NearestCentroid#
- class sklearn.neighbors.NearestCentroid(metric='euclidean', *, shrink_threshold=None, priors='uniform')[Quelle]#
Nächster-Zentroid-Klassifikator.
Jede Klasse wird durch ihren Zentroiden dargestellt, wobei Teststichproben der Klasse mit dem nächstgelegenen Zentroiden zugeordnet werden.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- metric{„euclidean“, „manhattan“}, default=”euclidean”
Metrik zur Berechnung der Distanz.
Wenn
metric="euclidean", ist der Zentroid für die Stichproben, die jeder Klasse entsprechen, das arithmetische Mittel, das die Summe der quadrierten L1-Distanzen minimiert. Wennmetric="manhattan", ist der Zentroid der merkmalweise Median, der die Summe der L1-Distanzen minimiert.Geändert in Version 1.5: Alle Metriken außer
"euclidean"und"manhattan"wurden als veraltet markiert und lösen nun einen Fehler aus.Geändert in Version 0.19:
metric='precomputed'wurde als veraltet markiert und löst nun einen Fehler aus.- shrink_thresholdfloat, default=None
Schwellenwert zum Schrumpfen von Centroiden, um Merkmale zu entfernen.
- priors{„uniform“, „empirical“} oder array-ähnlich der Form (n_classes,), default=”uniform”
Die a-priori-Wahrscheinlichkeiten der Klassen. Standardmäßig werden die Klassenproportionen aus den Trainingsdaten abgeleitet.
Hinzugefügt in Version 1.6.
- Attribute:
- centroids_array-ähnlich der Form (n_classes, n_features)
Centroid jeder Klasse.
- classes_array von Form (n_classes,)
Die eindeutigen Klassennamen.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- deviations_ndarray der Form (n_classes, n_features)
Abweichungen (oder Schrumpfungen) der Centroiden jeder Klasse vom Gesamtcentroid. Gleich der Gleichung (18.4), wenn
shrink_threshold=None, ansonsten (18.5) S. 653 von [2]. Kann zur Identifizierung von Merkmalen verwendet werden, die für die Klassifizierung verwendet werden.Hinzugefügt in Version 1.6.
- within_class_std_dev_ndarray der Form (n_features,)
Gepoolte oder klasseninterne Standardabweichung der Eingabedaten.
Hinzugefügt in Version 1.6.
- class_prior_ndarray der Form (n_classes,)
Die a-priori-Wahrscheinlichkeiten der Klassen.
Hinzugefügt in Version 1.6.
Siehe auch
KNeighborsClassifierNearest neighbors Klassifikator.
Anmerkungen
Bei Verwendung für die Textklassifizierung mit tf-idf-Vektoren ist dieser Klassifikator auch als Rocchio-Klassifikator bekannt.
Referenzen
[1] Tibshirani, R., Hastie, T., Narasimhan, B., & Chu, G. (2002). Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proceedings of the National Academy of Sciences of the United States of America, 99(10), 6567-6572. The National Academy of Sciences.
[2] Hastie, T., Tibshirani, R., Friedman, J. (2009). The Elements of Statistical Learning Data Mining, Inference, and Prediction. 2. Auflage. New York, Springer.
Beispiele
>>> from sklearn.neighbors import NearestCentroid >>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = NearestCentroid() >>> clf.fit(X, y) NearestCentroid() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[Quelle]#
Anwenden der Entscheidungfunktion auf ein Array von Stichproben.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array von Stichproben (Testvektoren).
- Gibt zurück:
- y_scoresndarray der Form (n_samples,) oder (n_samples, n_classes)
Entscheidungsfunktionswerte, die sich auf jede Klasse pro Stichprobe beziehen. Im Fall von zwei Klassen hat die Form
(n_samples,)und gibt das Log-Likelihood-Verhältnis der positiven Klasse an.
- fit(X, y)[Quelle]#
Anpassen des NearestCentroid-Modells an die gegebenen Trainingsdaten.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Trainingsvektor, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist. Beachten Sie, dass das Schrumpfen von Centroiden nicht mit spärlichen Matrizen verwendet werden kann.- yarray-like von Form (n_samples,)
Zielwerte.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Durchführung der Klassifizierung für ein Array von Testvektoren
X.Die vorhergesagte Klasse
Cfür jede Stichprobe inXwird zurückgegeben.- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Die vorhergesagten Klassen.
- predict_log_proba(X)[Quelle]#
Schätzung der Logarithmus-Klassenwahrscheinlichkeiten.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- y_log_probandarray der Form (n_samples, n_classes)
Geschätzte Log-Wahrscheinlichkeiten.
- predict_proba(X)[Quelle]#
Schätzung der Klassenwahrscheinlichkeiten.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- y_probandarray der Form (n_samples, n_classes)
Wahrscheinlichkeitsschätzung der Stichprobe für jede Klasse im Modell, wobei die Klassen in der Reihenfolge von
self.classes_sortiert sind.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') NearestCentroid[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
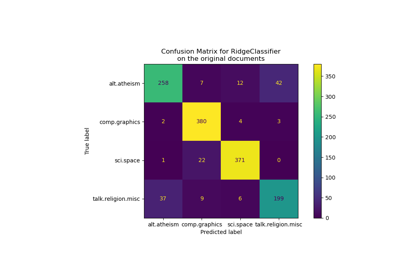
Klassifikation von Textdokumenten mit spärlichen Merkmalen