IsolationForest#
- class sklearn.ensemble.IsolationForest(*, n_estimators=100, max_samples='auto', contamination='auto', max_features=1.0, bootstrap=False, n_jobs=None, random_state=None, verbose=0, warm_start=False)[Quelle]#
Isolation Forest Algorithmus.
Gibt den Anomalie-Score jedes Samples mit dem IsolationForest-Algorithmus zurück.
Der IsolationForest „isoliert“ Beobachtungen, indem zufällig ein Merkmal ausgewählt und dann ein zufälliger Aufteilungswert zwischen dem Maximum und Minimum des ausgewählten Merkmals gewählt wird.
Da rekursives Partitionieren durch eine Baumstruktur dargestellt werden kann, entspricht die Anzahl der Teilungen, die zur Isolierung eines Samples erforderlich sind, der Pfadlänge vom Wurzelknoten zum Endknoten.
Diese Pfadlänge, gemittelt über einen Wald solcher zufälliger Bäume, ist ein Maß für die Normalität und unsere Entscheidungsfunktion.
Zufällige Partitionierung erzeugt für Anomalien merklich kürzere Pfade. Wenn also ein Wald von Zufallsbäumen gemeinsam kürzere Pfadlängen für bestimmte Samples erzeugt, ist es sehr wahrscheinlich, dass es sich um Anomalien handelt.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.18.
- Parameter:
- n_estimatorsint, Standard=100
Die Anzahl der Basisschätzer im Ensemble.
- max_samples„auto“, int oder float, Standardwert = „auto“
Die Anzahl der aus X zu ziehenden Samples, um jeden Basisschätzer zu trainieren.
Wenn int, dann werden
max_samplesSamples gezogen.Wenn float, dann werden
max_samples * X.shape[0]Samples gezogen.Wenn „auto“, dann
max_samples=min(256, n_samples).
Wenn max_samples größer ist als die Anzahl der bereitgestellten Samples, werden alle Samples für alle Bäume verwendet (kein Sampling).
- contamination„auto“ oder float, Standardwert = „auto“
Der Grad der Kontamination des Datensatzes, d. h. der Anteil der Ausreißer im Datensatz. Wird beim Anpassen verwendet, um die Schwelle für die Scores der Samples zu definieren.
Wenn „auto“, wird die Schwelle wie im Originalpapier bestimmt.
Wenn float, sollte die Kontamination im Bereich (0, 0.5] liegen.
Geändert in Version 0.22: Der Standardwert von
contaminationwurde von 0.1 auf'auto'geändert.- max_featuresint oder float, Standardwert=1.0
Die Anzahl der aus X zu ziehenden Merkmale, um jeden Basisschätzer zu trainieren.
Wenn int, dann werden
max_featuresMerkmale gezogen.Wenn float, dann werden
max(1, int(max_features * n_features_in_))Merkmale gezogen.
Hinweis: Die Verwendung einer Gleitkommazahl kleiner als 1.0 oder einer Ganzzahl kleiner als die Anzahl der Merkmale aktiviert das Merkmalsubsampling und führt zu einer längeren Laufzeit.
- bootstrapbool, Standard=False
Wenn True, werden einzelne Bäume auf zufälligen Teilmengen der Trainingsdaten mit Ersetzung trainiert. Wenn False, wird Sampling ohne Ersetzung durchgeführt.
- n_jobsint, default=None
Die Anzahl der parallel auszuführenden Jobs für
fit.Nonebedeutet 1, es sei denn, es befindet sich in einemjoblib.parallel_backend-Kontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.- random_stateint, RandomState-Instanz oder None, default=None
Steuert die Pseudozufälligkeit der Auswahl der Merkmals- und Aufteilungswerte für jeden Verzweigungsschritt und jeden Baum im Wald.
Geben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg an. Siehe Glossar.
- verboseint, default=0
Steuert die Ausführlichkeit des Baumaufbauprozesses.
- warm_startbool, Standard=False
Wenn auf
Truegesetzt, wird die Lösung des vorherigen Aufrufs von fit wiederverwendet und dem Ensemble weitere Schätzer hinzugefügt, andernfalls wird einfach ein komplett neuer Wald angepasst. Siehe das Glossar.Hinzugefügt in Version 0.21.
- Attribute:
- estimator_
ExtraTreeRegressor-Instanz Die Kind-Estimator-Vorlage, die zum Erstellen der Sammlung von angepassten Unter-Estimators verwendet wird.
Hinzugefügt in Version 1.2:
base_estimator_wurde inestimator_umbenannt.- estimators_Liste von ExtraTreeRegressor-Instanzen
Die Sammlung der angepassten Unter-Estimators.
- estimators_features_Liste von ndarray
Die Teilmenge der für jeden Basisschätzer gezogenen Merkmale.
estimators_samples_Liste von ndarrayDie Teilmenge der gezogenen Samples für jeden Basis-Estimator.
- max_samples_int
Die tatsächliche Anzahl von Samples.
- offset_float
Offset, der verwendet wird, um die Entscheidungsfunktion aus den Roh-Scores zu definieren. Wir haben die Beziehung:
decision_function = score_samples - offset_.offset_ist wie folgt definiert: Wenn der Kontaminationsparameter auf „auto“ gesetzt ist, ist der Offset -0.5, da die Scores von Inlinern nahe 0 und die Scores von Auslinern nahe -1 liegen. Wenn ein anderer Kontaminationsparameter als „auto“ angegeben wird, wird der Offset so definiert, dass die erwartete Anzahl von Auslinern (Samples mit Entscheidungsfunktion < 0) beim Training erzielt wird.Hinzugefügt in Version 0.20.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- estimator_
Siehe auch
sklearn.covariance.EllipticEnvelopeObjekt zur Erkennung von Ausreißern in einem Gauß'schen Datensatz.
sklearn.svm.OneClassSVMUnüberwachte Ausreißererkennung. Schätzt die Unterstützung einer hochdimensionalen Verteilung. Die Implementierung basiert auf libsvm.
sklearn.neighbors.LocalOutlierFactorUnüberwachte Ausreißererkennung mittels Local Outlier Factor (LOF).
Anmerkungen
Die Implementierung basiert auf einem Ensemble von ExtraTreeRegressor. Die maximale Tiefe jedes Baumes ist auf
ceil(log_2(n))gesetzt, wobei \(n\) die Anzahl der zum Aufbau des Baumes verwendeten Samples ist (siehe [1] für weitere Details).Referenzen
[1]F. T. Liu, K. M. Ting und Z. -H. Zhou. „Isolation forest.“ 2008 Eighth IEEE International Conference on Data Mining (ICDM), 2008, S. 413–422.
[2]F. T. Liu, K. M. Ting und Z. -H. Zhou. „Isolation-based anomaly detection.“ ACM Transactions on Knowledge Discovery from Data (TKDD) 6.1 (2012): 1-39.
Beispiele
>>> from sklearn.ensemble import IsolationForest >>> X = [[-1.1], [0.3], [0.5], [100]] >>> clf = IsolationForest(random_state=0).fit(X) >>> clf.predict([[0.1], [0], [90]]) array([ 1, 1, -1])
Ein Beispiel für die Verwendung von Isolation Forest zur Anomalieerkennung finden Sie im IsolationForest-Beispiel.
- decision_function(X)[Quelle]#
Durchschnittlicher Anomalie-Score von X der Basisklassifikatoren.
Der Anomalie-Score eines Eingabemusters wird als der mittlere Anomalie-Score der Bäume im Wald berechnet.
Das Maß für die Normalität einer Beobachtung, gegeben einen Baum, ist die Tiefe des Blattes, das diese Beobachtung enthält, was der Anzahl der Teilungen entspricht, die zur Isolierung dieses Punktes erforderlich sind. Bei mehreren Beobachtungen n_left im Blatt wird die durchschnittliche Pfadlänge eines Isolationsbaumes mit n_left Samples hinzugefügt.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt zurück:
- scoresndarray der Form (n_samples,)
Der Anomalie-Score der Eingabemuster. Je niedriger, desto abnormaler. Negative Scores stellen Ausreißer dar, positive Scores stellen Inlier dar.
Anmerkungen
Die Methode decision_function kann durch die Einstellung eines joblib-Kontextes parallelisiert werden. Dies verwendet grundsätzlich NICHT den in der Klasse initialisierten n_jobs-Parameter, der während fit verwendet wird. Dies liegt daran, dass die Berechnung des Scores für eine kleine Anzahl von Samples, wie z. B. 1000 oder weniger, tatsächlich schneller ohne Parallelisierung sein kann. Der Benutzer kann die Anzahl der Jobs im joblib-Kontext festlegen, um die Anzahl der parallelen Jobs zu steuern.
from joblib import parallel_backend # Note, we use threading here as the decision_function method is # not CPU bound. with parallel_backend("threading", n_jobs=4): model.decision_function(X)
- fit(X, y=None, sample_weight=None)[Quelle]#
Schätzer anpassen.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabemuster. Verwenden Sie
dtype=np.float32für maximale Effizienz. Sparse Matrizen werden ebenfalls unterstützt, verwenden Sie die Sparsecsc_matrixfür maximale Effizienz.- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Sample-Gewichte. Wenn None, dann sind die Samples gleichgewichtet.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- fit_predict(X, y=None, **kwargs)[Quelle]#
Führt die Anpassung an X durch und gibt Labels für X zurück.
Gibt -1 für Ausreißer und 1 für Inlier zurück.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben.
- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- **kwargsdict
Argumente, die an
fitübergeben werden sollen.Hinzugefügt in Version 1.4.
- Gibt zurück:
- yndarray der Form (n_samples,)
1 für Inlier, -1 für Ausreißer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.5.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersagen, ob ein bestimmtes Sample ein Ausreißer ist oder nicht.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt zurück:
- is_inlierndarray von Form (n_samples,)
Gibt für jede Beobachtung an, ob sie gemäß dem angepassten Modell als Inlier betrachtet werden sollte oder nicht (+1 oder -1).
Anmerkungen
Die Methode predict kann durch die Einstellung eines joblib-Kontextes parallelisiert werden. Dies verwendet grundsätzlich NICHT den in der Klasse initialisierten n_jobs-Parameter, der während fit verwendet wird. Dies liegt daran, dass die Vorhersage für eine kleine Anzahl von Samples, wie z. B. 1000 oder weniger, möglicherweise schneller ohne Parallelisierung ist. Der Benutzer kann die Anzahl der Jobs im joblib-Kontext festlegen, um die Anzahl der parallelen Jobs zu steuern.
from joblib import parallel_backend # Note, we use threading here as the predict method is not CPU bound. with parallel_backend("threading", n_jobs=4): model.predict(X)
- score_samples(X)[Quelle]#
Gegenteil des im Originalpapier definierten Anomalie-Scores.
Der Anomalie-Score eines Eingabemusters wird als der mittlere Anomalie-Score der Bäume im Wald berechnet.
Das Maß für die Normalität einer Beobachtung, gegeben einen Baum, ist die Tiefe des Blattes, das diese Beobachtung enthält, was der Anzahl der Teilungen entspricht, die zur Isolierung dieses Punktes erforderlich sind. Bei mehreren Beobachtungen n_left im Blatt wird die durchschnittliche Pfadlänge eines Isolationsbaumes mit n_left Samples hinzugefügt.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt zurück:
- scoresndarray der Form (n_samples,)
Der Anomalie-Score der Eingabemuster. Je niedriger, desto abnormaler.
Anmerkungen
Die Score-Funktionsmethode kann durch die Einstellung eines joblib-Kontextes parallelisiert werden. Dies verwendet grundsätzlich NICHT den in der Klasse initialisierten n_jobs-Parameter, der während fit verwendet wird. Dies liegt daran, dass die Berechnung des Scores für eine kleine Anzahl von Samples, wie z. B. 1000 oder weniger, möglicherweise schneller ohne Parallelisierung ist. Der Benutzer kann die Anzahl der Jobs im joblib-Kontext festlegen, um die Anzahl der parallelen Jobs zu steuern.
from joblib import parallel_backend # Note, we use threading here as the score_samples method is not CPU bound. with parallel_backend("threading", n_jobs=4): model.score(X)
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') IsolationForest[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
Galeriebeispiele#
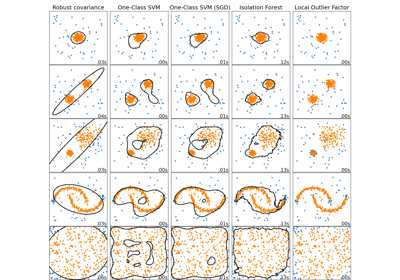
Vergleich von Anomalieerkennungsalgorithmen zur Ausreißererkennung auf Toy-Datensätzen
