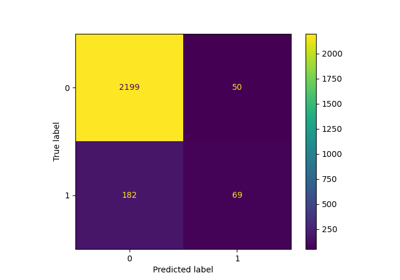
confusion_matrix#
- sklearn.metrics.confusion_matrix(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None)[Quelle]#
Berechnet die Konfusionsmatrix zur Bewertung der Genauigkeit einer Klassifikation.
Per Definition ist eine Konfusionsmatrix \(C\) so beschaffen, dass \(C_{i, j}\) gleich der Anzahl der Beobachtungen ist, die als zur Gruppe \(i\) gehörend bekannt sind und als zur Gruppe \(j\) vorhergesagt wurden.
Somit ist bei der binären Klassifizierung die Anzahl der wahren Negativen \(C_{0,0}\), der falschen Negativen \(C_{1,0}\), der wahren Positiven \(C_{1,1}\) und der falschen Positiven \(C_{0,1}\).
Mehr dazu im Benutzerhandbuch.
- Parameter:
- y_truearray-ähnlich mit Form (n_samples,)
Wahrheitsgetreue (korrekte) Zielwerte.
- y_predarray-ähnlich mit Form (n_samples,)
Geschätzte Zielwerte, wie sie von einem Klassifikator zurückgegeben werden.
- labelsarray-like der Form (n_classes,), Standard=None
Liste der Labels zum Indizieren der Matrix. Dies kann verwendet werden, um Labels neu anzuordnen oder eine Teilmenge auszuwählen. Wenn
Noneangegeben wird, werden diejenigen verwendet, die mindestens einmal iny_trueodery_predvorkommen, in sortierter Reihenfolge.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
Hinzugefügt in Version 0.18.
- normalize{‘true’, ‘pred’, ‘all’}, Standardwert=None
Normalisiert die Konfusionsmatrix über die wahren (Zeilen), vorhergesagten (Spalten) Bedingungen oder die gesamte Population. Wenn None, wird die Konfusionsmatrix nicht normalisiert.
- Gibt zurück:
- Cndarray der Form (n_classes, n_classes)
Konfusionsmatrix, deren Eintrag in der i-ten Zeile und j-ten Spalte die Anzahl der Stichproben angibt, deren wahres Label die i-te Klasse ist und deren vorhergesagtes Label die j-te Klasse ist.
Siehe auch
ConfusionMatrixDisplay.from_estimatorKonfusionsmatrix basierend auf einem Schätzer, den Daten und dem Label plotten.
ConfusionMatrixDisplay.from_predictionsKonfusionsmatrix basierend auf den wahren und vorhergesagten Labels plotten.
ConfusionMatrixDisplayVisualisierung der Konfusionsmatrix.
confusion_matrix_at_thresholdsBerechnet im binären Fall die Zählungen von True Negative, False Positive, False Negative und True Positive pro Schwellenwert.
Referenzen
[1]Wikipedia-Eintrag zur Konfusionsmatrix (Wikipedia und andere Referenzen verwenden möglicherweise eine andere Achsenkonvention).
Beispiele
>>> from sklearn.metrics import confusion_matrix >>> y_true = [2, 0, 2, 2, 0, 1] >>> y_pred = [0, 0, 2, 2, 0, 2] >>> confusion_matrix(y_true, y_pred) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
>>> y_true = ["cat", "ant", "cat", "cat", "ant", "bird"] >>> y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"] >>> confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"]) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
Im binären Fall können wir True Positives usw. wie folgt extrahieren
>>> tn, fp, fn, tp = confusion_matrix([0, 1, 0, 1], [1, 1, 1, 0]).ravel().tolist() >>> (tn, fp, fn, tp) (0, 2, 1, 1)
Galeriebeispiele#
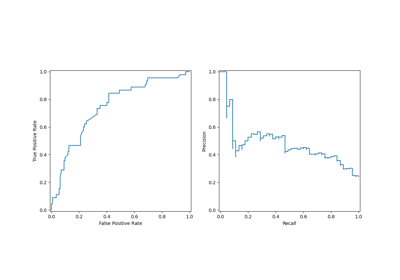
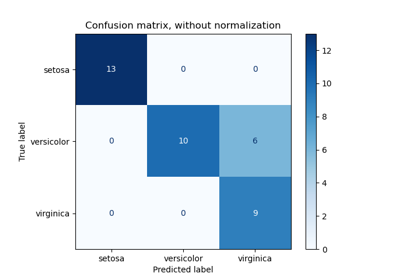
Leistung eines Klassifikators mit Konfusionsmatrix bewerten
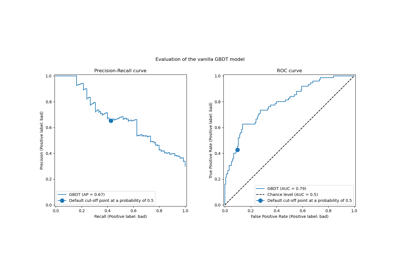
Post-Hoc-Anpassung des Entscheidungsschwellenwerts für kostenempfindliches Lernen