make_blobs#
- sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None, return_centers=False)[Quelle]#
Generiert isotrope Gaußsche Klumpen für das Clustering.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- n_samplesint oder array-ähnlich, Standard=100
Wenn int, ist dies die Gesamtzahl der Punkte, die gleichmäßig auf die Cluster aufgeteilt werden. Wenn array-ähnlich, gibt jedes Element der Sequenz die Anzahl der Samples pro Cluster an.
Geändert in Version v0.20: man kann jetzt ein Array-ähnliches Objekt an den Parameter
n_samplesübergeben- n_featuresint, Standard=2
Die Anzahl der Merkmale für jedes Sample.
- centersint oder array-ähnlich der Form (n_centers, n_features), Standard=None
Die Anzahl der zu generierenden Zentren oder die festen Mittelpunktskoordinaten. Wenn n_samples ein int und centers None ist, werden 3 Zentren generiert. Wenn n_samples array-ähnlich ist, muss centers entweder None oder ein Array mit der Länge gleich der Länge von n_samples sein.
- cluster_stdfloat oder array-ähnlich von float, Standard=1.0
Die Standardabweichung der Cluster.
- center_boxtuple von float (min, max), Standard=(-10.0, 10.0)
Die Bounding Box für jedes Clusterzentrum, wenn Zentren zufällig generiert werden.
- shufflebool, Standard=True
Mische die Samples.
- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung für die Datenerstellung. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- return_centersbool, Standard=False
Wenn True, werden die Zentren jedes Clusters zurückgegeben.
Hinzugefügt in Version 0.23.
- Gibt zurück:
- Xndarray der Form (n_samples, n_features)
Die generierten Samples.
- yndarray der Form (n_samples,)
Die ganzzahligen Labels für die Clusterzugehörigkeit jedes Samples.
- centersndarray der Form (n_centers, n_features)
Die Zentren jedes Clusters. Nur zurückgegeben, wenn
return_centers=True.
Siehe auch
make_classificationEine komplexere Variante.
Beispiele
>>> from sklearn.datasets import make_blobs >>> X, y = make_blobs(n_samples=10, centers=3, n_features=2, ... random_state=0) >>> print(X.shape) (10, 2) >>> y array([0, 0, 1, 0, 2, 2, 2, 1, 1, 0]) >>> X, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2, ... random_state=0) >>> print(X.shape) (10, 2) >>> y array([0, 1, 2, 0, 2, 2, 2, 1, 1, 0])
Galeriebeispiele#
Wahrscheinlichkeitskalibrierung von Klassifikatoren
Wahrscheinlichkeitskalibrierung für 3-Klassen-Klassifikation
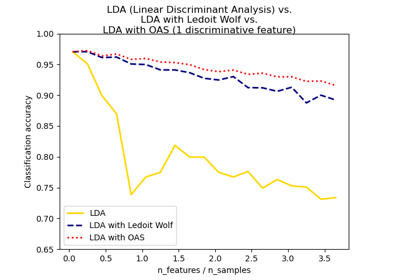
Normale, Ledoit-Wolf und OAS Lineare Diskriminanzanalyse zur Klassifikation
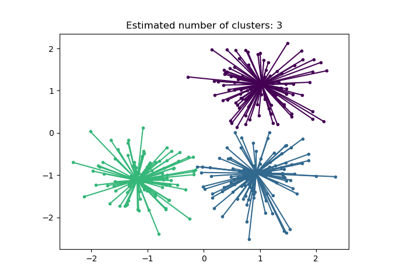
Demo des Affinity Propagation Clustering Algorithmus
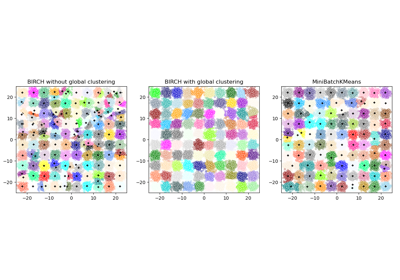
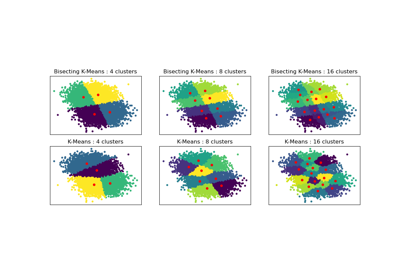
Vergleich der Leistung von Bisecting K-Means und Regular K-Means
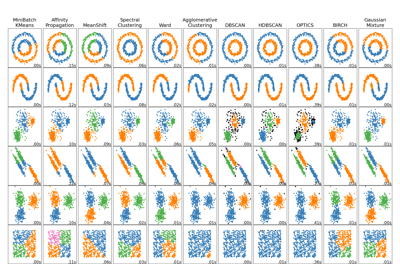
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen
Auswahl der Anzahl von Clustern mit Silhouette-Analyse auf KMeans-Clustering
Vergleich verschiedener hierarchischer Linkage-Methoden auf Toy-Datensätzen
Vergleich der K-Means und MiniBatchKMeans Clustering-Algorithmen
Entscheidungsgrenzen von multinomialer und One-vs-Rest Logistischer Regression
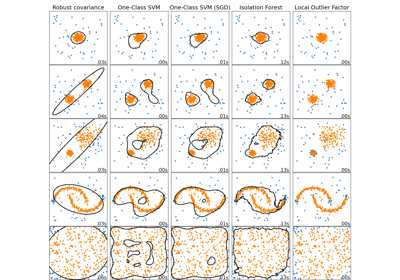
Vergleich von Anomalieerkennungsalgorithmen zur Ausreißererkennung auf Toy-Datensätzen
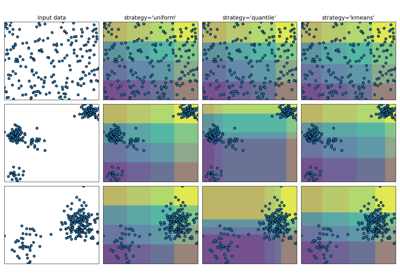
Demonstration der verschiedenen Strategien von KBinsDiscretizer