Fehlende Werte imputieren#
Beispiele zum Modul sklearn.impute.

Fehlende Werte imputieren, bevor ein Schätzer erstellt wird
Fehlende Werte imputieren, bevor ein Schätzer erstellt wird
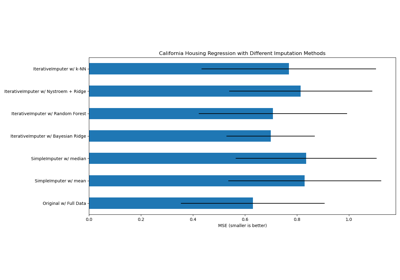
Fehlende Werte mit Varianten von IterativeImputer imputieren
Fehlende Werte mit Varianten von IterativeImputer imputieren