Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Nearest Neighbors Regression#
Demonstration der Lösung eines Regressionsproblems mithilfe eines k-Nearest Neighbor und der Interpolation des Ziels unter Verwendung von sowohl Baryzentren als auch konstanten Gewichten.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Beispieldaten generieren#
Hier generieren wir einige Datenpunkte zur Schulung des Modells. Wir generieren auch Daten im gesamten Bereich der Trainingsdaten, um zu visualisieren, wie das Modell in diesem gesamten Bereich reagieren würde.
import matplotlib.pyplot as plt
import numpy as np
from sklearn import neighbors
rng = np.random.RandomState(0)
X_train = np.sort(5 * rng.rand(40, 1), axis=0)
X_test = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X_train).ravel()
# Add noise to targets
y[::5] += 1 * (0.5 - np.random.rand(8))
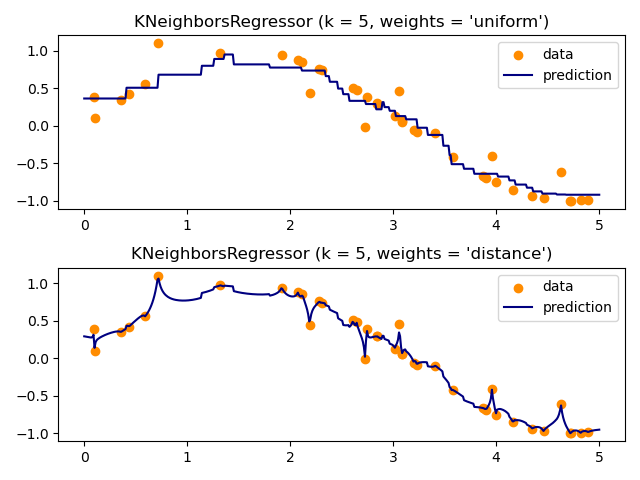
Regressionsmodell anpassen#
Hier schulen wir ein Modell und visualisieren, wie uniform und distance Gewichte bei der Vorhersage die vorhergesagten Werte beeinflussen.
n_neighbors = 5
for i, weights in enumerate(["uniform", "distance"]):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X_train, y).predict(X_test)
plt.subplot(2, 1, i + 1)
plt.scatter(X_train, y, color="darkorange", label="data")
plt.plot(X_test, y_, color="navy", label="prediction")
plt.axis("tight")
plt.legend()
plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors, weights))
plt.tight_layout()
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 0.173 Sekunden)
Verwandte Beispiele
Vergleich von Nächsten Nachbarn mit und ohne Neighborhood Components Analysis