CalibratedClassifierCV#
- class sklearn.calibration.CalibratedClassifierCV(estimator=None, *, method='sigmoid', cv=None, n_jobs=None, ensemble='auto')[Quelle]#
Kalibriert Wahrscheinlichkeiten mittels isotonischer, sigmoidaler oder temperaturabhängiger Skalierung.
Diese Klasse verwendet Kreuzvalidierung, um sowohl die Parameter eines Klassifikators zu schätzen als auch anschließend einen Klassifikator zu kalibrieren. Mit
ensemble=Truewerden für jede CV-Aufteilung eine Kopie des Basis-Schätzers an die Trainingsuntermenge angepasst und diese mithilfe der Testuntermenge kalibriert. Für die Vorhersage werden die vorhergesagten Wahrscheinlichkeiten über diese einzelnen kalibrierten Klassifikatoren gemittelt. Wennensemble=False, wird die Kreuzvalidierung verwendet, um unverzerrte Vorhersagen übercross_val_predictzu erhalten, die dann für die Kalibrierung verwendet werden. Für die Vorhersage wird der Basis-Schätzer verwendet, der mit allen Daten trainiert wurde. Dies ist die Vorhersagemethode, die implementiert wird, wennprobabilities=TruefürSVCundNuSVC-Schätzer gilt (siehe Benutzerhandbuch für Details).Bereits angepasste Klassifikatoren können durch Einpacken des Modells in einen
FrozenEstimatorkalibriert werden. In diesem Fall werden alle bereitgestellten Daten zur Kalibrierung verwendet. Der Benutzer muss manuell sicherstellen, dass die Daten für die Modellanpassung und die Kalibrierung disjunkt sind.Die Kalibrierung basiert auf der decision_function-Methode des
estimator, falls vorhanden, andernfalls auf predict_proba.Lesen Sie mehr im Benutzerhandbuch. Um mehr über die Klasse CalibratedClassifierCV zu erfahren, siehe die folgenden Kalibrierungsbeispiele: Probability calibration of classifiers, Probability Calibration curves und Probability Calibration for 3-class classification.
- Parameter:
- estimatorestimator instance, default=None
Der Klassifikator, dessen Ausgabe kalibriert werden muss, um genauere
predict_proba-Ausgaben zu liefern. Der Standard-Klassifikator ist einLinearSVC.Hinzugefügt in Version 1.2.
- method{‘sigmoid’, ‘isotonic’, ‘temperature’}, default=’sigmoid’
Die zu verwendende Methode für die Kalibrierung. Kann sein
„sigmoid“, was der Platt'schen Methode entspricht (d. h. einem binären logistischen Regressionsmodell).
„isotonic“, ein nicht-parametrischer Ansatz.
„temperature“, Temperatur-Skalierung.
Sigmoid- und isotonische Kalibrierungsmethoden unterstützen nativ nur binäre Klassifikatoren und werden auf die Multiklassenklassifizierung mit einer One-vs-Rest (OvR)-Strategie mit nachträglicher Renormierung ausgedehnt, d. h. die Wahrscheinlichkeiten werden nach der Kalibrierung angepasst, um sicherzustellen, dass sie sich zu 1 aufsummieren.
Im Gegensatz dazu unterstützt die Temperatur-Skalierung nativ die Multiklassen-Kalibrierung durch Anwenden von
softmax(classifier_logits/T)mit einem Wert vonT(Temperatur), der den Log-Verlust optimiert.Für stark unkalibrierte Klassifikatoren auf stark unausgeglichenen Datensätzen kann die Sigmoid-Kalibrierung bevorzugt werden, da sie einen zusätzlichen Achsenabschnittsparameter anpasst. Dies hilft, Entscheidungsgrenzen entsprechend zu verschieben, wenn der zu kalibrierende Klassifikator zur Mehrheitsklasse tendiert.
Die isotonische Kalibrierung wird nicht empfohlen, wenn die Anzahl der Kalibrierungsstichproben zu gering ist
(≪1000), da sie dann zum Überanpassen neigt.Geändert in Version 1.8: Option ‘temperature’ hinzugefügt.
- cvint, cross-validation generator, or iterable, default=None
Bestimmt die Strategie der Kreuzvalidierungsaufteilung. Mögliche Eingaben für cv sind
None, um die standardmäßige 5-fache Kreuzvalidierung zu verwenden,
Ganzzahl, um die Anzahl der Folds anzugeben.
Eine iterierbare Liste, die (Trainings-, Test-) Splits als Indizes-Arrays liefert.
Bei Ganzzahl-/None-Eingaben, wenn
ybinär oder multiklass ist, wirdStratifiedKFoldverwendet. Wennyweder binär noch multiklass ist, wirdKFoldverwendet.Siehe das Benutzerhandbuch für die verschiedenen hier verwendbaren Kreuzvalidierungsstrategien.
Geändert in Version 0.22: Der Standardwert von
cv, wenn None, hat sich von 3-Fold auf 5-Fold geändert.- n_jobsint, default=None
Anzahl der parallel auszuführenden Jobs.
Nonebedeutet 1, es sei denn, Sie befinden sich in einemjoblib.parallel_backend-Kontext.-1bedeutet, alle Prozessoren zu verwenden.Basis-Schätzer-Klone werden parallel über Kreuzvalidierungsiterationen angepasst.
Siehe Glossar für weitere Details.
Hinzugefügt in Version 0.24.
- ensemblebool, or “auto”, default=”auto”
Bestimmt, wie der Kalibrator angepasst wird.
„auto“ verwendet
False, wenn derestimatoreinFrozenEstimatorist, und andernfallsTrue.Wenn
True, wird derestimatorunter Verwendung von Trainingsdaten angepasst und mit Testdaten für jedecv-Falte kalibriert. Der endgültige Schätzer ist ein Ensemble vonn_cvangepassten Klassifikator- und Kalibratorpaaren, wobein_cvdie Anzahl der Kreuzvalidierungsfalten ist. Die Ausgabe sind die durchschnittlichen vorhergesagten Wahrscheinlichkeiten aller Paare.Wenn
False, wirdcvverwendet, um unverzerrte Vorhersagen übercross_val_predictzu berechnen, die dann zur Kalibrierung verwendet werden. Zum Vorhersagezeitpunkt ist der verwendete Klassifikator derestimator, der auf allen Daten trainiert wurde. Beachten Sie, dass diese Methode auch intern insklearn.svm-Schätzern mit dem Parameterprobabilities=Trueimplementiert ist.Hinzugefügt in Version 0.24.
Geändert in Version 1.6: Option
"auto"wurde hinzugefügt und ist der Standard.
- Attribute:
- classes_ndarray der Form (n_classes,)
Die Klassenbeschriftungen.
- n_features_in_int
Anzahl der während fit gesehenen Merkmale. Nur definiert, wenn der zugrunde liegende Schätzer ein solches Attribut nach dem Training bereitstellt.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen von Features, die während fit gesehen wurden. Nur definiert, wenn der zugrunde liegende Estimator ein solches Attribut nach dem Anpassen exponiert.
Hinzugefügt in Version 1.0.
- calibrated_classifiers_list (len() gleich cv oder 1, wenn
ensemble=False) Die Liste der Klassifikator- und Kalibratorpaare.
Wenn
ensemble=True, dannn_cvangepassteestimator- und Kalibratorpaare.n_cvist die Anzahl der Kreuzvalidierungsfalten.Wenn
ensemble=False, dann derestimator, der auf allen Daten angepasst wurde, und der angepasste Kalibrator.
Geändert in Version 0.24: Einzelner kalibrierter Klassifikatorfall, wenn
ensemble=False.
Siehe auch
calibration_curveBerechnet wahre und vorhergesagte Wahrscheinlichkeiten für eine Kalibrierungskurve.
Referenzen
[1]B. Zadrozny & C. Elkan. Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers, ICML 2001.
[2]B. Zadrozny & C. Elkan. Transforming Classifier Scores into Accurate Multiclass Probability Estimates, KDD 2002.
[3]J. Platt. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods, 1999.
[4]A. Niculescu-Mizil & R. Caruana. Predicting Good Probabilities with Supervised Learning, ICML 2005.
[5]Chuan Guo, Geoff Pleiss, Yu Sun, Kilian Q. Weinberger. On Calibration of Modern Neural Networks. Proceedings of the 34th International Conference on Machine Learning, PMLR 70:1321-1330, 2017.
Beispiele
>>> from sklearn.datasets import make_classification >>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.calibration import CalibratedClassifierCV >>> X, y = make_classification(n_samples=100, n_features=2, ... n_redundant=0, random_state=42) >>> base_clf = GaussianNB() >>> calibrated_clf = CalibratedClassifierCV(base_clf, cv=3) >>> calibrated_clf.fit(X, y) CalibratedClassifierCV(...) >>> len(calibrated_clf.calibrated_classifiers_) 3 >>> calibrated_clf.predict_proba(X)[:5, :] array([[0.110, 0.889], [0.072, 0.927], [0.928, 0.072], [0.928, 0.072], [0.072, 0.928]]) >>> from sklearn.model_selection import train_test_split >>> X, y = make_classification(n_samples=100, n_features=2, ... n_redundant=0, random_state=42) >>> X_train, X_calib, y_train, y_calib = train_test_split( ... X, y, random_state=42 ... ) >>> base_clf = GaussianNB() >>> base_clf.fit(X_train, y_train) GaussianNB() >>> from sklearn.frozen import FrozenEstimator >>> calibrated_clf = CalibratedClassifierCV(FrozenEstimator(base_clf)) >>> calibrated_clf.fit(X_calib, y_calib) CalibratedClassifierCV(...) >>> len(calibrated_clf.calibrated_classifiers_) 1 >>> calibrated_clf.predict_proba([[-0.5, 0.5]]) array([[0.936, 0.063]])
- fit(X, y, sample_weight=None, **fit_params)[Quelle]#
Passen Sie das kalibrierte Modell an.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Trainingsdaten.
- yarray-like von Form (n_samples,)
Zielwerte.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte. Wenn None, dann werden die Stichproben gleich gewichtet.
- **fit_paramsdict
Parameter, die an die
fit-Methode des zugrunde liegenden Klassifikators übergeben werden.
- Gibt zurück:
- selfobject
Gibt eine Instanz von self zurück.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Sagen Sie das Ziel neuer Stichproben voraus.
Die vorhergesagte Klasse ist die Klasse mit der höchsten Wahrscheinlichkeit und kann sich daher von der Vorhersage des unkalibrierten Klassifikators unterscheiden.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Stichproben, wie sie von
estimator.predictakzeptiert werden.
- Gibt zurück:
- Cndarray der Form (n_samples,)
Die vorhergesagte Klasse.
- predict_proba(X)[Quelle]#
Kalibrierte Wahrscheinlichkeiten der Klassifizierung.
Diese Funktion gibt kalibrierte Wahrscheinlichkeiten der Klassifizierung für jede Klasse auf einem Array von Testvektoren X zurück.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Stichproben, wie sie von
estimator.predict_probaakzeptiert werden.
- Gibt zurück:
- Cndarray von Form (n_samples, n_classes)
Die vorhergesagten Wahrscheinlichkeiten.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') CalibratedClassifierCV[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') CalibratedClassifierCV[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
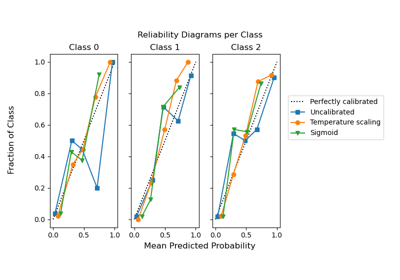
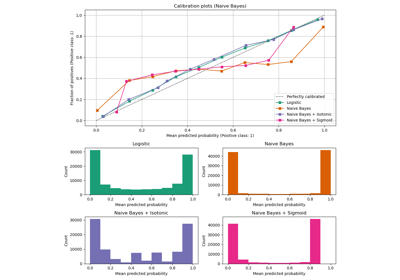
Wahrscheinlichkeitskalibrierung von Klassifikatoren
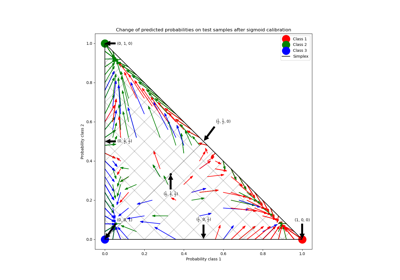
Wahrscheinlichkeitskalibrierung für 3-Klassen-Klassifikation