StandardScaler#
- class sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)[Quelle]#
Standardisiert Merkmale durch Entfernen des Mittelwerts und Skalierung auf Einheitsvarianz.
Der Standardwert eines Samples
xwird berechnet alsz = (x - u) / s
wobei
uder Mittelwert der Trainingssamples ist oder Null, wennwith_mean=Falseist, undsdie Standardabweichung der Trainingssamples ist oder Eins, wennwith_std=Falseist.Zentrierung und Skalierung erfolgen unabhängig voneinander für jede Merkmal, indem die relevanten Statistiken anhand der Samples im Trainingsdatensatz berechnet werden. Mittelwert und Standardabweichung werden dann gespeichert, um sie später mit
transformfür neue Daten zu verwenden.Die Standardisierung eines Datensatzes ist eine häufige Anforderung für viele Machine-Learning-Schätzer: Sie können sich schlecht verhalten, wenn die einzelnen Merkmale nicht mehr oder weniger wie standardmäßig normalverteilte Daten aussehen (z. B. Gaußsche Verteilung mit 0 Mittelwert und Einheitsvarianz).
Zum Beispiel gehen viele Elemente, die in der Zielfunktion eines Lernalgorithmus verwendet werden (wie der RBF-Kernel von Support Vector Machines oder die L1- und L2-Regularisierer von linearen Modellen), davon aus, dass alle Merkmale um 0 zentriert sind und eine Varianz in derselben Größenordnung aufweisen. Wenn ein Merkmal eine Varianz aufweist, die um Größenordnungen größer ist als die anderen, kann es die Zielfunktion dominieren und dazu führen, dass der Schätzer nicht korrekt von den anderen Merkmalen wie erwartet lernen kann.
StandardScalerist empfindlich gegenüber Ausreißern, und die Merkmale können sich im Beisein von Ausreißern unterschiedlich skalieren. Eine Beispielvisualisierung finden Sie unter Vergleichen von StandardScaler mit anderen Skalierern.Dieser Skalierer kann auch auf spärliche CSR- oder CSC-Matrizen angewendet werden, indem
with_mean=Falseübergeben wird, um die Sparsity-Struktur der Daten nicht zu beeinträchtigen.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- copybool, Standard=True
Wenn False, versuchen Sie, eine Kopie zu vermeiden und stattdessen eine In-Place-Skalierung durchzuführen. Dies garantiert nicht immer eine In-Place-Skalierung. z. B. wenn die Daten keine NumPy-Array oder scipy.sparse CSR-Matrix sind, kann immer noch eine Kopie zurückgegeben werden.
- with_meanbool, Standardwert=True
Wenn True, werden die Daten vor der Skalierung zentriert. Dies funktioniert nicht (und löst eine Ausnahme aus), wenn es auf spärliche Matrizen angewendet wird, da deren Zentrierung den Aufbau einer dichten Matrix beinhaltet, die in gängigen Anwendungsfällen wahrscheinlich zu groß ist, um in den Speicher zu passen.
- with_stdbool, Standardwert=True
Wenn True, werden die Daten auf Einheitsvarianz (oder gleichbedeutend, Einheitsstandardabweichung) skaliert.
- Attribute:
- scale_ndarray der Form (n_features,) oder None
Pro Merkmal relative Skalierung der Daten, um Nullmittelwert und Einheitsvarianz zu erreichen. Im Allgemeinen wird dies mit
np.sqrt(var_)berechnet. Wenn eine Varianz Null ist, können wir keine Einheitsvarianz erreichen und die Daten werden unverändert gelassen, was einen Skalierungsfaktor von 1 ergibt.scale_ist gleichNone, wennwith_std=False.Hinzugefügt in Version 0.17: scale_
- mean_ndarray der Form (n_features,) oder None
Der Mittelwert für jedes Merkmal im Trainingsdatensatz. Ist gleich
None, wennwith_mean=Falseundwith_std=False.- var_ndarray der Form (n_features,) oder None
Die Varianz für jedes Merkmal im Trainingsdatensatz. Wird zur Berechnung von
scale_verwendet. Ist gleichNone, wennwith_mean=Falseundwith_std=False.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_samples_seen_int oder ndarray der Form (n_features,)
Die Anzahl der vom Schätzer verarbeiteten Samples für jedes Merkmal. Wenn keine fehlenden Samples vorhanden sind, ist
n_samples_seeneine Ganzzahl, andernfalls ist es ein Array vom Typ int. Wennsample_weightverwendet wird, ist es eine Gleitkommazahl (wenn keine fehlenden Daten vorhanden sind) oder ein Array vom Typ float, das die bisher gesehenen Gewichte summiert. Wird bei neuen Aufrufen von fit zurückgesetzt, inkrementiert aber überpartial_fit-Aufrufe hinweg.
Siehe auch
Anmerkungen
NaNs werden als fehlende Werte behandelt: bei fit ignoriert und bei transform beibehalten.
Wir verwenden einen verzerrten Schätzer für die Standardabweichung, äquivalent zu
numpy.std(x, ddof=0). Beachten Sie, dass die Wahl vonddofdie Modellleistung wahrscheinlich nicht beeinträchtigt.Beispiele
>>> from sklearn.preprocessing import StandardScaler >>> data = [[0, 0], [0, 0], [1, 1], [1, 1]] >>> scaler = StandardScaler() >>> print(scaler.fit(data)) StandardScaler() >>> print(scaler.mean_) [0.5 0.5] >>> print(scaler.transform(data)) [[-1. -1.] [-1. -1.] [ 1. 1.] [ 1. 1.]] >>> print(scaler.transform([[2, 2]])) [[3. 3.]]
- fit(X, y=None, sample_weight=None)[Quelle]#
Berechnet den Mittelwert und die Standardabweichung für die spätere Skalierung.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Daten, die zur Berechnung des Mittelwerts und der Standardabweichung für die spätere Skalierung entlang der Merkmalachse verwendet werden.
- yNone
Ignoriert.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Individuelle Gewichte für jede Stichprobe.
Hinzugefügt in Version 0.24: Parameterunterstützung für sample_weight für StandardScaler.
- Gibt zurück:
- selfobject
Gefitteter Scaler.
- fit_transform(X, y=None, **fit_params)[Quelle]#
An Daten anpassen, dann transformieren.
Passt den Transformer an
Xundymit optionalen Parameternfit_paramsan und gibt eine transformierte Version vonXzurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabestichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs), Standardwert=None
Zielwerte (None für unüberwachte Transformationen).
- **fit_paramsdict
Zusätzliche Fit-Parameter. Nur übergeben, wenn der Estimator zusätzliche Parameter in seiner
fit-Methode akzeptiert.
- Gibt zurück:
- X_newndarray array der Form (n_samples, n_features_new)
Transformiertes Array.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
Wenn
input_featuresNoneist, werdenfeature_names_in_als Merkmalnamen verwendet. Wennfeature_names_in_nicht definiert ist, werden die folgenden Eingabemerkmalsnamen generiert:["x0", "x1", ..., "x(n_features_in_ - 1)"].Wenn
input_featuresein Array-ähnliches Objekt ist, mussinput_featuresmitfeature_names_in_übereinstimmen, wennfeature_names_in_definiert ist.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Gleich wie Eingabemerkmale.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X, copy=None)[Quelle]#
Skaliert die Daten zurück in die ursprüngliche Darstellung.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Daten, die zur Skalierung entlang der Merkmal-Achse verwendet werden.
- copybool, Standardwert=None
Kopieren Sie das Eingabe-
Xoder nicht.
- Gibt zurück:
- X_original{ndarray, sparse matrix} der Form (n_samples, n_features)
Transformiertes Array.
- partial_fit(X, y=None, sample_weight=None)[Quelle]#
Online-Berechnung des Mittelwerts und der Standardabweichung von X für die spätere Skalierung.
Alle von X werden als ein einziger Batch verarbeitet. Dies ist für Fälle gedacht, in denen
fitaufgrund einer sehr großen Anzahl vonn_samplesnicht möglich ist oder weil X aus einem kontinuierlichen Strom gelesen wird.Der Algorithmus für inkrementellen Mittelwert und Standardabweichung ist in Gleichung 1.5a,b in Chan, Tony F., Gene H. Golub und Randall J. LeVeque. "Algorithms for computing the sample variance: Analysis and recommendations." The American Statistician 37.3 (1983): 242-247 angegeben.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Daten, die zur Berechnung des Mittelwerts und der Standardabweichung für die spätere Skalierung entlang der Merkmalachse verwendet werden.
- yNone
Ignoriert.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Individuelle Gewichte für jede Stichprobe.
Hinzugefügt in Version 0.24: Parameterunterstützung für sample_weight für StandardScaler.
- Gibt zurück:
- selfobject
Gefitteter Scaler.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') StandardScaler[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_inverse_transform_request(*, copy: bool | None | str = '$UNCHANGED$') StandardScaler[Quelle]#
Konfiguriert, ob Metadaten für die Methode
inverse_transformangefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, aninverse_transformübergeben. Die Anfrage wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Estimator übergibt sie nicht aninverse_transform.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- copystr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
copyininverse_transform.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_partial_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') StandardScaler[Quelle]#
Konfiguriert, ob Metadaten für die
partial_fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und anpartial_fitübergeben, wenn sie bereitgestellt werden. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anpartial_fit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinpartial_fit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') StandardScaler[Quelle]#
Konfiguriert, ob Metadaten für die
transform-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, antransformweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht antransform.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- copystr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
copyintransform.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- transform(X, copy=None)[Quelle]#
Führt die Standardisierung durch Zentrierung und Skalierung durch.
- Parameter:
- X{array-like, sparse matrix der Form (n_samples, n_features)
Die Daten, die zur Skalierung entlang der Merkmal-Achse verwendet werden.
- copybool, Standardwert=None
Kopiert die Eingabe X oder nicht.
- Gibt zurück:
- X_tr{ndarray, sparse matrix} mit der Form (n_samples, n_features)
Transformiertes Array.
Galeriebeispiele#
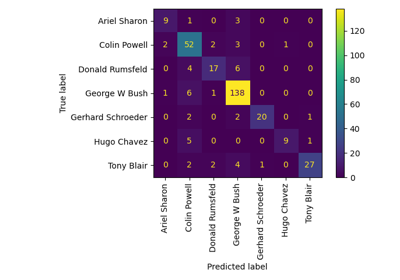
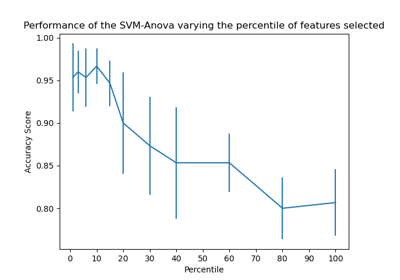
Gesichtserkennungsbeispiel mit Eigenfaces und SVMs

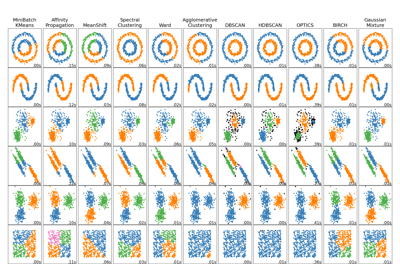
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen
Eine Demo des K-Means Clusterings auf den handschriftlichen Zifferndaten
Vergleich verschiedener hierarchischer Linkage-Methoden auf Toy-Datensätzen
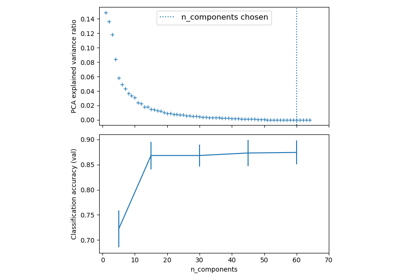
Pipelining: Verkettung einer PCA und einer logistischen Regression
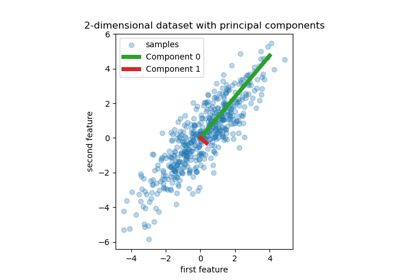
Principal Component Regression vs. Partial Least Squares Regression
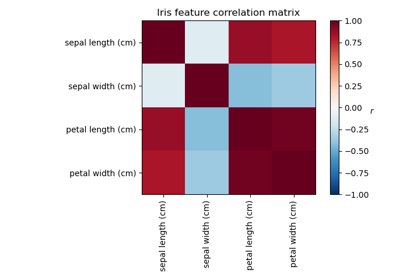
Faktorenanalyse (mit Rotation) zur Visualisierung von Mustern
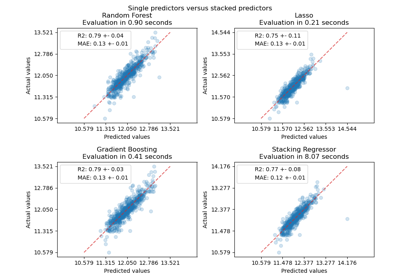
Visualisierung der probabilistischen Vorhersagen eines VotingClassifier
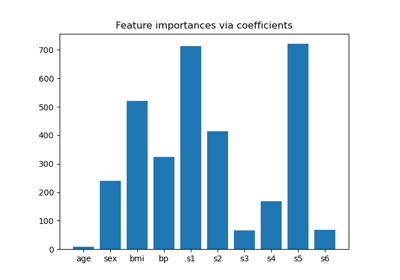
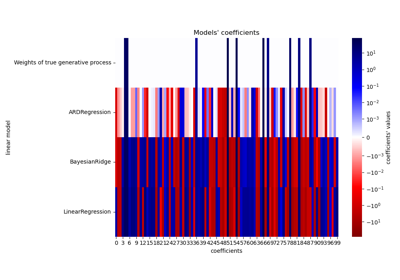
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle
Regularisierungspfad der L1-Logistischen Regression

Poisson-Regression und nicht-normale Verlustfunktion
MNIST-Klassifikation mittels multinomialer Logistik + L1




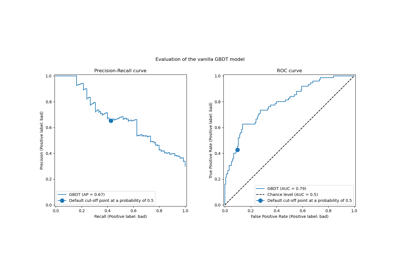
Post-Hoc-Anpassung des Entscheidungsschwellenwerts für kostenempfindliches Lernen
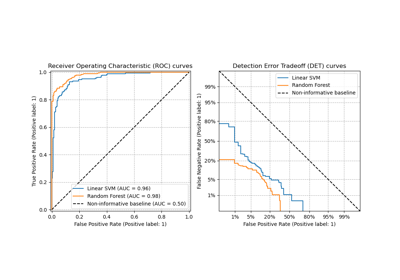
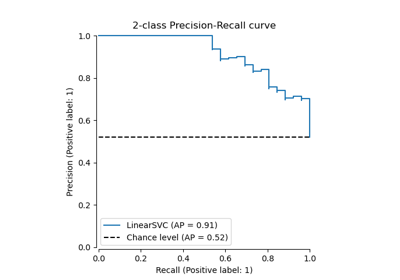
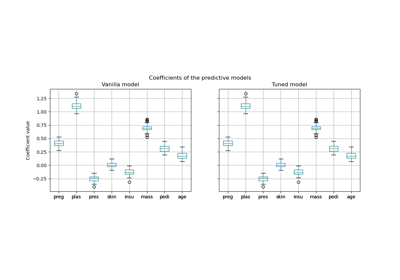
Post-hoc-Anpassung des Cut-off-Punkts der Entscheidungskfunktion
Vergleich von Nächsten Nachbarn mit und ohne Neighborhood Components Analysis
Dimensionsreduktion mit Neighborhood Components Analysis
Variierende Regularisierung im Multi-Layer Perceptron

Vergleich der Auswirkungen verschiedener Skalierer auf Daten mit Ausreißern