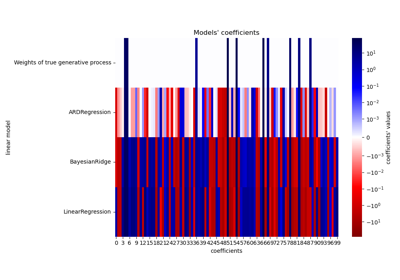
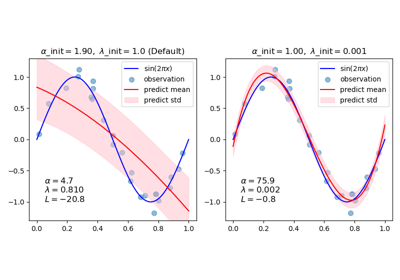
BayesianRidge#
- class sklearn.linear_model.BayesianRidge(*, max_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, copy_X=True, verbose=False)[Quelle]#
Bayes'sche Ridge-Regression.
Passen Sie ein bayessches Ridge-Modell an. Details zur Implementierung und zur Optimierung der Regularisierungsparameter lambda (Präzision der Gewichte) und alpha (Präzision des Rauschens) finden Sie im Abschnitt "Hinweise".
Lesen Sie mehr im Benutzerhandbuch. Eine intuitive Visualisierung, wie eine Sinuskurve mit einem Polynom unter Verwendung verschiedener Paare von Anfangswerten angenähert wird, finden Sie unter Kurvenanpassung mit bayesscher Ridge-Regression.
- Parameter:
- max_iterint, Standard=300
Maximale Anzahl von Iterationen über den gesamten Datensatz, bevor unabhängig von einem Kriterien zur frühzeitigen Beendigung gestoppt wird.
Geändert in Version 1.3.
- tolfloat, Standard=1e-3
Stoppen Sie den Algorithmus, wenn w konvergiert ist.
- alpha_1float, Standardwert=1e-6
Hyperparameter: Formparameter für die Gamma-Verteilung-A-priori-Verteilung für den Parameter alpha.
- alpha_2float, Standardwert=1e-6
Hyperparameter: Inverser Skalenparameter (Ratenparameter) für die Gamma-Verteilung-A-priori-Verteilung für den Parameter alpha.
- lambda_1float, Standardwert=1e-6
Hyperparameter: Formparameter für die Gamma-Verteilung-A-priori-Verteilung für den Parameter lambda.
- lambda_2float, Standardwert=1e-6
Hyperparameter: Inverser Skalenparameter (Ratenparameter) für die Gamma-Verteilung-A-priori-Verteilung für den Parameter lambda.
- alpha_initfloat, Standardwert=None
Anfangswert für alpha (Präzision des Rauschens). Wenn nicht gesetzt, ist alpha_init = 1/Var(y).
Hinzugefügt in Version 0.22.
- lambda_initfloat, Standardwert=None
Anfangswert für lambda (Präzision der Gewichte). Wenn nicht gesetzt, ist lambda_init = 1.
Hinzugefügt in Version 0.22.
- compute_scorebool, Standardwert=False
Wenn True, berechnen Sie die logarithmische marginale Likelihood bei jeder Iteration der Optimierung.
- fit_interceptbool, Standardwert=True
Ob der Achsenabschnitt für dieses Modell berechnet werden soll. Der Achsenabschnitt wird nicht als probabilistische Größe behandelt und hat daher keine zugehörige Varianz. Wenn auf False gesetzt, wird kein Achsenabschnitt in den Berechnungen verwendet (d. h. es wird erwartet, dass die Daten zentriert sind).
- copy_Xbool, Standardwert=True
Wenn True, wird X kopiert; andernfalls kann es überschrieben werden.
- verbosebool, default=False
Verbose-Modus beim Anpassen des Modells.
- Attribute:
- coef_array-ähnlich der Form (n_features,)
Koeffizienten des Regressionsmodells (Mittelwert der Verteilung)
- intercept_float
Unabhängiger Term in der Entscheidungsfunktion. Auf 0.0 gesetzt, wenn
fit_intercept = False.- alpha_float
Geschätzte Präzision des Rauschens.
- lambda_float
Geschätzte Präzision der Gewichte.
- sigma_array-like, Form (n_features, n_features)
Geschätzte Kovarianzmatrix der Gewichte.
- scores_array-like, Form (n_iter_+1,)
Wenn computed_score True ist, Wert der logarithmischen marginalen Likelihood (zu maximieren) bei jeder Iteration der Optimierung. Das Array beginnt mit dem Wert der logarithmischen marginalen Likelihood, der für die Anfangswerte von alpha und lambda erzielt wurde, und endet mit dem Wert, der für die geschätzten alpha und lambda erzielt wurde.
- n_iter_int
Die tatsächliche Anzahl der Iterationen, um das Abbruchkriterium zu erreichen.
- X_offset_ndarray, Form (n_features,)
Wenn
fit_intercept=True, abgezogener Offset zur Zentrierung der Daten auf einen Nullmittelwert. Andernfalls auf np.zeros(n_features) gesetzt.- X_scale_ndarray, Form (n_features,)
Auf np.ones(n_features) gesetzt.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
ARDRegressionBayes'sche ARD-Regression.
Anmerkungen
Es gibt mehrere Strategien zur Durchführung der bayesschen Ridge-Regression. Diese Implementierung basiert auf dem Algorithmus, der in Anhang A von (Tipping, 2001) beschrieben ist, wobei die Aktualisierungen der Regularisierungsparameter wie in (MacKay, 1992) vorgeschlagen werden. Beachten Sie, dass gemäß "A New View of Automatic Relevance Determination" (Wipf und Nagarajan, 2008) diese Aktualisierungsregeln nicht garantieren, dass die marginale Likelihood zwischen zwei aufeinanderfolgenden Iterationen der Optimierung steigt.
Referenzen
D. J. C. MacKay, Bayesian Interpolation, Computation and Neural Systems, Vol. 4, No. 3, 1992.
M. E. Tipping, Sparse Bayesian Learning and the Relevance Vector Machine, Journal of Machine Learning Research, Vol. 1, 2001.
Beispiele
>>> from sklearn import linear_model >>> clf = linear_model.BayesianRidge() >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) BayesianRidge() >>> clf.predict([[1, 1]]) array([1.])
- fit(X, y, sample_weight=None)[Quelle]#
Passen Sie das Modell an.
- Parameter:
- Xndarray der Form (n_samples, n_features)
Trainingsdaten.
- yndarray der Form (n_samples,)
Zielwerte. Wird bei Bedarf in den Datentyp von X umgewandelt.
- sample_weightndarray, Form (n_samples,), Standardwert=None
Individuelle Gewichte für jede Stichprobe.
Hinzugefügt in Version 0.20: Unterstützung für den Parameter sample_weight für BayesianRidge.
- Gibt zurück:
- selfobject
Gibt die Instanz selbst zurück.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X, return_std=False)[Quelle]#
Vorhersage mit dem linearen Modell.
Neben dem Mittelwert der prädiktiven Verteilung kann auch dessen Standardabweichung zurückgegeben werden.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Stichproben.
- return_stdbool, Standard=False
Ob die Standardabweichung der Posterior-Vorhersage zurückgegeben werden soll.
- Gibt zurück:
- y_meanarray-like, Form (n_samples,)
Mittelwert der prädiktiven Verteilung von Abfragepunkten.
- y_stdarray-like, Form (n_samples,)
Standardabweichung der Vorhersageverteilung von Abfragepunkten.
- score(X, y, sample_weight=None)[Quelle]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmtheitskoeffizient, \(R^2\), ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen
((y_true - y_pred)** 2).sum()ist und \(v\) die gesamte Summe der quadrierten Abweichungen vom Mittelwert((y_true - y_true.mean()) ** 2).sum()ist. Der bestmögliche Score ist 1.0 und kann negativ sein (da das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den Erwartungswert vonyvorhersagt, ohne die Eingabemerkmale zu berücksichtigen, würde einen \(R^2\)-Score von 0.0 erzielen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der beim Aufruf von
scoreauf einem Regressor verwendet wird, nutzt ab Version 0.23multioutput='uniform_average', um konsistent mit dem Standardwert vonr2_scorezu bleiben. Dies beeinflusst diescore-Methode aller Multioutput-Regressoren (außerMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BayesianRidge[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_predict_request(*, return_std: bool | None | str = '$UNCHANGED$') BayesianRidge[Quelle]#
Konfiguriert, ob Metadaten für die
predict-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anpredictweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht anpredict.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- return_stdstr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
return_stdinpredict.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BayesianRidge[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
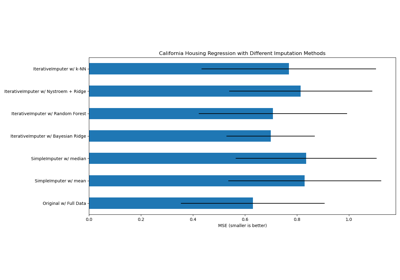
Fehlende Werte mit Varianten von IterativeImputer imputieren

Fehlende Werte imputieren, bevor ein Schätzer erstellt wird