Hinweis
Zum Ende gehen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel in Ihrem Browser über JupyterLite oder Binder auszuführen.
Release Highlights für scikit-learn 1.1#
Wir freuen uns, die Veröffentlichung von scikit-learn 1.1 bekannt zu geben! Viele Fehlerbehebungen und Verbesserungen wurden hinzugefügt, sowie einige neue Schlüsselfunktionen. Nachfolgend werden einige der wichtigsten Funktionen dieser Veröffentlichung detailliert beschrieben. **Für eine vollständige Liste aller Änderungen** siehe die Release Notes.
Um die neueste Version zu installieren (mit pip)
pip install --upgrade scikit-learn
oder mit conda
conda install -c conda-forge scikit-learn
Quantilverlust in HistGradientBoostingRegressor#
HistGradientBoostingRegressor kann Quantile mit loss="quantile" und dem neuen Parameter quantile modellieren.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import HistGradientBoostingRegressor
# Simple regression function for X * cos(X)
rng = np.random.RandomState(42)
X_1d = np.linspace(0, 10, num=2000)
X = X_1d.reshape(-1, 1)
y = X_1d * np.cos(X_1d) + rng.normal(scale=X_1d / 3)
quantiles = [0.95, 0.5, 0.05]
parameters = dict(loss="quantile", max_bins=32, max_iter=50)
hist_quantiles = {
f"quantile={quantile:.2f}": HistGradientBoostingRegressor(
**parameters, quantile=quantile
).fit(X, y)
for quantile in quantiles
}
fig, ax = plt.subplots()
ax.plot(X_1d, y, "o", alpha=0.5, markersize=1)
for quantile, hist in hist_quantiles.items():
ax.plot(X_1d, hist.predict(X), label=quantile)
_ = ax.legend(loc="lower left")
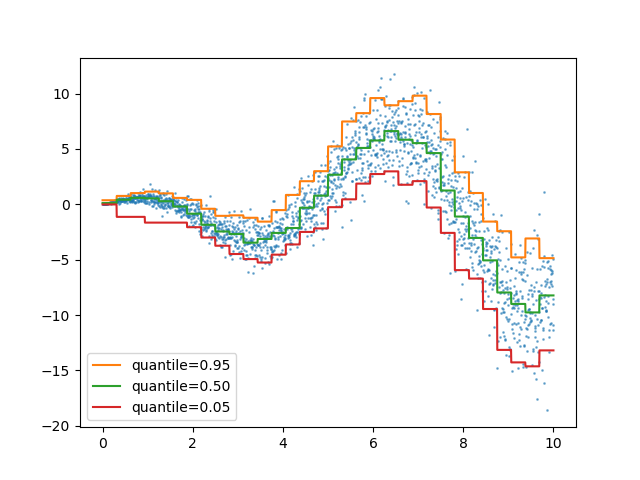
Ein Anwendungsbeispiel finden Sie unter Features in Histogramm-Gradient-Boosting-Trees
get_feature_names_out Verfügbar in allen Transformern#
get_feature_names_out ist jetzt in allen Transformern verfügbar, was die Implementierung von SLEP007 abschließt. Dies ermöglicht Pipeline, die Ausgabefunktionalitätsnamen für komplexere Pipelines zu erstellen.
from sklearn.compose import ColumnTransformer
from sklearn.datasets import fetch_openml
from sklearn.feature_selection import SelectKBest
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
numeric_features = ["age", "fare"]
numeric_transformer = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
categorical_features = ["embarked", "pclass"]
preprocessor = ColumnTransformer(
[
("num", numeric_transformer, numeric_features),
(
"cat",
OneHotEncoder(handle_unknown="ignore", sparse_output=False),
categorical_features,
),
],
verbose_feature_names_out=False,
)
log_reg = make_pipeline(preprocessor, SelectKBest(k=7), LogisticRegression())
log_reg.fit(X, y)
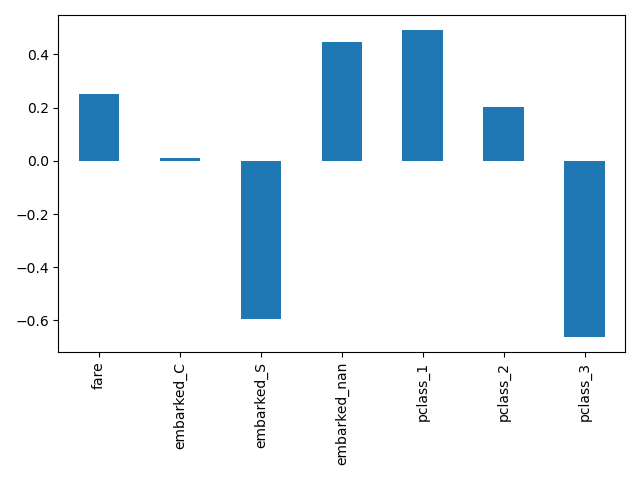
Hier schneiden wir die Pipeline, um alle Schritte außer dem letzten einzubeziehen. Die Ausgabefunktionalitätsnamen dieses Pipeline-Schnitts sind die Merkmale, die in die logistische Regression eingespeist werden. Diese Namen entsprechen direkt den Koeffizienten in der logistischen Regression.
import pandas as pd
log_reg_input_features = log_reg[:-1].get_feature_names_out()
pd.Series(log_reg[-1].coef_.ravel(), index=log_reg_input_features).plot.bar()
plt.tight_layout()
Gruppierung seltener Kategorien in OneHotEncoder#
OneHotEncoder unterstützt die Aggregation seltener Kategorien in eine einzige Ausgabe für jedes Merkmal. Die Parameter zur Aktivierung der Sammlung seltener Kategorien sind min_frequency und max_categories. Weitere Informationen finden Sie im Benutzerhandbuch.
import numpy as np
from sklearn.preprocessing import OneHotEncoder
X = np.array(
[["dog"] * 5 + ["cat"] * 20 + ["rabbit"] * 10 + ["snake"] * 3], dtype=object
).T
enc = OneHotEncoder(min_frequency=6, sparse_output=False).fit(X)
enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
Da Hund und Schlange seltene Kategorien sind, werden sie beim Transformieren zusammen gruppiert.
encoded = enc.transform(np.array([["dog"], ["snake"], ["cat"], ["rabbit"]]))
pd.DataFrame(encoded, columns=enc.get_feature_names_out())
Leistungsverbesserungen#
Reduktionen bei paarweisen Abständen für dichte float64-Datensätze wurden umgestaltet, um die nicht-blockierende Thread-Parallelität besser zu nutzen. Zum Beispiel können neighbors.NearestNeighbors.kneighbors und neighbors.NearestNeighbors.radius_neighbors bis zu 20x bzw. 5x schneller sein als zuvor. Zusammenfassend profitieren die folgenden Funktionen und Schätzer nun von verbesserter Leistung:
Um mehr über die technischen Details dieser Arbeit zu erfahren, können Sie diese Reihe von Blog-Posts lesen.
Darüber hinaus wurde die Berechnung von Verlustfunktionen mithilfe von Cython überarbeitet, was zu Leistungssteigerungen für die folgenden Schätzer führte:
MiniBatchNMF: eine Online-Version von NMF#
Die neue Klasse MiniBatchNMF implementiert eine schnellere, aber weniger genaue Version der nicht-negativen Matrixfaktorisierung (NMF). MiniBatchNMF teilt die Daten in Mini-Batches auf und optimiert das NMF-Modell online, indem es die Mini-Batches durchläuft, was es besser für große Datensätze geeignet macht. Insbesondere implementiert es partial_fit, das für das Online-Lernen verwendet werden kann, wenn die Daten nicht von Anfang an verfügbar sind oder wenn die Daten nicht in den Speicher passen.
import numpy as np
from sklearn.decomposition import MiniBatchNMF
rng = np.random.RandomState(0)
n_samples, n_features, n_components = 10, 10, 5
true_W = rng.uniform(size=(n_samples, n_components))
true_H = rng.uniform(size=(n_components, n_features))
X = true_W @ true_H
nmf = MiniBatchNMF(n_components=n_components, random_state=0)
for _ in range(10):
nmf.partial_fit(X)
W = nmf.transform(X)
H = nmf.components_
X_reconstructed = W @ H
print(
"relative reconstruction error: ",
f"{np.sum((X - X_reconstructed) ** 2) / np.sum(X**2):.5f}",
)
relative reconstruction error: 0.00364
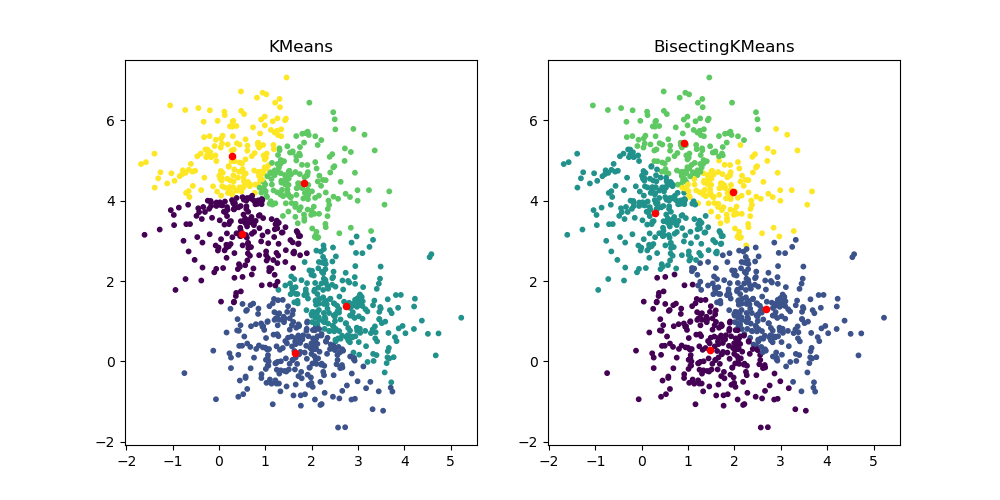
BisectingKMeans: Teilen und Clustern#
Die neue Klasse BisectingKMeans ist eine Variante von KMeans und verwendet divisives hierarchisches Clustering. Anstatt alle Zentren auf einmal zu erstellen, werden die Zentren schrittweise auf Basis eines vorherigen Clusterings ausgewählt: Ein Cluster wird wiederholt in zwei neue Cluster aufgeteilt, bis die Zielanzahl von Clustern erreicht ist, wodurch dem Clustering eine hierarchische Struktur verliehen wird.
import matplotlib.pyplot as plt
from sklearn.cluster import BisectingKMeans, KMeans
from sklearn.datasets import make_blobs
X, _ = make_blobs(n_samples=1000, centers=2, random_state=0)
km = KMeans(n_clusters=5, random_state=0, n_init="auto").fit(X)
bisect_km = BisectingKMeans(n_clusters=5, random_state=0).fit(X)
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].scatter(X[:, 0], X[:, 1], s=10, c=km.labels_)
ax[0].scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1], s=20, c="r")
ax[0].set_title("KMeans")
ax[1].scatter(X[:, 0], X[:, 1], s=10, c=bisect_km.labels_)
ax[1].scatter(
bisect_km.cluster_centers_[:, 0], bisect_km.cluster_centers_[:, 1], s=20, c="r"
)
_ = ax[1].set_title("BisectingKMeans")
Gesamtlaufzeit des Skripts: (0 Minuten 0,821 Sekunden)
Verwandte Beispiele