make_regression#
- sklearn.datasets.make_regression(n_samples=100, n_features=100, *, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)[Quelle]#
Generiert ein zufälliges Regressionsproblem.
Die Eingabe kann entweder gut konditioniert sein (standardmäßig) oder ein singuläres Profil mit geringem Rang und breiter Schwanzverteilung aufweisen. Weitere Details finden Sie unter
make_low_rank_matrix.Die Ausgabe wird durch Anwendung eines (potenziell verzerrten) zufälligen linearen Regressionsmodells mit
n_informativeNicht-Null-Regressoren auf die zuvor generierte Eingabe und etwas Gaußsches zentriertes Rauschen mit einer einstellbaren Skala generiert.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- n_samplesint, Standard=100
Die Anzahl der Stichproben.
- n_featuresint, Standard=100
Die Anzahl der Merkmale.
- n_informativeint, Standard=10
Die Anzahl der informativen Merkmale, d. h. die Anzahl der Merkmale, die zum Aufbau des linearen Modells zur Generierung der Ausgabe verwendet werden.
- n_targetsint, Standard=1
Die Anzahl der Regressionsziele, d. h. die Dimension des y-Ausgabevektors, der einem Stichproben zugeordnet ist. Standardmäßig ist die Ausgabe ein Skalar.
- biasfloat, Standard=0.0
Der Bias-Term im zugrundeliegenden linearen Modell.
- effective_rankint, Standard=None
- Wenn nicht None
Die ungefähre Anzahl von Singulärvektoren, die erforderlich sind, um die meisten Eingabedaten durch Linearkombinationen zu erklären. Die Verwendung eines solchen Singulärspektrums in der Eingabe ermöglicht es dem Generator, die in der Praxis häufig beobachteten Korrelationen zu reproduzieren.
- Wenn None
Der Eingabesatz ist gut konditioniert, zentriert und Gauß mit Einheitsvarianz.
- tail_strengthfloat, Standard=0.5
Die relative Bedeutung des breiten Rauschschwanzes des Singulärwertprofils, wenn
effective_ranknicht None ist. Wenn es sich um eine Gleitkommazahl handelt, sollte sie zwischen 0 und 1 liegen.- noisefloat, Standard=0.0
Die Standardabweichung des Gaußschen Rauschens, das auf die Ausgabe angewendet wird.
- shufflebool, Standard=True
Mischen Sie die Stichproben und die Merkmale.
- coefbool, Standard=False
Wenn True, werden die Koeffizienten des zugrundeliegenden linearen Modells zurückgegeben.
- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung für die Datenerstellung. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- Gibt zurück:
- Xndarray der Form (n_samples, n_features)
Die Eingabestichproben.
- yndarray der Form (n_samples,) oder (n_samples, n_targets)
Die Ausgabewerte.
- coefndarray der Form (n_features,) oder (n_features, n_targets)
Der Koeffizient des zugrundeliegenden linearen Modells. Er wird nur zurückgegeben, wenn coef True ist.
Beispiele
>>> from sklearn.datasets import make_regression >>> X, y = make_regression(n_samples=5, n_features=2, noise=1, random_state=42) >>> X array([[ 0.4967, -0.1382 ], [ 0.6476, 1.523], [-0.2341, -0.2341], [-0.4694, 0.5425], [ 1.579, 0.7674]]) >>> y array([ 6.737, 37.79, -10.27, 0.4017, 42.22])
Galeriebeispiele#
Auswirkung der Transformation der Ziele in einem Regressionsmodell

Anpassen eines Elastic Net mit einer voreingestellten Gram-Matrix und gewichteten Stichproben
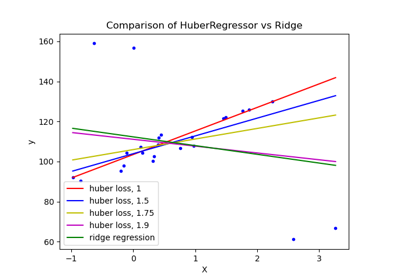
HuberRegressor vs Ridge auf Datensatz mit starken Ausreißern

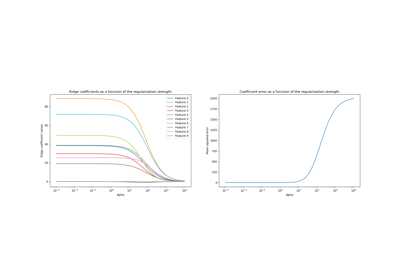
Ridge-Koeffizienten als Funktion der L2-Regularisierung
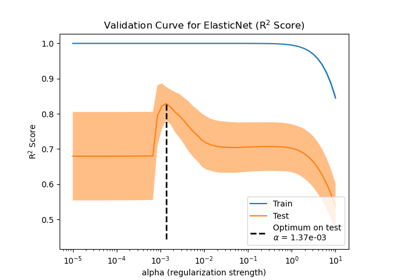
Auswirkung der Modellregularisierung auf Trainings- und Testfehler