9.1. Strategien zur rechnerischen Skalierung: größere Daten#
Für einige Anwendungen stellen die Menge der Beispiele, Merkmale (oder beides) und/oder die Geschwindigkeit, mit der sie verarbeitet werden müssen, eine Herausforderung für traditionelle Ansätze dar. In diesen Fällen bietet scikit-learn eine Reihe von Optionen, die Sie in Betracht ziehen können, um Ihr System zu skalieren.
9.1.1. Skalierung mit Instanzen durch Out-of-Core-Lernen#
Out-of-Core-Lernen (oder „Externer Speicher“-Lernen) ist eine Technik, die zum Lernen aus Daten verwendet wird, die nicht in den Hauptspeicher eines Computers (RAM) passen.
Hier ist ein Entwurf eines Systems, das dieses Ziel erreichen soll
eine Möglichkeit, Instanzen zu streamen
eine Möglichkeit, Merkmale aus Instanzen zu extrahieren
ein inkrementeller Algorithmus
9.1.1.1. Instanzen streamen#
Grundsätzlich kann 1. ein Reader sein, der Instanzen aus Dateien auf einer Festplatte, einer Datenbank, aus einem Netzwerkstream usw. liefert. Details zur Erreichung dessen liegen jedoch außerhalb des Rahmens dieser Dokumentation.
9.1.1.2. Merkmale extrahieren#
2. kann jede relevante Methode zur Extraktion von Merkmalen unter den verschiedenen von scikit-learn unterstützten Merkmal extraktionsmethoden sein. Bei der Arbeit mit Daten, die vektorisiert werden müssen und bei denen die Menge der Merkmale oder Werte nicht im Voraus bekannt ist, sollte jedoch besondere Sorgfalt walten. Ein gutes Beispiel ist die Textklassifizierung, bei der während des Trainings wahrscheinlich unbekannte Begriffe gefunden werden. Es ist möglich, einen zustandsbehafteten Vektorisierer zu verwenden, wenn mehrere Durchläufe über die Daten aus Sicht der Anwendung sinnvoll sind. Andernfalls kann man die Schwierigkeit durch die Verwendung eines zustandslosen Merkmals extraktors erhöhen. Derzeit ist die bevorzugte Methode hierfür die Verwendung des sogenannten Hashing-Tricks, wie er von sklearn.feature_extraction.FeatureHasher für Datensätze mit kategorialen Variablen, die als Liste von Python-Dicts dargestellt sind, oder sklearn.feature_extraction.text.HashingVectorizer für Textdokumente implementiert ist.
9.1.1.3. Inkrementelles Lernen#
Schließlich haben wir für 3. eine Reihe von Optionen innerhalb von scikit-learn. Obwohl nicht alle Algorithmen inkrementell lernen können (d.h. ohne alle Instanzen auf einmal zu sehen), sind alle Schätzer, die die partial_fit API implementieren, Kandidaten. Tatsächlich ist die Fähigkeit, inkrementell aus einem Mini-Batch von Instanzen zu lernen (manchmal auch als „Online-Lernen“ bezeichnet), entscheidend für das Out-of-Core-Lernen, da sie garantiert, dass zu jedem gegebenen Zeitpunkt nur eine kleine Menge von Instanzen im Hauptspeicher vorhanden ist. Die Wahl einer guten Größe für den Mini-Batch, die Relevanz und Speicherbedarf ausgleicht, kann einige Abstimmung erfordern [1].
Hier ist eine Liste von inkrementellen Schätzern für verschiedene Aufgaben
Für die Klassifizierung ist es etwas wichtig zu beachten, dass, obwohl eine zustandslose Merkmals extraktionsroutine mit neuen/unbekannten Attributen umgehen kann, der inkrementelle Lerner selbst möglicherweise nicht mit neuen/unbekannten Zielklassen umgehen kann. In diesem Fall müssen Sie alle möglichen Klassen mit dem ersten partial_fit Aufruf über den classes= Parameter übergeben.
Ein weiterer Aspekt, der bei der Wahl eines geeigneten Algorithmus zu berücksichtigen ist, ist, dass nicht alle von ihnen jeder Instanz im Laufe der Zeit die gleiche Bedeutung beimessen. Insbesondere der Perceptron ist auch nach vielen Beispielen noch empfindlich gegenüber falsch beschrifteten Beispielen, während die SGD* Familie robuster gegenüber dieser Art von Artefakten ist. Umgekehrt neigen letztere dazu, bemerkenswert unterschiedlichen, aber korrekt beschrifteten Beispielen weniger Bedeutung beizumessen, wenn sie spät im Stream eintreffen, da ihre Lernrate im Laufe der Zeit abnimmt.
9.1.1.4. Beispiele#
Schließlich haben wir ein vollständiges Beispiel für die Out-of-Core-Klassifizierung von Textdokumenten. Es soll als Ausgangspunkt für Personen dienen, die Out-of-Core-Lernsysteme aufbauen möchten, und demonstriert die meisten der oben genannten Konzepte.
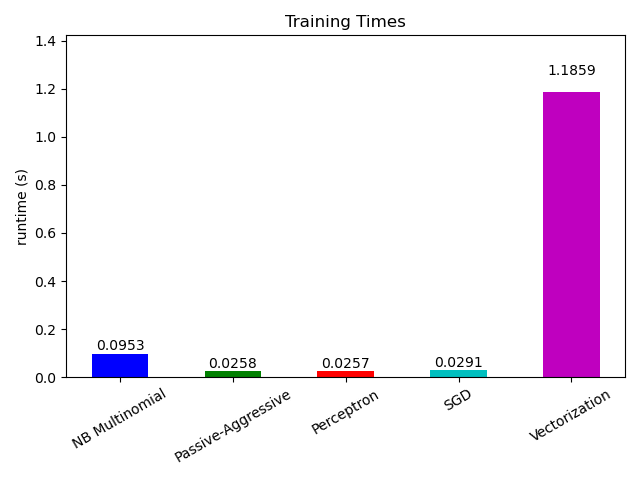
Darüber hinaus zeigt es auch die Entwicklung der Leistung verschiedener Algorithmen mit der Anzahl der verarbeiteten Beispiele.
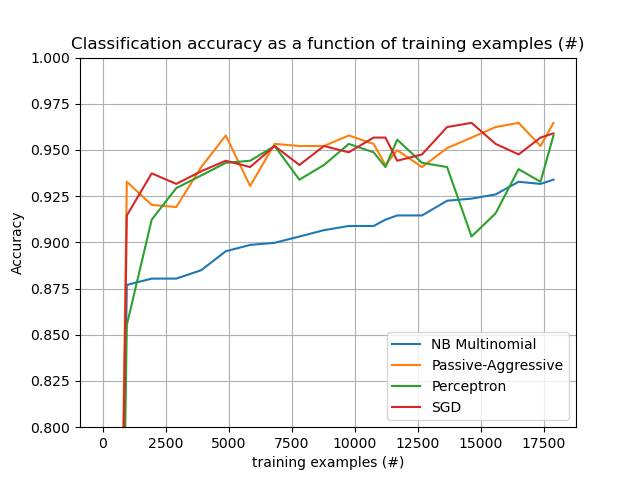
Wenn wir uns nun die Berechnungszeit der verschiedenen Teile ansehen, stellen wir fest, dass die Vektorisierung weitaus teurer ist als das Lernen selbst. Von den verschiedenen Algorithmen ist MultinomialNB am teuersten, aber sein Overhead kann durch Erhöhung der Mini-Batch-Größe gemildert werden (Übung: Ändern Sie minibatch_size auf 100 und 10000 im Programm und vergleichen Sie).