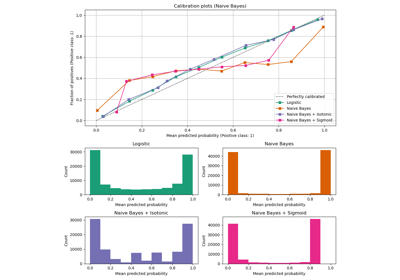
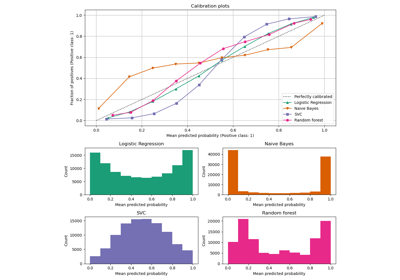
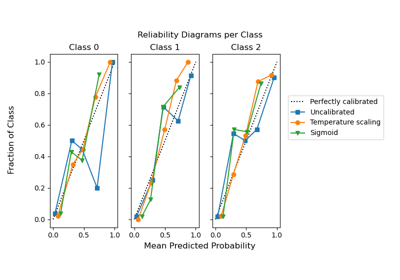
CalibrationDisplay#
- class sklearn.calibration.CalibrationDisplay(prob_true, prob_pred, y_prob, *, estimator_name=None, pos_label=None)[Quelle]#
Visualisierung der Kalibrierungskurve (auch bekannt als Zuverlässigkeitsdiagramm).
Es wird empfohlen,
from_estimatoroderfrom_predictionszu verwenden, um einCalibrationDisplayzu erstellen. Alle Parameter werden als Attribute gespeichert.Lesen Sie mehr über Kalibrierung im Benutzerhandbuch und mehr über die scikit-learn Visualisierungs-API unter Visualisierungen.
Ein Beispiel für die Verwendung der Visualisierung finden Sie unter Kalibrierungskurven für Wahrscheinlichkeiten.
Hinzugefügt in Version 1.0.
- Parameter:
- prob_truendarray der Form (n_bins,)
Der Anteil der Stichproben, deren Klasse die positive Klasse ist (Anteil positiver Fälle), in jedem Bin.
- prob_predndarray der Form (n_bins,)
Die mittlere vorhergesagte Wahrscheinlichkeit in jedem Bin.
- y_probndarray der Form (n_samples,)
Vorhergesagte Wahrscheinlichkeiten für die positive Klasse für jede Stichprobe.
- estimator_namestr, Standardwert=None
Name des Schätzers. Wenn None, wird der Name des Schätzers nicht angezeigt.
- pos_labelint, float, bool oder str, Standardwert=None
Die positive Klasse, wenn die Kalibrierungskurve berechnet wird. Wenn nicht
None, wird dieser Wert in den Beschriftungen der x- und y-Achsen angezeigt.Hinzugefügt in Version 1.1.
- Attribute:
- line_matplotlib Artist
Kalibrierungskurve.
- ax_matplotlib Axes
Achsen mit Kalibrierungskurve.
- figure_matplotlib Figure
Abbildung, die die Kurve enthält.
Siehe auch
calibration_curveBerechnet wahre und vorhergesagte Wahrscheinlichkeiten für eine Kalibrierungskurve.
CalibrationDisplay.from_predictionsZeichnet die Kalibrierungskurve mithilfe von wahren und vorhergesagten Labels.
CalibrationDisplay.from_estimatorZeichnet die Kalibrierungskurve mithilfe eines Schätzers und Daten.
Beispiele
>>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.calibration import calibration_curve, CalibrationDisplay >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = LogisticRegression(random_state=0) >>> clf.fit(X_train, y_train) LogisticRegression(random_state=0) >>> y_prob = clf.predict_proba(X_test)[:, 1] >>> prob_true, prob_pred = calibration_curve(y_test, y_prob, n_bins=10) >>> disp = CalibrationDisplay(prob_true, prob_pred, y_prob) >>> disp.plot() <...>
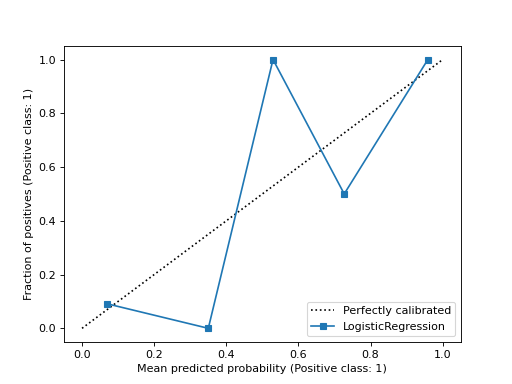
- classmethod from_estimator(estimator, X, y, *, n_bins=5, strategy='uniform', pos_label=None, name=None, ax=None, ref_line=True, **kwargs)[Quelle]#
Zeichnet die Kalibrierungskurve mithilfe eines binären Klassifikators und Daten.
Eine Kalibrierungskurve, auch bekannt als Zuverlässigkeitsdiagramm, verwendet Eingaben von einem binären Klassifikator und zeichnet die durchschnittliche vorhergesagte Wahrscheinlichkeit für jeden Bin gegen den Anteil positiver Klassen auf der y-Achse.
Zusätzliche Schlüsselwortargumente werden an
matplotlib.pyplot.plotübergeben.Lesen Sie mehr über Kalibrierung im Benutzerhandbuch und mehr über die scikit-learn Visualisierungs-API unter Visualisierungen.
Hinzugefügt in Version 1.0.
- Parameter:
- estimatorSchätzer-Instanz
Trainierter Klassifikator oder eine trainierte
Pipeline, bei der der letzte Schätzer ein Klassifikator ist. Der Klassifikator muss über eine predict_proba-Methode verfügen.- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabewerte.
- yarray-like von Form (n_samples,)
Binäre Zielwerte.
- n_binsint, Standardwert=5
Anzahl der Bins, in die das Intervall [0, 1] zur Berechnung der Kalibrierungskurve diskretisiert wird. Eine größere Anzahl erfordert mehr Daten.
- strategy{‘uniform’, ‘quantile’}, Standardwert=’uniform’
Strategie zur Bestimmung der Breiten der Bins.
'uniform': Die Bins haben identische Breiten.'quantile': Die Bins haben die gleiche Anzahl von Stichproben und hängen von den vorhergesagten Wahrscheinlichkeiten ab.
- pos_labelint, float, bool oder str, Standardwert=None
Die positive Klasse bei der Berechnung der Kalibrierungskurve. Standardmäßig wird
estimators.classes_[1]als positive Klasse betrachtet.Hinzugefügt in Version 1.1.
- namestr, Standardwert=None
Name zur Beschriftung der Kurve. Wenn
None, wird der Name des Schätzers verwendet.- axmatplotlib axes, Standardwert=None
Axes-Objekt, auf dem geplottet werden soll. Wenn
None, wird eine neue Figur und Achse erstellt.- ref_linebool, Standardwert=True
Wenn
True, wird eine Referenzlinie gezeichnet, die einen perfekt kalibrierten Klassifikator darstellt.- **kwargsdict
Schlüsselwortargumente, die an
matplotlib.pyplot.plotübergeben werden.
- Gibt zurück:
- display
CalibrationDisplay. Objekt, das berechnete Werte speichert.
- display
Siehe auch
CalibrationDisplay.from_predictionsZeichnet die Kalibrierungskurve mithilfe von wahren und vorhergesagten Labels.
Beispiele
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.calibration import CalibrationDisplay >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = LogisticRegression(random_state=0) >>> clf.fit(X_train, y_train) LogisticRegression(random_state=0) >>> disp = CalibrationDisplay.from_estimator(clf, X_test, y_test) >>> plt.show()
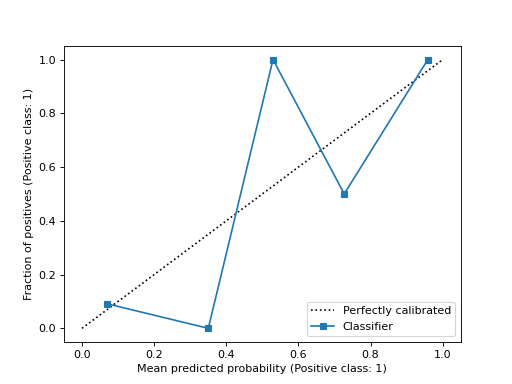
- classmethod from_predictions(y_true, y_prob, *, n_bins=5, strategy='uniform', pos_label=None, name=None, ax=None, ref_line=True, **kwargs)[Quelle]#
Zeichnet die Kalibrierungskurve mithilfe von wahren Labels und vorhergesagten Wahrscheinlichkeiten.
Kalibrierungskurve, auch bekannt als Zuverlässigkeitsdiagramm, verwendet Eingaben von einem binären Klassifikator und zeichnet die durchschnittliche vorhergesagte Wahrscheinlichkeit für jeden Bin gegen den Anteil positiver Klassen auf der y-Achse.
Zusätzliche Schlüsselwortargumente werden an
matplotlib.pyplot.plotübergeben.Lesen Sie mehr über Kalibrierung im Benutzerhandbuch und mehr über die scikit-learn Visualisierungs-API unter Visualisierungen.
Hinzugefügt in Version 1.0.
- Parameter:
- y_truearray-ähnlich mit Form (n_samples,)
Wahre Labels.
- y_probarray-like der Form (n_samples,)
Die vorhergesagten Wahrscheinlichkeiten der positiven Klasse.
- n_binsint, Standardwert=5
Anzahl der Bins, in die das Intervall [0, 1] zur Berechnung der Kalibrierungskurve diskretisiert wird. Eine größere Anzahl erfordert mehr Daten.
- strategy{‘uniform’, ‘quantile’}, Standardwert=’uniform’
Strategie zur Bestimmung der Breiten der Bins.
'uniform': Die Bins haben identische Breiten.'quantile': Die Bins haben die gleiche Anzahl von Stichproben und hängen von den vorhergesagten Wahrscheinlichkeiten ab.
- pos_labelint, float, bool oder str, Standardwert=None
Die positive Klasse bei der Berechnung der Kalibrierungskurve. Wenn
pos_label=Noneist, undy_truein {-1, 1} oder {0, 1} liegt, wirdpos_labelauf 1 gesetzt, andernfalls wird ein Fehler ausgelöst.Hinzugefügt in Version 1.1.
- namestr, Standardwert=None
Name zur Beschriftung der Kurve.
- axmatplotlib axes, Standardwert=None
Axes-Objekt, auf dem geplottet werden soll. Wenn
None, wird eine neue Figur und Achse erstellt.- ref_linebool, Standardwert=True
Wenn
True, wird eine Referenzlinie gezeichnet, die einen perfekt kalibrierten Klassifikator darstellt.- **kwargsdict
Schlüsselwortargumente, die an
matplotlib.pyplot.plotübergeben werden.
- Gibt zurück:
- display
CalibrationDisplay. Objekt, das berechnete Werte speichert.
- display
Siehe auch
CalibrationDisplay.from_estimatorZeichnet die Kalibrierungskurve mithilfe eines Schätzers und Daten.
Beispiele
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.calibration import CalibrationDisplay >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = LogisticRegression(random_state=0) >>> clf.fit(X_train, y_train) LogisticRegression(random_state=0) >>> y_prob = clf.predict_proba(X_test)[:, 1] >>> disp = CalibrationDisplay.from_predictions(y_test, y_prob) >>> plt.show()
- plot(*, ax=None, name=None, ref_line=True, **kwargs)[Quelle]#
Visualisierung plotten.
Zusätzliche Schlüsselwortargumente werden an
matplotlib.pyplot.plotübergeben.- Parameter:
- axMatplotlib Axes, Standardwert=None
Axes-Objekt, auf dem geplottet werden soll. Wenn
None, wird eine neue Figur und Achse erstellt.- namestr, Standardwert=None
Name zur Beschriftung der Kurve. Wenn
None, wirdestimator_nameverwendet, falls dieser nichtNoneist, ansonsten wird keine Beschriftung angezeigt.- ref_linebool, Standardwert=True
Wenn
True, wird eine Referenzlinie gezeichnet, die einen perfekt kalibrierten Klassifikator darstellt.- **kwargsdict
Schlüsselwortargumente, die an
matplotlib.pyplot.plotübergeben werden.
- Gibt zurück:
- display
CalibrationDisplay Objekt, das berechnete Werte speichert.
- display