Hinweis
Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Vergleich von FeatureHasher und DictVectorizer#
In diesem Beispiel veranschaulichen wir die Textvektorisierung, den Prozess der Darstellung nicht-numerischer Eingabedaten (wie z.B. Dictionaries oder Textdokumente) als Vektoren reeller Zahlen.
Wir vergleichen zunächst FeatureHasher und DictVectorizer, indem wir beide Methoden verwenden, um Textdokumente zu vektorisieren, die mit Hilfe einer benutzerdefinierten Python-Funktion vorverarbeitet (tokenisiert) wurden.
Später stellen wir die textspezifischen Vektorisierer HashingVectorizer, CountVectorizer und TfidfVectorizer vor und analysieren sie, die sowohl die Tokenisierung als auch die Zusammenstellung der Merkmalsmatrix innerhalb einer einzigen Klasse handhaben.
Ziel des Beispiels ist es, die Verwendung der Textvektorisierungs-API zu demonstrieren und ihre Verarbeitungszeit zu vergleichen. Sehen Sie sich die Beispielskripte Klassifizierung von Textdokumenten mithilfe spärlicher Merkmale und Clustering von Textdokumenten mit k-means für tatsächliches Lernen an Textdokumenten an.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Daten laden#
Wir laden Daten aus Dem 20 Nachrichten-Textdatensatz, der rund 18.000 Nachrichtenbeiträge zu 20 Themen umfasst, aufgeteilt in zwei Teilmengen: eine zum Trainieren und eine zum Testen. Der Einfachheit halber und zur Reduzierung des Rechenaufwands wählen wir eine Teilmenge von 7 Themen und verwenden nur den Trainingssatz.
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"comp.graphics",
"comp.sys.ibm.pc.hardware",
"misc.forsale",
"rec.autos",
"sci.space",
"talk.religion.misc",
]
print("Loading 20 newsgroups training data")
raw_data, _ = fetch_20newsgroups(subset="train", categories=categories, return_X_y=True)
data_size_mb = sum(len(s.encode("utf-8")) for s in raw_data) / 1e6
print(f"{len(raw_data)} documents - {data_size_mb:.3f}MB")
Loading 20 newsgroups training data
3803 documents - 6.245MB
Definition von Vorverarbeitungsfunktionen#
Ein Token kann ein Wort, ein Teil eines Wortes oder alles sein, was zwischen Leerzeichen oder Symbolen in einer Zeichenkette liegt. Hier definieren wir eine Funktion, die die Token mithilfe eines einfachen regulären Ausdrucks (Regex) extrahiert, der Unicode-Wortzeichen abgleicht. Dies umfasst die meisten Zeichen, die Teil eines Wortes in jeder Sprache sein können, sowie Zahlen und den Unterstrich
import re
def tokenize(doc):
"""Extract tokens from doc.
This uses a simple regex that matches word characters to break strings
into tokens. For a more principled approach, see CountVectorizer or
TfidfVectorizer.
"""
return (tok.lower() for tok in re.findall(r"\w+", doc))
list(tokenize("This is a simple example, isn't it?"))
['this', 'is', 'a', 'simple', 'example', 'isn', 't', 'it']
Wir definieren eine zusätzliche Funktion, die die Häufigkeit des Vorkommens jedes Tokens in einem gegebenen Dokument zählt. Sie gibt ein Häufigkeitsdictionary zurück, das von den Vektorisierern verwendet werden kann.
from collections import defaultdict
def token_freqs(doc):
"""Extract a dict mapping tokens from doc to their occurrences."""
freq = defaultdict(int)
for tok in tokenize(doc):
freq[tok] += 1
return freq
token_freqs("That is one example, but this is another one")
defaultdict(<class 'int'>, {'that': 1, 'is': 2, 'one': 2, 'example': 1, 'but': 1, 'this': 1, 'another': 1})
Beachten Sie insbesondere, dass das wiederholte Token "is" beispielsweise zweimal gezählt wird.
Das Aufteilen eines Textdokuments in Wort-Token, wobei die Reihenfolgeinformation zwischen den Wörtern in einem Satz möglicherweise verloren geht, wird oft als Bag of Words-Darstellung bezeichnet.
DictVectorizer#
Zuerst benchmarken wir den DictVectorizer und vergleichen ihn dann mit FeatureHasher, da beide Dictionaries als Eingabe erhalten.
from time import time
from sklearn.feature_extraction import DictVectorizer
dict_count_vectorizers = defaultdict(list)
t0 = time()
vectorizer = DictVectorizer()
vectorizer.fit_transform(token_freqs(d) for d in raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(
vectorizer.__class__.__name__ + "\non freq dicts"
)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {len(vectorizer.get_feature_names_out())} unique terms")
done in 0.865 s at 7.2 MB/s
Found 47928 unique terms
Die tatsächliche Zuordnung von Text-Token zu Spaltenindex wird explizit im Attribut .vocabulary_ gespeichert, einem potenziell sehr großen Python-Dictionary
type(vectorizer.vocabulary_)
len(vectorizer.vocabulary_)
47928
vectorizer.vocabulary_["example"]
19145
FeatureHasher#
Dictionaries nehmen viel Speicherplatz ein und wachsen mit dem Trainingsdatensatz. Anstatt die Vektoren zusammen mit einem Dictionary wachsen zu lassen, erstellt Feature Hashing einen Vektor vordefinierter Länge, indem eine Hash-Funktion h auf die Merkmale (z.B. Token) angewendet wird, und verwendet dann die Hash-Werte direkt als Merkmalsindizes und aktualisiert den resultierenden Vektor an diesen Indizes. Wenn der Merkmalsraum nicht groß genug ist, neigen Hash-Funktionen dazu, unterschiedliche Werte auf denselben Hash-Code abzubilden (Hash-Kollisionen). Infolgedessen ist es unmöglich festzustellen, welches Objekt einen bestimmten Hash-Code erzeugt hat.
Aufgrund des Obigen ist es unmöglich, die ursprünglichen Token aus der Merkmalsmatrix wiederherzustellen, und der beste Ansatz zur Schätzung der Anzahl eindeutiger Begriffe im ursprünglichen Dictionary ist die Zählung der Anzahl aktiver Spalten in der kodierten Merkmalsmatrix. Zu diesem Zweck definieren wir die folgende Funktion
import numpy as np
def n_nonzero_columns(X):
"""Number of columns with at least one non-zero value in a CSR matrix.
This is useful to count the number of features columns that are effectively
active when using the FeatureHasher.
"""
return len(np.unique(X.nonzero()[1]))
Die Standardanzahl von Merkmalen für den FeatureHasher beträgt 2**20. Hier setzen wir n_features = 2**18, um Hash-Kollisionen zu veranschaulichen.
FeatureHasher auf Häufigkeits-Dictionaries
from sklearn.feature_extraction import FeatureHasher
t0 = time()
hasher = FeatureHasher(n_features=2**18)
X = hasher.transform(token_freqs(d) for d in raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(
hasher.__class__.__name__ + "\non freq dicts"
)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {n_nonzero_columns(X)} unique tokens")
done in 0.550 s at 11.3 MB/s
Found 43873 unique tokens
Die Anzahl der eindeutigen Token bei Verwendung des FeatureHasher ist niedriger als die, die mit dem DictVectorizer erhalten wurden. Dies liegt an Hash-Kollisionen.
Die Anzahl der Kollisionen kann durch Vergrößerung des Merkmalsraums reduziert werden. Beachten Sie, dass sich die Geschwindigkeit des Vektorisierers bei einer großen Anzahl von Merkmalen nicht wesentlich ändert, obwohl dies zu größeren Koeffizientendimensionen führt und dann mehr Speicherplatz zur Speicherung erfordert, selbst wenn ein Großteil davon inaktiv ist.
t0 = time()
hasher = FeatureHasher(n_features=2**22)
X = hasher.transform(token_freqs(d) for d in raw_data)
duration = time() - t0
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {n_nonzero_columns(X)} unique tokens")
done in 0.550 s at 11.3 MB/s
Found 47668 unique tokens
Wir bestätigen, dass die Anzahl der eindeutigen Token näher an die Anzahl der eindeutigen Begriffe herankommt, die vom DictVectorizer gefunden wurde.
FeatureHasher auf Roh-Token
Alternativ kann man input_type="string" im FeatureHasher setzen, um die Strings direkt aus der benutzerdefinierten tokenize Funktion zu vektorisieren. Dies ist gleichbedeutend mit der Übergabe eines Dictionaries mit einer impliziten Häufigkeit von 1 für jeden Merkmalsnamen.
t0 = time()
hasher = FeatureHasher(n_features=2**18, input_type="string")
X = hasher.transform(tokenize(d) for d in raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(
hasher.__class__.__name__ + "\non raw tokens"
)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {n_nonzero_columns(X)} unique tokens")
done in 0.538 s at 11.6 MB/s
Found 43873 unique tokens
Wir plotten nun die Geschwindigkeit der obigen Methoden zur Vektorisierung.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 6))
y_pos = np.arange(len(dict_count_vectorizers["vectorizer"]))
ax.barh(y_pos, dict_count_vectorizers["speed"], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels(dict_count_vectorizers["vectorizer"])
ax.invert_yaxis()
_ = ax.set_xlabel("speed (MB/s)")
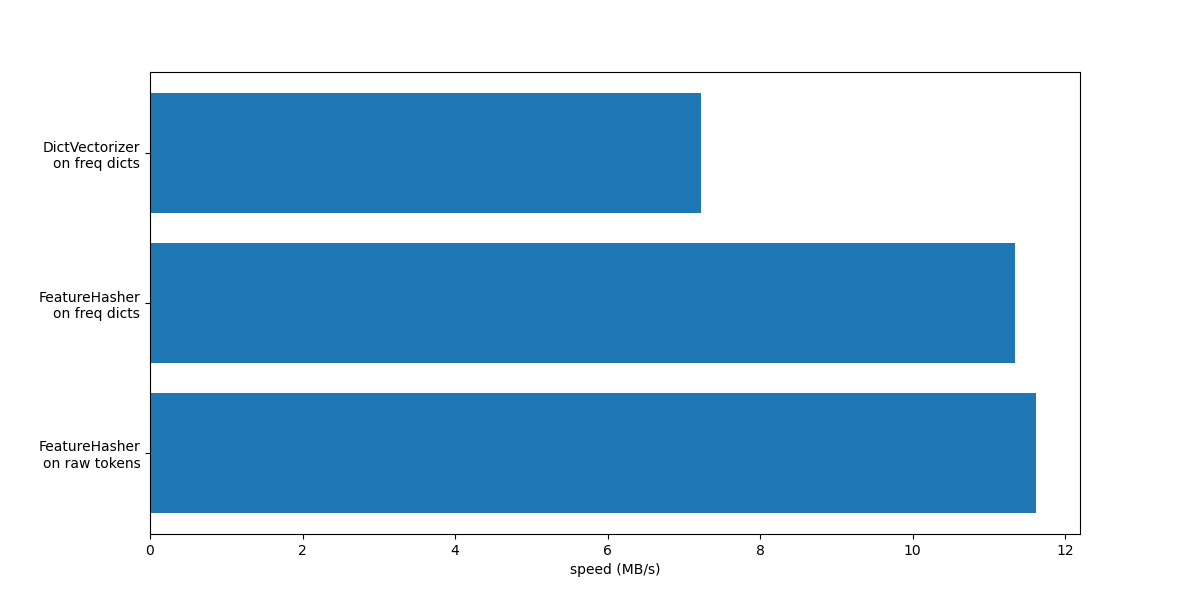
In beiden Fällen ist FeatureHasher etwa doppelt so schnell wie DictVectorizer. Das ist praktisch, wenn man mit großen Datenmengen arbeitet, mit dem Nachteil, dass die Invertierbarkeit der Transformation verloren geht, was wiederum die Interpretation eines Modells zu einer komplexeren Aufgabe macht.
Der FeatureHeasher mit input_type="string" ist geringfügig schneller als die Variante, die auf Häufigkeits-Dictionaries arbeitet, da er keine wiederholten Token zählt: Jedes Token wird implizit einmal gezählt, auch wenn es wiederholt wurde. Je nach nachgelagerter Machine-Learning-Aufgabe kann dies eine Einschränkung sein oder auch nicht.
Vergleich mit spezialisierten Textvektorisierern#
CountVectorizer akzeptiert Rohdaten, da er intern Tokenisierung und Häufigkeitszählung implementiert. Er ist dem DictVectorizer ähnlich, wenn er zusammen mit der benutzerdefinierten Funktion token_freqs verwendet wird, wie im vorherigen Abschnitt geschehen. Der Unterschied besteht darin, dass CountVectorizer flexibler ist. Insbesondere akzeptiert er verschiedene Regex-Muster über den Parameter token_pattern.
from sklearn.feature_extraction.text import CountVectorizer
t0 = time()
vectorizer = CountVectorizer()
vectorizer.fit_transform(raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(vectorizer.__class__.__name__)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {len(vectorizer.get_feature_names_out())} unique terms")
done in 0.570 s at 11.0 MB/s
Found 47885 unique terms
Wir sehen, dass die Implementierung von CountVectorizer etwa doppelt so schnell ist wie die Verwendung von DictVectorizer zusammen mit der einfachen Funktion, die wir zur Abbildung der Token definiert haben. Der Grund dafür ist, dass CountVectorizer durch Wiederverwendung eines kompilierten regulären Ausdrucks für den gesamten Trainingsdatensatz optimiert wird, anstatt einen pro Dokument zu erstellen, wie es in unserer naiven Tokenize-Funktion der Fall ist.
Nun führen wir ein ähnliches Experiment mit HashingVectorizer durch, was der Kombination des von der Klasse FeatureHasher implementierten "Hashing-Tricks" und der Textvorverarbeitung und Tokenisierung von CountVectorizer entspricht.
from sklearn.feature_extraction.text import HashingVectorizer
t0 = time()
vectorizer = HashingVectorizer(n_features=2**18)
vectorizer.fit_transform(raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(vectorizer.__class__.__name__)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
done in 0.476 s at 13.1 MB/s
Wir können beobachten, dass dies die bisher schnellste Text-Tokenisierungsstrategie ist, vorausgesetzt, die nachgelagerte Machine-Learning-Aufgabe kann einige Kollisionen tolerieren.
TfidfVectorizer#
In einem großen Textkorpus treten einige Wörter mit höherer Frequenz auf (z.B. "the", "a", "is" im Englischen) und tragen keine aussagekräftigen Informationen über den tatsächlichen Inhalt eines Dokuments. Wenn wir die Wortzähldaten direkt an einen Klassifikator übergeben würden, würden diese sehr häufigen Begriffe die Frequenzen seltenerer, aber informativerer Begriffe überschatten. Um die Zählmerkmale in Gleitkommadaten umzugewichten, die für die Verwendung durch einen Klassifikator geeignet sind, wird sehr häufig die TF-IDF-Transformation verwendet, wie sie vom TfidfTransformer implementiert wird. TF steht für "Term-Frequency" (Term-Häufigkeit), während "tf-idf" Term-Frequency mal Inverse Document-Frequency bedeutet.
Wir benchmarken nun den TfidfVectorizer, der der Kombination der Tokenisierung und Häufigkeitszählung von CountVectorizer mit der Normalisierung und Gewichtung von TfidfTransformer entspricht.
from sklearn.feature_extraction.text import TfidfVectorizer
t0 = time()
vectorizer = TfidfVectorizer()
vectorizer.fit_transform(raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(vectorizer.__class__.__name__)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {len(vectorizer.get_feature_names_out())} unique terms")
done in 0.572 s at 10.9 MB/s
Found 47885 unique terms
Zusammenfassung#
Fassen wir dieses Notebook zusammen, indem wir alle aufgezeichneten Verarbeitungsgeschwindigkeiten in einem einzigen Plot zusammenfassen
fig, ax = plt.subplots(figsize=(12, 6))
y_pos = np.arange(len(dict_count_vectorizers["vectorizer"]))
ax.barh(y_pos, dict_count_vectorizers["speed"], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels(dict_count_vectorizers["vectorizer"])
ax.invert_yaxis()
_ = ax.set_xlabel("speed (MB/s)")
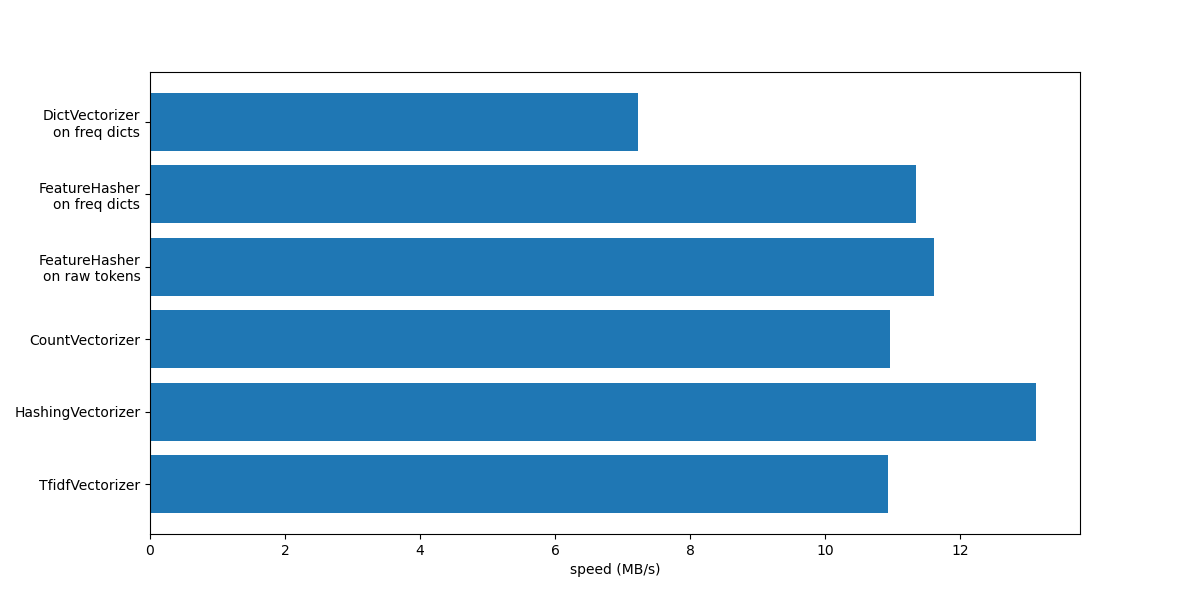
Beachten Sie aus dem Plot, dass TfidfVectorizer etwas langsamer ist als CountVectorizer aufgrund des zusätzlichen Vorgangs, der durch TfidfTransformer verursacht wird.
Beachten Sie auch, dass der HashingVectorizer bei Einstellung von n_features = 2**18 besser abschneidet als CountVectorizer, auf Kosten der Invertierbarkeit der Transformation aufgrund von Hash-Kollisionen.
Wir heben hervor, dass CountVectorizer und HashingVectorizer besser abschneiden als ihre entsprechenden DictVectorizer und FeatureHasher bei manuell tokenisierten Dokumenten, da der interne Tokenisierungsschritt der ersteren Vektorisierer einen regulären Ausdruck einmal kompiliert und ihn dann für alle Dokumente wiederverwendet.
Gesamtlaufzeit des Skripts: (0 Minuten 4.607 Sekunden)
Verwandte Beispiele
Klassifikation von Textdokumenten mit spärlichen Merkmalen

Biclustering von Dokumenten mit dem Spectral Co-Clustering Algorithmus