jedoch nicht die Materialisierung von X im Speicher.
- Parameter:
- XAbbildung oder Iterable von Abbildungen
Dict(s) oder Mapping(s) von Merkmalnamen (beliebige Python-Objekte) zu Merkmalwerten (Zeichenketten oder in dtype konvertierbar).
Geändert in Version 0.24: Akzeptiert mehrere Zeichenkettenwerte für ein kategoriales Merkmal.
- y(ignoriert)
Ignorierter Parameter.
- Gibt zurück:
- Xa{Array, Sparse Matrix}
Merkmalvektoren; immer 2-dimensional.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X, dict_type=<class 'dict'>)[Quelle]#
Transformiert Array oder Sparse Matrix X zurück in Merkmalabbildungen.
X muss durch die transform- oder fit_transform-Methode dieses DictVectorizer erzeugt worden sein; es darf nur durch Transformer gelaufen sein, die die Anzahl der Merkmale und ihre Reihenfolge beibehalten.
Im Falle der One-Hot/One-of-K-Kodierung werden anstelle der ursprünglichen Namen und Werte die konstruierten Merkmalnamen und -werte zurückgegeben.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Beispielmatrix.
- dict_typetype, Standardwert=dict
Konstruktor für Merkmalabbildungen. Muss der collections.Mapping API entsprechen.
- Gibt zurück:
- X_originalListe von dict_type-Objekten der Form (n_samples,)
Merkmalabbildungen für die Stichproben in X.
- restrict(support, indices=False)[Quelle]#
Beschränkt die Merkmale auf diejenigen in support unter Verwendung der Merkmalsauswahl.
Diese Funktion modifiziert den Estimator direkt.
- Parameter:
- supportarray-ähnlich
Boolesche Maske oder Liste von Indizes (wie vom get_support Mitglied von Feature-Selektoren zurückgegeben).
- indicesbool, Standardwert=False
Gibt an, ob support eine Liste von Indizes ist.
- Gibt zurück:
- selfobject
Instanz der Klasse DictVectorizer.
Beispiele
>>> from sklearn.feature_extraction import DictVectorizer >>> from sklearn.feature_selection import SelectKBest, chi2 >>> v = DictVectorizer() >>> D = [{'foo': 1, 'bar': 2}, {'foo': 3, 'baz': 1}] >>> X = v.fit_transform(D) >>> support = SelectKBest(chi2, k=2).fit(X, [0, 1]) >>> v.get_feature_names_out() array(['bar', 'baz', 'foo'], ...) >>> v.restrict(support.get_support()) DictVectorizer() >>> v.get_feature_names_out() array(['bar', 'foo'], ...)
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(X)[Quelle]#
Transformiert Feature->Wert Dicts in Array oder Sparse Matrix.
Namenlose Merkmale, die während fit oder fit_transform nicht angetroffen wurden, werden stillschweigend ignoriert.
- Parameter:
- XAbbildung oder Iterable von Abbildungen der Form (n_samples,)
Dict(s) oder Mapping(s) von Merkmalnamen (beliebige Python-Objekte) zu Merkmalwerten (Zeichenketten oder in dtype konvertierbar).
- Gibt zurück:
- Xa{Array, Sparse Matrix}
Merkmalvektoren; immer 2-dimensional.