Hinweis
Gehe zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Inkrementelle PCA#
Die inkrementelle Hauptkomponentenanalyse (IPCA) wird typischerweise als Ersatz für die Hauptkomponentenanalyse (PCA) verwendet, wenn der zu zerlegende Datensatz zu groß ist, um in den Speicher zu passen. IPCA erstellt eine niedrigrangige Approximation für die Eingabedaten unter Verwendung einer Speichermenge, die unabhängig von der Anzahl der Eingabedatensamples ist. Sie ist immer noch abhängig von den Merkmalen der Eingabedaten, aber die Änderung der Batch-Größe ermöglicht die Kontrolle des Speicherverbrauchs.
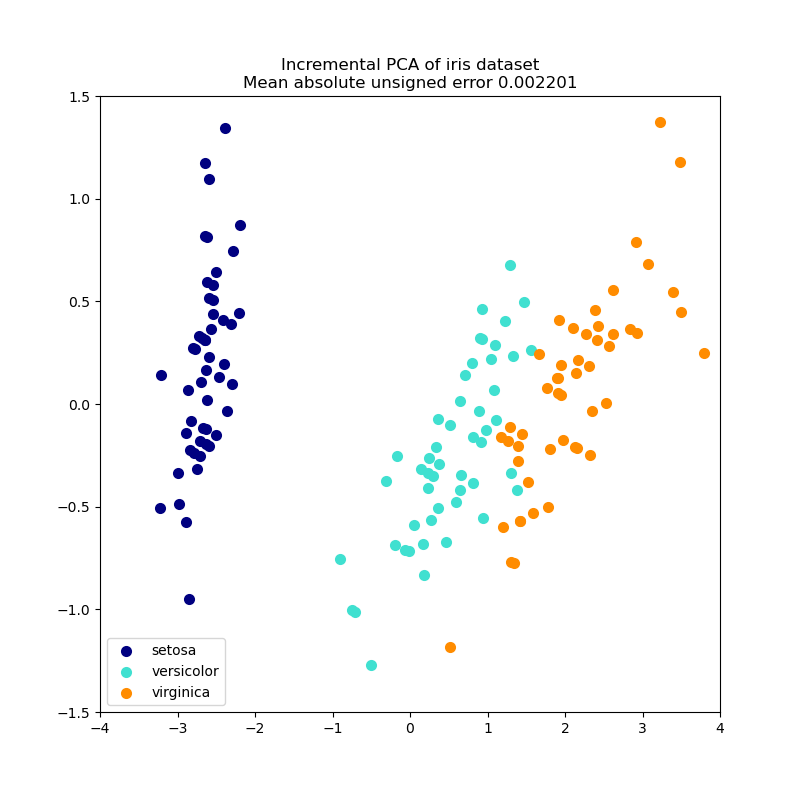
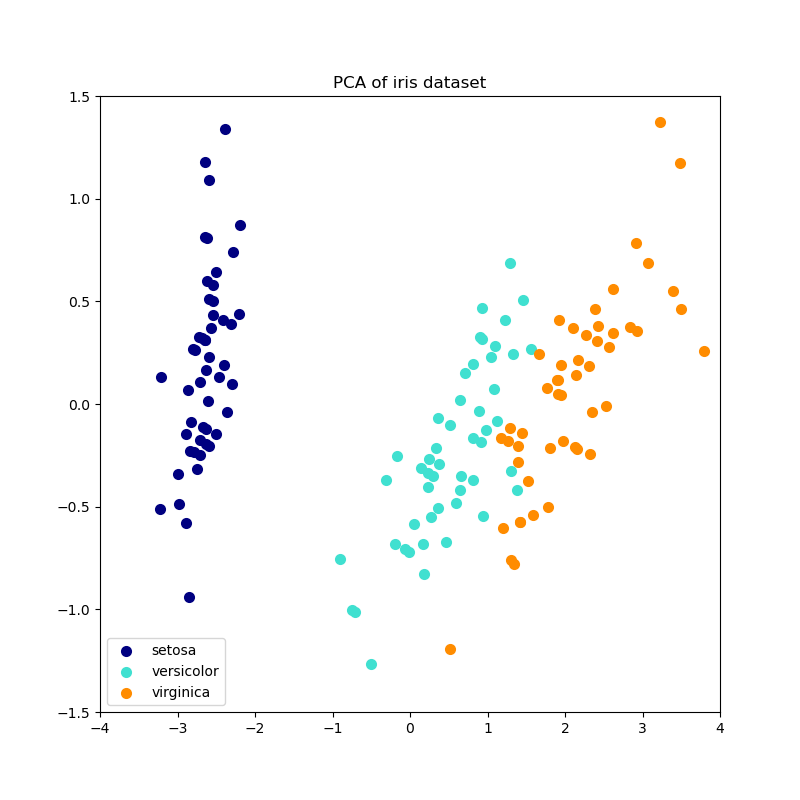
Dieses Beispiel dient als visueller Check, dass IPCA in der Lage ist, eine ähnliche Projektion der Daten wie PCA zu finden (bis auf eine Vorzeichenumkehr), während nur wenige Samples gleichzeitig verarbeitet werden. Dies kann als „Spielzeugbeispiel“ betrachtet werden, da IPCA für große Datensätze gedacht ist, die nicht in den Hauptspeicher passen und inkrementelle Ansätze erfordern.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA, IncrementalPCA
iris = load_iris()
X = iris.data
y = iris.target
n_components = 2
ipca = IncrementalPCA(n_components=n_components, batch_size=10)
X_ipca = ipca.fit_transform(X)
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
colors = ["navy", "turquoise", "darkorange"]
for X_transformed, title in [(X_ipca, "Incremental PCA"), (X_pca, "PCA")]:
plt.figure(figsize=(8, 8))
for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):
plt.scatter(
X_transformed[y == i, 0],
X_transformed[y == i, 1],
color=color,
lw=2,
label=target_name,
)
if "Incremental" in title:
err = np.abs(np.abs(X_pca) - np.abs(X_ipca)).mean()
plt.title(title + " of iris dataset\nMean absolute unsigned error %.6f" % err)
else:
plt.title(title + " of iris dataset")
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.axis([-4, 4, -1.5, 1.5])
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 0,199 Sekunden)
Verwandte Beispiele
Principal Component Analysis (PCA) auf dem Iris-Datensatz
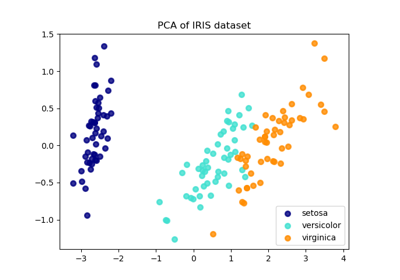
Vergleich von LDA und PCA 2D-Projektion des Iris-Datensatzes
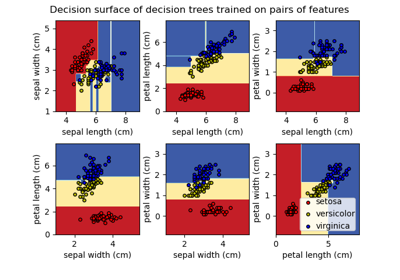
Entscheidungsfläche von Entscheidungsbäumen, trainiert auf dem Iris-Datensatz, plotten