8.3. Generierte Datensätze#
Darüber hinaus enthält scikit-learn verschiedene Zufallsstichprobengeneratoren, die zum Erstellen künstlicher Datensätze mit kontrollierter Größe und Komplexität verwendet werden können.
8.3.1. Generatoren für Klassifikation und Clustering#
Diese Generatoren erzeugen eine Matrix von Merkmalen und entsprechende diskrete Zielwerte.
8.3.1.1. Einzelnes Label#
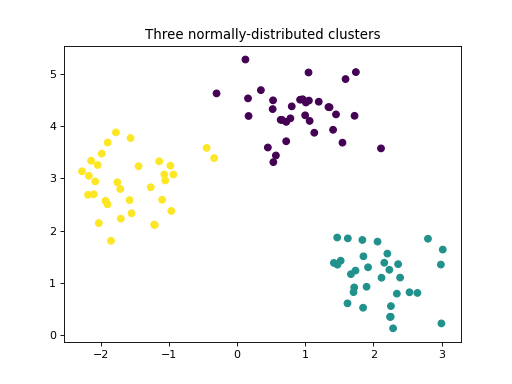
make_blobs erstellt einen Multiklassen-Datensatz, indem jeder Klasse eine normalverteilte Punktwolke zugewiesen wird. Es bietet Kontrolle über die Mittelpunkte und Standardabweichungen jedes Clusters. Dieser Datensatz wird zur Demonstration von Clustering verwendet.
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=3, cluster_std=0.5, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title("Three normally-distributed clusters")
plt.show()
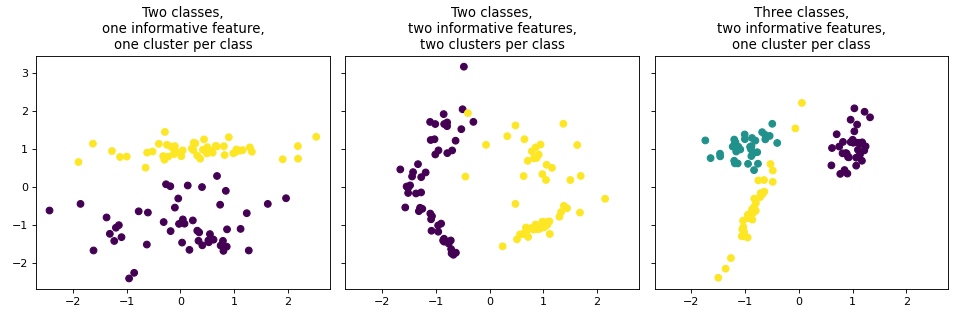
make_classification erstellt ebenfalls Multiklassen-Datensätze, ist aber auf die Einführung von Rauschen spezialisiert durch: korrelierte, redundante und uninformativen Merkmale; mehrere Gaußsche Cluster pro Klasse; und lineare Transformationen des Merkmalsraums.
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True, sharex=True)
titles = ["Two classes,\none informative feature,\none cluster per class",
"Two classes,\ntwo informative features,\ntwo clusters per class",
"Three classes,\ntwo informative features,\none cluster per class"]
params = [
{"n_informative": 1, "n_clusters_per_class": 1, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 2, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 1, "n_classes": 3}
]
for i, param in enumerate(params):
X, Y = make_classification(n_features=2, n_redundant=0, random_state=1, **param)
axs[i].scatter(X[:, 0], X[:, 1], c=Y)
axs[i].set_title(titles[i])
plt.tight_layout()
plt.show()
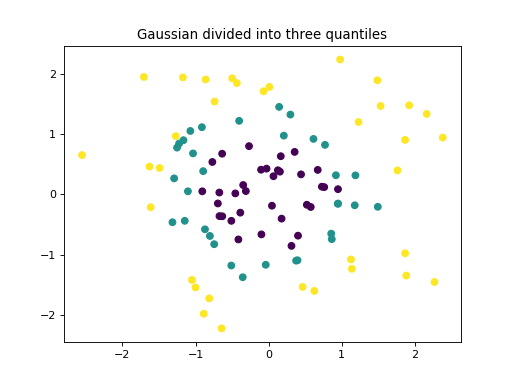
make_gaussian_quantiles teilt einen einzelnen Gaußschen Cluster in nahezu gleich große Klassen, die durch konzentrische Hyperkugeln getrennt sind.
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
X, Y = make_gaussian_quantiles(n_features=2, n_classes=3, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.title("Gaussian divided into three quantiles")
plt.show()
make_hastie_10_2 generiert ein ähnliches binäres, 10-dimensionales Problem.
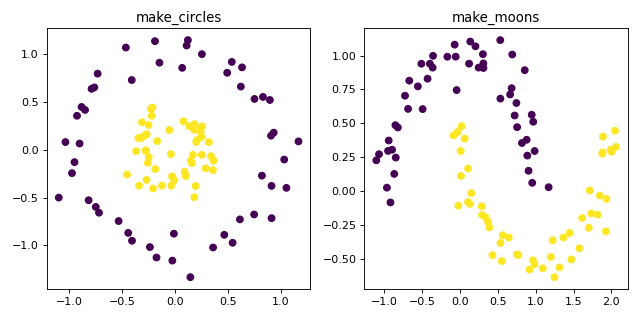
make_circles und make_moons generieren 2D-binäre Klassifikationsdatensätze, die für bestimmte Algorithmen (z. B. zentroidbasierte Clusterbildung oder lineare Klassifikation) herausfordernd sind, einschließlich optionalem Gaußschem Rauschen. Sie sind nützlich für die Visualisierung. make_circles erzeugt Gaußsche Daten mit einer sphärischen Entscheidungsgrenze für die binäre Klassifikation, während make_moons zwei ineinandergreifende Halbkreise erzeugt.
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_moons
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
X, Y = make_circles(noise=0.1, factor=0.3, random_state=0)
ax1.scatter(X[:, 0], X[:, 1], c=Y)
ax1.set_title("make_circles")
X, Y = make_moons(noise=0.1, random_state=0)
ax2.scatter(X[:, 0], X[:, 1], c=Y)
ax2.set_title("make_moons")
plt.tight_layout()
plt.show()
8.3.1.2. Mehrfach-Label#
make_multilabel_classification generiert zufällige Stichproben mit mehreren Labels, die eine Sammlung von Wörtern widerspiegeln, die aus einer Mischung von Themen gezogen wurden. Die Anzahl der Themen für jedes Dokument wird aus einer Poisson-Verteilung gezogen, und die Themen selbst werden aus einer festen Zufallsverteilung gezogen. Ähnlich wird die Anzahl der Wörter aus Poisson gezogen, wobei Wörter aus einer Multinomialen gezogen werden, wobei jedes Thema eine Wahrscheinlichkeitsverteilung über Wörter definiert. Vereinfachungen im Vergleich zu echten Bag-of-Words-Mischungen sind:
Themenbezogene Wortverteilungen werden unabhängig gezogen, während in Wirklichkeit alle von einer spärlichen Basisverteilung beeinflusst würden und korreliert wären.
Für ein aus mehreren Themen generiertes Dokument werden alle Themen bei der Erzeugung seiner Wortsammlung gleich gewichtet.
Dokumente ohne Labels, Wörter zufällig, anstatt aus einer Basisverteilung.

8.3.1.3. Biclustering#
|
Generiert ein Array mit konstanter Blockdiagonalstruktur für Biclustering. |
|
Generiert ein Array mit Block-Schachbrettstruktur für Biclustering. |
8.3.2. Generatoren für Regression#
make_regression erzeugt Regressionsziele als eine optional spärliche zufällige lineare Kombination von zufälligen Merkmalen mit Rauschen. Seine informativen Merkmale können unkorreliert oder von niedrigem Rang sein (wenige Merkmale erklären den Großteil der Varianz).
Andere Regressionsgeneratoren erzeugen Funktionen deterministisch aus randomisierten Merkmalen. make_sparse_uncorrelated erzeugt ein Ziel als lineare Kombination von vier Merkmalen mit festen Koeffizienten. Andere kodieren explizit nichtlineare Beziehungen: make_friedman1 steht in Beziehung durch Polynom- und Sinus-Transformationen; make_friedman2 beinhaltet Merkmalmultiplikation und Kehrwertbildung; und make_friedman3 ist ähnlich mit einer Arkustangens-Transformation des Ziels.
8.3.3. Generatoren für Manifold Learning#
|
Generiert einen S-Kurven-Datensatz. |
|
Generiert einen Swiss-Roll-Datensatz. |
8.3.4. Generatoren für Dekomposition#
|
Generiert eine hauptsächlich niedrigrangige Matrix mit glockenförmigen singulären Werten. |
|
Generiert ein Signal als dünne Kombination von Wörterbuchelementen. |
|
Generiert eine zufällige symmetrische, positiv-definite Matrix. |
|
Generiert eine dünne symmetrische positiv-definite Matrix. |