MLPClassifier#
- class sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100,), activation='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10, max_fun=15000)[Quelle]#
Multi-Layer Perceptron Klassifikator.
Dieses Modell optimiert die Log-Loss-Funktion mithilfe von LBFGS oder stochastischem Gradientenabstieg.
Hinzugefügt in Version 0.18.
- Parameter:
- hidden_layer_sizesarray-like der Form (n_layers - 2,), Standard=(100,)
Das i-te Element repräsentiert die Anzahl der Neuronen in der i-ten versteckten Schicht.
- activation{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, Standard=’relu’
Aktivierungsfunktion für die versteckte Schicht.
‘identity’, keine Operation-Aktivierung, nützlich zur Implementierung eines linearen Engpasses, gibt f(x) = x zurück
‘logistic’, die logistische Sigmoid-Funktion, gibt f(x) = 1 / (1 + exp(-x)) zurück.
‘tanh’, die hyperbolische Tangens-Funktion, gibt f(x) = tanh(x) zurück.
‘relu’, die Rectified Linear Unit-Funktion, gibt f(x) = max(0, x) zurück
- solver{‘lbfgs’, ‘sgd’, ‘adam’}, Standard=’adam’
Der Solver für die Gewichtsoptimierung.
‘lbfgs’ ist ein Optimierer aus der Familie der Quasi-Newton-Methoden.
‘sgd’ bezieht sich auf den stochastischen Gradientenabstieg.
‘adam’ bezieht sich auf einen stochastisch gradientenbasierten Optimierer, der von Kingma, Diederik und Jimmy Ba vorgeschlagen wurde.
Einen Vergleich zwischen dem Adam-Optimierer und SGD finden Sie unter Vergleich von stochastischen Lernstrategien für MLPClassifier.
Hinweis: Der Standard-Solver ‘adam’ funktioniert bei relativ großen Datensätzen (mit Tausenden von Trainingssamples oder mehr) sowohl hinsichtlich der Trainingszeit als auch der Validierungsbewertung recht gut. Bei kleinen Datensätzen kann ‘lbfgs’ jedoch schneller konvergieren und besser abschneiden.
- alphafloat, default=0.0001
Stärke des L2-Regularisierungsterms. Der L2-Regularisierungsterm wird durch die Stichprobengröße geteilt, wenn er zur Verlustfunktion hinzugefügt wird.
Ein Beispiel für die Verwendung und Visualisierung variierender Regularisierung finden Sie unter Variierende Regularisierung in Multi-Layer Perceptron.
- batch_sizeint, Standard=’auto’
Größe der Minibatches für stochastische Optimierer. Wenn der Solver ‘lbfgs’ ist, verwendet der Klassifikator keine Minibatches. Wenn auf „auto“ gesetzt, ist
batch_size=min(200, n_samples).- learning_rate{‘constant’, ‘invscaling’, ‘adaptive’}, Standard=’constant’
Lernratenschema für Gewichtsaktualisierungen.
‘constant’ ist eine konstante Lernrate, die durch ‘learning_rate_init’ gegeben ist.
‘invscaling’ verringert die Lernrate schrittweise bei jedem Zeitschritt ‘t’ unter Verwendung eines inversen Skalierungsexponenten von ‘power_t’. effective_learning_rate = learning_rate_init / pow(t, power_t)
‘adaptive’ hält die Lernrate konstant auf ‘learning_rate_init’, solange der Trainingsverlust weiter abnimmt. Jedes Mal, wenn zwei aufeinanderfolgende Epochen den Trainingsverlust nicht um mindestens tol verringern oder die Validierungsbewertung nicht um mindestens tol erhöhen, wenn ‘early_stopping’ aktiviert ist, wird die aktuelle Lernrate durch 5 geteilt.
Wird nur verwendet, wenn
solver='sgd'.- learning_rate_initfloat, Standard=0.001
Die verwendete initiale Lernrate. Sie steuert die Schrittgröße bei der Aktualisierung der Gewichte. Wird nur verwendet, wenn solver=’sgd’ oder ‘adam’.
- power_tfloat, default=0.5
Der Exponent für die inverse Skalierung der Lernrate. Er wird bei der Aktualisierung der effektiven Lernrate verwendet, wenn die Lernrate auf ‘invscaling’ gesetzt ist. Wird nur verwendet, wenn solver=’sgd’.
- max_iterint, Standard=200
Maximale Anzahl von Iterationen. Der Solver iteriert bis zur Konvergenz (bestimmt durch ‘tol’) oder bis zu dieser Anzahl von Iterationen. Für stochastische Solver (‘sgd’, ‘adam’) beachten Sie, dass dies die Anzahl der Epochen bestimmt (wie oft jeder Datenpunkt verwendet wird), nicht die Anzahl der Gradientenschritte.
- shufflebool, Standard=True
Ob die Stichproben in jeder Iteration gemischt werden sollen. Wird nur verwendet, wenn solver=’sgd’ oder ‘adam’.
- random_stateint, RandomState instance, default=None
Bestimmt die Zufallszahlengenerierung für die Initialisierung von Gewichten und Bias, die Aufteilung in Trainings- und Testdaten bei aktivierter Früherkennung und die Stichprobenentnahme im Minibatch-Verfahren, wenn solver=’sgd’ oder ‘adam’ ist. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- tolfloat, Standard=1e-4
Toleranz für die Optimierung. Wenn der Verlust oder die Bewertung sich über
n_iter_no_changeaufeinanderfolgende Iterationen nicht um mindestenstolverbessert, es sei denn,learning_rateist auf ‘adaptive’ gesetzt, wird die Konvergenz als erreicht betrachtet und das Training gestoppt.- verbosebool, default=False
Ob Fortschrittsmeldungen an stdout ausgegeben werden sollen.
- warm_startbool, Standard=False
Wenn auf True gesetzt, wird die Lösung des vorherigen Aufrufs von fit als Initialisierung wiederverwendet, andernfalls wird die vorherige Lösung einfach verworfen. Siehe das Glossar.
- momentumfloat, Standard=0.9
Momentum für die Gradientenabstiegsaktualisierung. Sollte zwischen 0 und 1 liegen. Wird nur verwendet, wenn solver=’sgd’.
- nesterovs_momentumbool, Standard=True
Ob Nesterovs Momentum verwendet werden soll. Wird nur verwendet, wenn solver=’sgd’ und momentum > 0.
- early_stoppingbool, default=False
Ob Früherkennung (Early Stopping) zur Beendigung des Trainings verwendet werden soll, wenn die Validierungsbewertung nicht besser wird. Wenn auf True gesetzt, werden automatisch
validation_fractionder Trainingsdaten als Validierungsdatensatz zurückgestellt und das Training beendet, wenn die Validierungsbewertung fürn_iter_no_changeaufeinanderfolgende Epochen nicht um mindestenstolbesser wird. Die Aufteilung ist stratifiziert, außer in einem Multilabel-Setting. Wenn Early Stopping False ist, stoppt das Training, wenn der Trainingsverlust nicht um mehr alstolfürn_iter_no_changeaufeinanderfolgende Durchläufe des Trainingsdatensatzes verbessert wird. Nur wirksam, wenn solver=’sgd’ oder ‘adam’.- validation_fractionfloat, default=0.1
Der Anteil der Trainingsdaten, der als Validierungsdatensatz für Early Stopping beiseitegelegt werden soll. Muss zwischen 0 und 1 liegen. Wird nur verwendet, wenn early_stopping True ist.
- beta_1float, Standard=0.9
Exponentielle Abklingrate für Schätzungen des ersten Momentenvektors in Adam, sollte im Bereich [0, 1) liegen. Wird nur verwendet, wenn solver=’adam’.
- beta_2float, Standard=0.999
Exponentielle Abklingrate für Schätzungen des zweiten Momentenvektors in Adam, sollte im Bereich [0, 1) liegen. Wird nur verwendet, wenn solver=’adam’.
- epsilonfloat, Standard=1e-8
Wert für numerische Stabilität in Adam. Wird nur verwendet, wenn solver=’adam’.
- n_iter_no_changeint, Standard=10
Maximale Anzahl von Epochen, in denen
tolVerbesserung nicht erreicht wird. Nur wirksam, wenn solver=’sgd’ oder ‘adam’.Hinzugefügt in Version 0.20.
- max_funint, Standard=15000
Wird nur verwendet, wenn solver=’lbfgs’. Maximale Anzahl von Funktionsaufrufen der Verlustfunktion. Der Solver iteriert bis zur Konvergenz (bestimmt durch ‘tol’), bis die Anzahl der Iterationen max_iter erreicht, oder bis zu dieser Anzahl von Funktionsaufrufen der Verlustfunktion. Beachten Sie, dass die Anzahl der Funktionsaufrufe der Verlustfunktion größer oder gleich der Anzahl der Iterationen für den
MLPClassifiersein wird.Hinzugefügt in Version 0.22.
- Attribute:
- classes_ndarray oder Liste von ndarrays der Form (n_classes,)
Klassenbezeichnungen für jede Ausgabe.
- loss_float
Der aktuelle Verlust, berechnet mit der Verlustfunktion.
- best_loss_float oder None
Der minimale Verlust, der vom Solver während des Trainings erreicht wurde. Wenn
early_stopping=Trueist, wird dieses Attribut aufNonegesetzt. Beziehen Sie sich stattdessen auf das trainierte Attributbest_validation_score_.- loss_curve_Liste der Form (
n_iter_,) Das i-te Element in der Liste repräsentiert den Verlust bei der i-ten Iteration.
- validation_scores_Liste der Form (
n_iter_,) oder None Die Bewertung bei jeder Iteration auf einem zurückgestellten Validierungsdatensatz. Die berichtete Bewertung ist die Genauigkeitsbewertung. Nur verfügbar, wenn
early_stopping=Trueist, andernfalls wird das Attribut aufNonegesetzt.- best_validation_score_float oder None
Die beste Validierungsbewertung (d.h. Genauigkeitsbewertung), die die Früherkennung ausgelöst hat. Nur verfügbar, wenn
early_stopping=Trueist, andernfalls wird das Attribut aufNonegesetzt.- t_int
Die Anzahl der Trainingssamples, die der Solver während des Trainings gesehen hat.
- coefs_Liste der Form (n_layers - 1,)
Das i-te Element in der Liste repräsentiert die Gewichtsmatrix, die Schicht i entspricht.
- intercepts_Liste der Form (n_layers - 1,)
Das i-te Element in der Liste repräsentiert den Bias-Vektor, der Schicht i + 1 entspricht.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_iter_int
Die Anzahl der Iterationen, die der Solver ausgeführt hat.
- n_layers_int
Anzahl der Schichten.
- n_outputs_int
Anzahl der Ausgaben.
- out_activation_str
Name der Ausgabefunktion für die Aktivierung.
Siehe auch
MLPRegressorMulti-Layer Perceptron Regressor.
BernoulliRBMBernoulli Restricted Boltzmann Machine (RBM).
Anmerkungen
MLPClassifier trainiert iterativ, da in jedem Zeitschritt die partiellen Ableitungen der Verlustfunktion in Bezug auf die Modellparameter berechnet werden, um die Parameter zu aktualisieren.
Es kann auch ein Regularisierungsterm zur Verlustfunktion hinzugefügt werden, der die Modellparameter schrumpfen lässt, um Überanpassung zu verhindern.
Diese Implementierung funktioniert mit Daten, die als dichte NumPy-Arrays oder spärliche SciPy-Arrays mit Fließkommawerten dargestellt sind.
Referenzen
Hinton, Geoffrey E. “Connectionist learning procedures.” Artificial intelligence 40.1 (1989): 185-234.
Glorot, Xavier und Yoshua Bengio. „Understanding the difficulty of training deep feedforward neural networks.“ International Conference on Artificial Intelligence and Statistics. 2010.
Kingma, Diederik und Jimmy Ba (2014) „Adam: A method for stochastic optimization.“
Beispiele
>>> from sklearn.neural_network import MLPClassifier >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> X, y = make_classification(n_samples=100, random_state=1) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, ... random_state=1) >>> clf = MLPClassifier(random_state=1, max_iter=300).fit(X_train, y_train) >>> clf.predict_proba(X_test[:1]) array([[0.0383, 0.961]]) >>> clf.predict(X_test[:5, :]) array([1, 0, 1, 0, 1]) >>> clf.score(X_test, y_test) 0.8...
- fit(X, y, sample_weight=None)[Quelle]#
Passt das Modell an die Datenmatrix X und die Zielvariable(n) y an.
- Parameter:
- Xndarray oder spärliche Matrix der Form (n_samples, n_features)
Die Eingabedaten.
- yndarray der Form (n_samples,) oder (n_samples, n_outputs)
Die Zielwerte (Klassenbezeichnungen bei Klassifizierung, reelle Zahlen bei Regression).
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
Hinzugefügt in Version 1.7.
- Gibt zurück:
- selfobject
Gibt ein trainiertes MLP-Modell zurück.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- partial_fit(X, y, sample_weight=None, classes=None)[Quelle]#
Aktualisiert das Modell mit einer einzelnen Iteration über die gegebenen Daten.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabedaten.
- yarray-like von Form (n_samples,)
Die Zielwerte.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
Hinzugefügt in Version 1.7.
- classesarray der Form (n_classes,), Standard=None
Klassen über alle Aufrufe von partial_fit hinweg. Kann über
np.unique(y_all)abgerufen werden, wobei y_all der Zielvektor des gesamten Datensatzes ist. Dieses Argument ist für den ersten Aufruf von partial_fit erforderlich und kann bei nachfolgenden Aufrufen weggelassen werden. Beachten Sie, dass y nicht alle Labels inclassesenthalten muss.
- Gibt zurück:
- selfobject
Trainiertes MLP-Modell.
- predict(X)[Quelle]#
Vorhersagen mit dem Multi-Layer Perceptron-Klassifikator.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabedaten.
- Gibt zurück:
- yndarray, Form (n_samples,) oder (n_samples, n_classes)
Die vorhergesagten Klassen.
- predict_log_proba(X)[Quelle]#
Gibt den Logarithmus der Wahrscheinlichkeitsabschätzungen zurück.
- Parameter:
- Xndarray der Form (n_samples, n_features)
Die Eingabedaten.
- Gibt zurück:
- log_y_probndarray der Form (n_samples, n_classes)
Die vorhergesagte Log-Wahrscheinlichkeit der Stichprobe für jede Klasse im Modell, wobei die Klassen in der Reihenfolge sind, wie sie in
self.classes_erscheinen. Äquivalent zulog(predict_proba(X)).
- predict_proba(X)[Quelle]#
Wahrscheinlichkeitsschätzungen.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabedaten.
- Gibt zurück:
- y_probndarray der Form (n_samples, n_classes)
Die vorhergesagte Wahrscheinlichkeit der Stichprobe für jede Klasse im Modell, wobei die Klassen in der Reihenfolge sind, wie sie in
self.classes_erscheinen.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MLPClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_partial_fit_request(*, classes: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') MLPClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
partial_fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und anpartial_fitübergeben, wenn sie bereitgestellt werden. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anpartial_fit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- klassenstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
klasseninpartial_fit.- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinpartial_fit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MLPClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

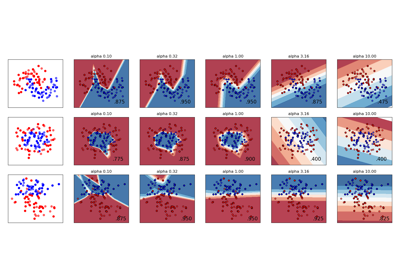
Variierende Regularisierung im Multi-Layer Perceptron
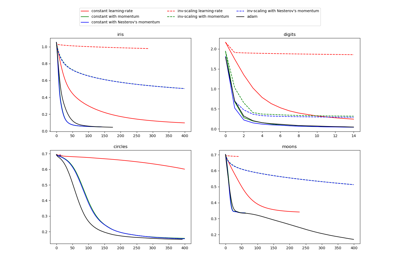
Vergleich von stochastischen Lernstrategien für MLPClassifier
