Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Einzelne und Voting-Regressionsvorhersagen plotten#
Ein Voting Regressor ist ein Ensemble-Meta-Schätzer, der mehrere Basis-Regressoren anpasst, jeder auf dem gesamten Datensatz. Dann mittelt er die einzelnen Vorhersagen, um eine endgültige Vorhersage zu bilden. Wir werden drei verschiedene Regressoren verwenden, um die Daten vorherzusagen: GradientBoostingRegressor, RandomForestRegressor und LinearRegression. Dann werden die obigen 3 Regressoren für den VotingRegressor verwendet.
Schließlich plotten wir die von allen Modellen erstellten Vorhersagen zum Vergleich.
Wir arbeiten mit dem Diabetes-Datensatz, der aus 10 Merkmalen besteht, die von einer Kohorte von Diabetespatienten gesammelt wurden. Das Ziel ist ein quantitatives Maß für die Krankheitsfortschritt ein Jahr nach der Baseline.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.ensemble import (
GradientBoostingRegressor,
RandomForestRegressor,
VotingRegressor,
)
from sklearn.linear_model import LinearRegression
Klassifikatoren trainieren#
Zuerst laden wir den Diabetes-Datensatz und initialisieren einen Gradient Boosting Regressor, einen Random Forest Regressor und eine lineare Regression. Als nächstes verwenden wir die 3 Regressoren, um den Voting Regressor zu erstellen
X, y = load_diabetes(return_X_y=True)
# Train classifiers
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
reg1.fit(X, y)
reg2.fit(X, y)
reg3.fit(X, y)
ereg = VotingRegressor([("gb", reg1), ("rf", reg2), ("lr", reg3)])
ereg.fit(X, y)
VotingRegressor(estimators=[('gb', GradientBoostingRegressor(random_state=1)),
('rf', RandomForestRegressor(random_state=1)),
('lr', LinearRegression())])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
Parameter
Parameter
Vorhersagen treffen#
Nun verwenden wir jeden der Regressoren, um die ersten 20 Vorhersagen zu treffen.
xt = X[:20]
pred1 = reg1.predict(xt)
pred2 = reg2.predict(xt)
pred3 = reg3.predict(xt)
pred4 = ereg.predict(xt)
Ergebnisse plotten#
Schließlich visualisieren wir die 20 Vorhersagen. Die roten Sterne zeigen die durchschnittliche Vorhersage von VotingRegressor.
plt.figure()
plt.plot(pred1, "gd", label="GradientBoostingRegressor")
plt.plot(pred2, "b^", label="RandomForestRegressor")
plt.plot(pred3, "ys", label="LinearRegression")
plt.plot(pred4, "r*", ms=10, label="VotingRegressor")
plt.tick_params(axis="x", which="both", bottom=False, top=False, labelbottom=False)
plt.ylabel("predicted")
plt.xlabel("training samples")
plt.legend(loc="best")
plt.title("Regressor predictions and their average")
plt.show()

Gesamtlaufzeit des Skripts: (0 Minuten 0.801 Sekunden)
Verwandte Beispiele
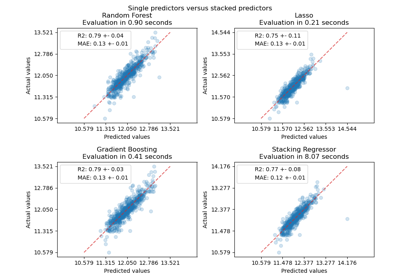
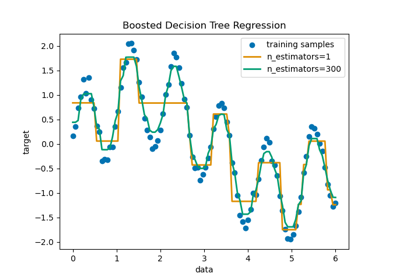
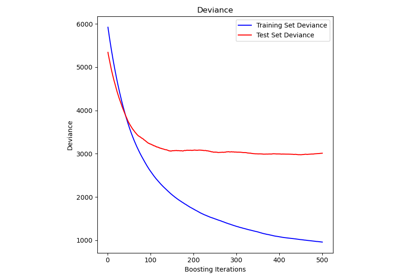
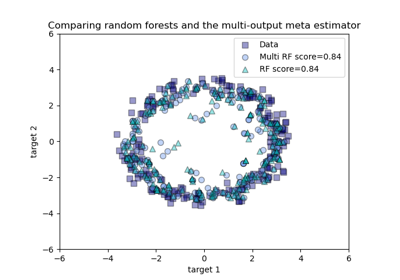
Vergleich von Random Forests und dem Multi-Output Meta-Estimator