Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Multilabel-Klassifizierung#
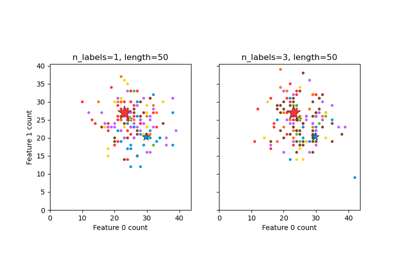
Dieses Beispiel simuliert ein Multilabel-Dokumentklassifizierungsproblem. Der Datensatz wird zufällig nach dem folgenden Prozess generiert:
Wählen Sie die Anzahl der Labels: n ~ Poisson(n_labels)
n Mal, wählen Sie eine Klasse c: c ~ Multinomial(theta)
Wählen Sie die Dokumentenlänge: k ~ Poisson(length)
k Mal, wählen Sie ein Wort: w ~ Multinomial(theta_c)
Im obigen Prozess wird Ablehnungsabtastung verwendet, um sicherzustellen, dass n größer als 2 ist und die Dokumentenlänge niemals null ist. Ebenso lehnen wir Klassen ab, die bereits ausgewählt wurden. Die Dokumente, denen beide Klassen zugeordnet sind, werden von zwei farbigen Kreisen umgeben dargestellt.
Die Klassifizierung wird durchgeführt, indem zur Veranschaulichung die ersten beiden durch PCA und CCA gefundenen Hauptkomponenten projiziert werden, gefolgt von der Verwendung der Metaklassifikatorin OneVsRestClassifier mit zwei SVCs mit linearen Kernels, um ein diskriminatives Modell für jede Klasse zu lernen. Beachten Sie, dass PCA zur Durchführung einer unüberwachten Dimensionsreduktion verwendet wird, während CCA zur Durchführung einer überwachten Dimensionsreduktion verwendet wird.
Hinweis: In der Darstellung bedeutet "unbeschriftete Stichproben" nicht, dass wir die Labels nicht kennen (wie beim semi-überwachten Lernen), sondern dass die Stichproben einfach kein Label haben.

# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cross_decomposition import CCA
from sklearn.datasets import make_multilabel_classification
from sklearn.decomposition import PCA
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
def plot_hyperplane(clf, min_x, max_x, linestyle, label):
# get the separating hyperplane
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(min_x - 5, max_x + 5) # make sure the line is long enough
yy = a * xx - (clf.intercept_[0]) / w[1]
plt.plot(xx, yy, linestyle, label=label)
def plot_subfigure(X, Y, subplot, title, transform):
if transform == "pca":
X = PCA(n_components=2).fit_transform(X)
elif transform == "cca":
X = CCA(n_components=2).fit(X, Y).transform(X)
else:
raise ValueError
min_x = np.min(X[:, 0])
max_x = np.max(X[:, 0])
min_y = np.min(X[:, 1])
max_y = np.max(X[:, 1])
classif = OneVsRestClassifier(SVC(kernel="linear"))
classif.fit(X, Y)
plt.subplot(2, 2, subplot)
plt.title(title)
zero_class = (Y[:, 0]).nonzero()
one_class = (Y[:, 1]).nonzero()
plt.scatter(X[:, 0], X[:, 1], s=40, c="gray", edgecolors=(0, 0, 0))
plt.scatter(
X[zero_class, 0],
X[zero_class, 1],
s=160,
edgecolors="b",
facecolors="none",
linewidths=2,
label="Class 1",
)
plt.scatter(
X[one_class, 0],
X[one_class, 1],
s=80,
edgecolors="orange",
facecolors="none",
linewidths=2,
label="Class 2",
)
plot_hyperplane(
classif.estimators_[0], min_x, max_x, "k--", "Boundary\nfor class 1"
)
plot_hyperplane(
classif.estimators_[1], min_x, max_x, "k-.", "Boundary\nfor class 2"
)
plt.xticks(())
plt.yticks(())
plt.xlim(min_x - 0.5 * max_x, max_x + 0.5 * max_x)
plt.ylim(min_y - 0.5 * max_y, max_y + 0.5 * max_y)
if subplot == 2:
plt.xlabel("First principal component")
plt.ylabel("Second principal component")
plt.legend(loc="upper left")
plt.figure(figsize=(8, 6))
X, Y = make_multilabel_classification(
n_classes=2, n_labels=1, allow_unlabeled=True, random_state=1
)
plot_subfigure(X, Y, 1, "With unlabeled samples + CCA", "cca")
plot_subfigure(X, Y, 2, "With unlabeled samples + PCA", "pca")
X, Y = make_multilabel_classification(
n_classes=2, n_labels=1, allow_unlabeled=False, random_state=1
)
plot_subfigure(X, Y, 3, "Without unlabeled samples + CCA", "cca")
plot_subfigure(X, Y, 4, "Without unlabeled samples + PCA", "pca")
plt.subplots_adjust(0.04, 0.02, 0.97, 0.94, 0.09, 0.2)
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 0,154 Sekunden)
Verwandte Beispiele
Semi-überwachte Klassifikation auf einem Textdatensatz