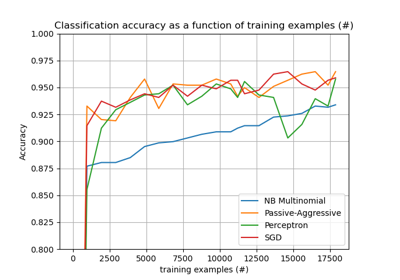
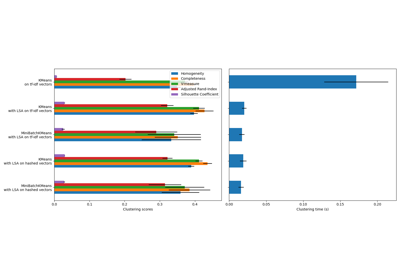
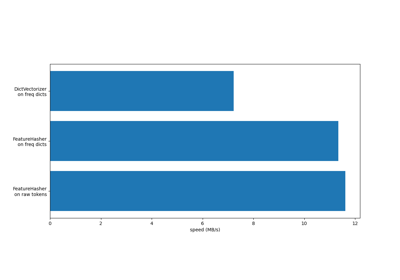
HashingVectorizer#
- class sklearn.feature_extraction.text.HashingVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), analyzer='word', n_features=1048576, binary=False, norm='l2', alternate_sign=True, dtype=<class 'numpy.float64'>)[Quelle]#
Konvertiert eine Sammlung von Textdokumenten in eine Matrix von Token-Vorkommen.
Wandelt eine Sammlung von Textdokumenten in eine scipy.sparse Matrix um, die Token-Vorkommenszählungen (oder binäre Vorkommensinformationen) enthält, möglicherweise normalisiert als Token-Häufigkeiten, wenn norm=’l1’, oder projiziert auf die euklidische Einheitssphäre, wenn norm=’l2’.
Diese Text-Vektorisierungs-Implementierung verwendet den Hashing-Trick, um die Abbildung von Token-String-Namen zu ganzzahligen Feature-Indizes zu finden.
Diese Strategie hat mehrere Vorteile
Sie ist sehr speichereffizient und skalierbar für große Datensätze, da kein Vokabulardictionary im Speicher gespeichert werden muss.
Sie ist schnell zu pickeln und zu entpickeln, da sie außer den Konstruktorparametern keinen Zustand speichert.
Sie kann in einer Streaming- (partial fit) oder parallelen Pipeline verwendet werden, da während des Fits kein Zustand berechnet wird.
Es gibt auch ein paar Nachteile (im Vergleich zur Verwendung eines CountVectorizer mit einem In-Memory-Vokabular)
Es gibt keine Möglichkeit, die inverse Transformation (von Feature-Indizes zu String-Feature-Namen) zu berechnen, was ein Problem darstellen kann, wenn man versuchen will zu introspektieren, welche Features für ein Modell am wichtigsten sind.
Es kann zu Kollisionen kommen: Unterschiedliche Tokens können auf denselben Feature-Index abgebildet werden. In der Praxis ist dies jedoch selten ein Problem, wenn n_features groß genug ist (z. B. 2 ** 18 für Textklassifikationsprobleme).
Keine IDF-Gewichtung, da dies den Transformer zustandsbehaftet machen würde.
Die verwendete Hash-Funktion ist die 32-Bit-Version von Murmurhash3 mit Vorzeichen.
Für einen Effizienzvergleich der verschiedenen Merkmalsextraktoren siehe Vergleich von HashingVectorizer und DictVectorizer.
Ein Beispiel für Dokumenten-Clustering und ein Vergleich mit
TfidfVectorizerfinden Sie unter Clustering text documents using k-means.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- input{‘filename’, ‘file’, ‘content’}, standardmäßig=’content’
Wenn
'filename', wird erwartet, dass die als Argument an fit übergebene Sequenz eine Liste von Dateinamen ist, die gelesen werden müssen, um den zu analysierenden Rohinhalt abzurufen.Wenn
'file', müssen die Sequenzelemente eine „read“-Methode (dateiähnliches Objekt) haben, die aufgerufen wird, um die Bytes im Speicher abzurufen.Wenn
'content', wird erwartet, dass die Eingabe eine Sequenz von Elementen ist, die vom Typ String oder Byte sein können.
- encodingstr, standardmäßig=’utf-8’
Wenn Bytes oder Dateien zur Analyse übergeben werden, wird diese Kodierung zum Dekodieren verwendet.
- decode_error{‘strict’, ‘ignore’, ‘replace’}, standardmäßig=’strict’
Anweisung, was zu tun ist, wenn eine Byte-Sequenz zur Analyse übergeben wird, die Zeichen enthält, die nicht zur gegebenen
encodinggehören. Standardmäßig ist dies „strict“, was bedeutet, dass ein UnicodeDecodeError ausgelöst wird. Andere Werte sind „ignore“ und „replace“.- strip_accents{‘ascii’, ‘unicode’} oder aufrufbar, standardmäßig=None
Akzente entfernen und andere Zeichennormalisierungen während des Vorverarbeitungsschritts durchführen. 'ascii' ist eine schnelle Methode, die nur auf Zeichen angewendet wird, die eine direkte ASCII-Entsprechung haben. 'unicode' ist eine etwas langsamere Methode, die auf beliebige Zeichen angewendet wird. None (Standard) bedeutet, dass keine Zeichennormalisierung durchgeführt wird.
Sowohl „ascii“ als auch „unicode“ verwenden die NFKD-Normalisierung von
unicodedata.normalize.- lowercasebool, standardmäßig=True
Konvertiert alle Zeichen vor der Tokenisierung in Kleinbuchstaben.
- preprocessoraufrufbar, standardmäßig=None
Überschreiben Sie die Vorverarbeitung (String-Transformation), während die Tokenisierung und die Erzeugung von N-Grammen beibehalten werden. Gilt nur, wenn
analyzernicht aufrufbar ist.- tokenizeraufrufbar, standardmäßig=None
Überschreibt den Zeichenketten-Tokenisierungsschritt unter Beibehaltung der Schritte für Vorverarbeitung und N-Gramm-Generierung. Gilt nur, wenn
analyzer == 'word'.- stop_words{‘english’}, list, standardmäßig=None
Wenn 'english', wird eine integrierte Stoppwortliste für Englisch verwendet. Es gibt mehrere bekannte Probleme mit 'english', und Sie sollten eine Alternative in Betracht ziehen (siehe Verwendung von Stoppwörtern).
Wenn eine Liste, wird angenommen, dass diese Liste Stoppwörter enthält, die alle aus den resultierenden Tokens entfernt werden. Gilt nur, wenn
analyzer == 'word'.- token_patternstr oder None, Standard=r”(?u)\b\w\w+\b”
Regulärer Ausdruck, der festlegt, was ein „Token“ ausmacht, nur verwendet, wenn
analyzer == 'word'. Der Standard-Reguläre Ausdruck wählt Tokens mit 2 oder mehr alphanumerischen Zeichen aus (Satzzeichen werden vollständig ignoriert und immer als Trennzeichen für Tokens behandelt).Wenn es eine Erfassungsgruppe im token_pattern gibt, dann wird der Inhalt der erfassten Gruppe und nicht der gesamte Treffer zum Token. Es ist höchstens eine Erfassungsgruppe zulässig.
- ngram_rangeTupel (min_n, max_n), standardmäßig=(1, 1)
Die untere und obere Grenze des Bereichs von n-Werten für verschiedene zu extrahierende n-Gramme. Alle Werte von n, so dass min_n <= n <= max_n, werden verwendet. Zum Beispiel bedeutet ein
ngram_rangevon(1, 1)nur Unigramme,(1, 2)Unigramme und Bigramme, und(2, 2)nur Bigramme. Gilt nur, wennanalyzernicht aufrufbar ist.- analyzer{‘word’, ‘char’, ‘char_wb’} oder aufrufbar, standardmäßig=’word’
Ob das Feature aus Wort- oder Zeichen-N-Grammen gebildet werden soll. Die Option 'char_wb' erstellt Zeichen-N-Gramme nur aus Text innerhalb von Wortgrenzen; N-Gramme an den Rändern von Wörtern werden mit Leerzeichen aufgefüllt.
Wenn ein Aufrufbares übergeben wird, wird es verwendet, um die Sequenz von Merkmalen aus den rohen, unverarbeiteten Eingaben zu extrahieren.
Geändert in Version 0.21: Seit v0.21 werden, wenn
input'filename'oder'file'ist, die Daten zuerst aus der Datei gelesen und dann an den gegebenen aufrufbaren Analyzer übergeben.- n_featuresint, Standard=(2 ** 20)
Die Anzahl der Features (Spalten) in den Ausgabematrizen. Kleine Feature-Anzahlen führen wahrscheinlich zu Hash-Kollisionen, aber große Anzahlen führen zu größeren Koeffizienten-Dimensionen in linearen Lernmodellen.
- binarybool, standardmäßig=False
Wenn True, werden alle nicht-Null-Zählungen auf 1 gesetzt. Dies ist nützlich für diskrete Wahrscheinlichkeitsmodelle, die binäre Ereignisse und nicht ganzzahlige Zählungen modellieren.
- norm{‘l1’, ‘l2’}, Standard=’l2’
Norm, die zur Normalisierung von Termvektoren verwendet wird. None für keine Normalisierung.
- alternate_signbool, Standard=True
Wenn True, wird ein alternierendes Vorzeichen zu den Features hinzugefügt, um das Skalarprodukt im gehashten Raum auch bei kleinen n_features annähernd zu erhalten. Dieser Ansatz ähnelt der Sparse Random Projection.
Hinzugefügt in Version 0.19.
- dtypetype, Standard=np.float64
Typ der von fit_transform() oder transform() zurückgegebenen Matrix.
Siehe auch
CountVectorizerKonvertiert eine Sammlung von Textdokumenten in eine Matrix von Token-Zählungen.
TfidfVectorizerKonvertiert eine Sammlung von Rohdokumenten in eine Matrix von TF-IDF-Merkmalen.
Anmerkungen
Dieser Estimator ist zustandslos und muss nicht gefittet werden. Wir empfehlen jedoch,
fit_transformanstelle vontransformaufzurufen, da die Parameterprüfung nur infitdurchgeführt wird.Beispiele
>>> from sklearn.feature_extraction.text import HashingVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = HashingVectorizer(n_features=2**4) >>> X = vectorizer.fit_transform(corpus) >>> print(X.shape) (4, 16)
- build_analyzer()[Quelle]#
Gibt eine aufrufbare Funktion zurück, um Eingabedaten zu verarbeiten.
Die aufrufbare Funktion kümmert sich um Vorverarbeitung, Tokenisierung und N-Gramm-Generierung.
- Gibt zurück:
- analyzer: callable
Eine Funktion zur Verarbeitung von Vorverarbeitung, Tokenisierung und N-Gramm-Generierung.
- build_preprocessor()[Quelle]#
Gibt eine Funktion zurück, die den Text vor der Tokenisierung vorverarbeitet.
- Gibt zurück:
- preprocessor: callable
Eine Funktion, die den Text vor der Tokenisierung vorverarbeitet.
- build_tokenizer()[Quelle]#
Gibt eine Funktion zurück, die einen String in eine Sequenz von Tokens aufteilt.
- Gibt zurück:
- tokenizer: callable
Eine Funktion, die einen String in eine Sequenz von Tokens aufteilt.
- decode(doc)[Quelle]#
Dekodiert die Eingabe in einen String aus Unicode-Symbolen.
Die Dekodierungsstrategie hängt von den Parametern des Vektorisierers ab.
- Parameter:
- docbytes oder str
Der zu dekodierende String.
- Gibt zurück:
- doc: str
Ein String aus Unicode-Symbolen.
- fit(X, y=None)[Quelle]#
Validiert nur die Parameter des Estimators.
Diese Methode erlaubt: (i) die Validierung der Parameter des Estimators und (ii) Konsistenz mit der scikit-learn Transformer API.
- Parameter:
- Xndarray der Form [n_samples, n_features]
Trainingsdaten.
- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- Gibt zurück:
- selfobject
HashingVectorizer-Instanz.
- fit_transform(X, y=None)[Quelle]#
Transformiert eine Sequenz von Dokumenten in eine Dokument-Term-Matrix.
- Parameter:
- Xiterierbar über Roh-Textdokumente, Länge = n_samples
Stichproben. Jede Stichprobe muss ein Textdokument sein (entweder Bytes oder Unicode-Zeichenketten, Dateiname oder Dateiobjekt, je nach Konstruktorargument), das tokenisiert und gehasht wird.
- yany
Ignoriert. Dieser Parameter existiert nur zur Kompatibilität mit sklearn.pipeline.Pipeline.
- Gibt zurück:
- Xspärliche Matrix der Form (n_samples, n_features)
Dokument-Term-Matrix.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- get_stop_words()[Quelle]#
Erstellt oder ruft die effektive Stoppwortliste ab.
- Gibt zurück:
- stop_words: list oder None
Eine Liste von Stoppwörtern.
- partial_fit(X, y=None)[Quelle]#
Validiert nur die Parameter des Estimators.
Diese Methode erlaubt: (i) die Validierung der Parameter des Estimators und (ii) Konsistenz mit der scikit-learn Transformer API.
- Parameter:
- Xndarray der Form [n_samples, n_features]
Trainingsdaten.
- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- Gibt zurück:
- selfobject
HashingVectorizer-Instanz.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(X)[Quelle]#
Transformiert eine Sequenz von Dokumenten in eine Dokument-Term-Matrix.
- Parameter:
- Xiterierbar über Roh-Textdokumente, Länge = n_samples
Stichproben. Jede Stichprobe muss ein Textdokument sein (entweder Bytes oder Unicode-Zeichenketten, Dateiname oder Dateiobjekt, je nach Konstruktorargument), das tokenisiert und gehasht wird.
- Gibt zurück:
- Xspärliche Matrix der Form (n_samples, n_features)
Dokument-Term-Matrix.