Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Eine Demo des Spektralen Biclustering-Algorithmus#
Dieses Beispiel demonstriert, wie ein Schachbrett-Datensatz generiert und mit dem Algorithmus SpectralBiclustering biclustert wird. Der spektrale Biclustering-Algorithmus wurde speziell entwickelt, um Daten zu clustern, indem sowohl die Zeilen (Stichproben) als auch die Spalten (Merkmale) einer Matrix gleichzeitig berücksichtigt werden. Er zielt darauf ab, Muster nicht nur zwischen Stichproben, sondern auch innerhalb von Teilmengen von Stichproben zu identifizieren, was die Erkennung lokalisierter Strukturen in den Daten ermöglicht. Dies macht spektrales Biclustering besonders gut geeignet für Datensätze, bei denen die Reihenfolge oder Anordnung der Merkmale fest ist, wie z. B. in Bildern, Zeitreihen oder Genomen.
Die Daten werden generiert, dann gemischt und an den spektralen Biclustering-Algorithmus übergeben. Die Zeilen und Spalten der gemischten Matrix werden dann neu angeordnet, um die gefundenen Bicluster zu plotten.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Beispieldaten generieren#
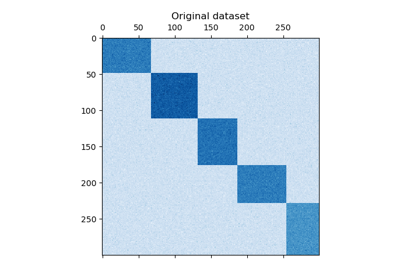
Wir generieren die Stichprobendaten mit der Funktion make_checkerboard. Jedes Pixel innerhalb von shape=(300, 300) repräsentiert mit seiner Farbe einen Wert aus einer gleichmäßigen Verteilung. Der Rauschanteil wird aus einer Normalverteilung hinzugefügt, wobei der für noise gewählte Wert die Standardabweichung ist.
Wie Sie sehen können, sind die Daten über 12 Clusterzellen verteilt und relativ gut unterscheidbar.
from matplotlib import pyplot as plt
from sklearn.datasets import make_checkerboard
n_clusters = (4, 3)
data, rows, columns = make_checkerboard(
shape=(300, 300), n_clusters=n_clusters, noise=10, shuffle=False, random_state=42
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
plt.show()

Wir mischen die Daten, und das Ziel ist es, sie anschließend mit SpectralBiclustering zu rekonstruieren.
import numpy as np
# Creating lists of shuffled row and column indices
rng = np.random.RandomState(0)
row_idx_shuffled = rng.permutation(data.shape[0])
col_idx_shuffled = rng.permutation(data.shape[1])
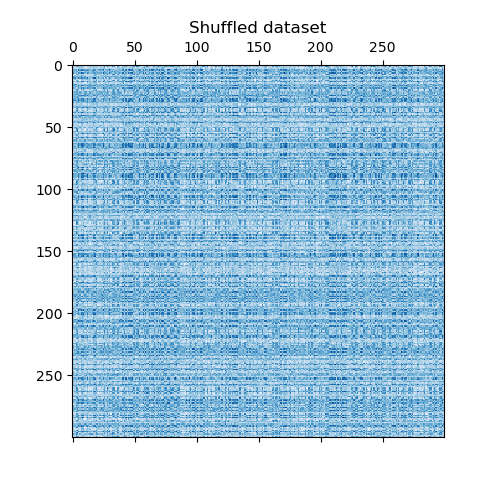
Wir definieren die gemischten Daten neu und plotten sie. Wir stellen fest, dass wir die Struktur der ursprünglichen Datenmatrix verloren haben.
data = data[row_idx_shuffled][:, col_idx_shuffled]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
plt.show()
Fitting von SpectralBiclustering#
Wir fitten das Modell und vergleichen die erhaltenen Cluster mit der Ground Truth. Beachten Sie, dass wir bei der Erstellung des Modells dieselbe Anzahl von Clustern angeben, die wir zur Erstellung des Datensatzes verwendet haben (n_clusters = (4, 3)), was dazu beiträgt, ein gutes Ergebnis zu erzielen.
from sklearn.cluster import SpectralBiclustering
from sklearn.metrics import consensus_score
model = SpectralBiclustering(n_clusters=n_clusters, method="log", random_state=0)
model.fit(data)
# Compute the similarity of two sets of biclusters
score = consensus_score(
model.biclusters_, (rows[:, row_idx_shuffled], columns[:, col_idx_shuffled])
)
print(f"consensus score: {score:.1f}")
consensus score: 1.0
Der Score liegt zwischen 0 und 1, wobei 1 einer perfekten Übereinstimmung entspricht. Er zeigt die Qualität des Biclusterings.
Plotten der Ergebnisse#
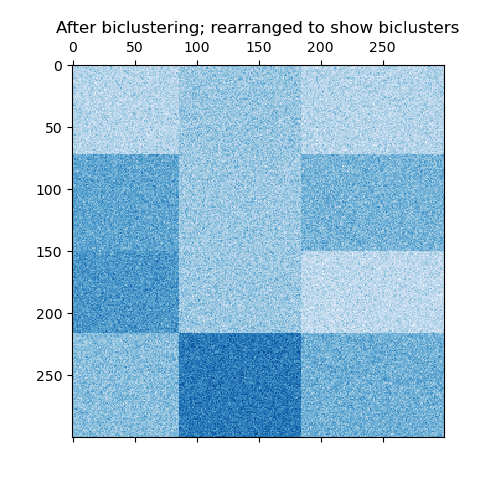
Nun ordnen wir die Daten basierend auf den von dem Modell SpectralBiclustering zugewiesenen Zeilen- und Spaltenbeschriftungen in aufsteigender Reihenfolge neu an und plotten erneut. Die row_labels_ reichen von 0 bis 3, während die column_labels_ von 0 bis 2 reichen, was insgesamt 4 Cluster pro Zeile und 3 Cluster pro Spalte darstellt.
# Reordering first the rows and then the columns.
reordered_rows = data[np.argsort(model.row_labels_)]
reordered_data = reordered_rows[:, np.argsort(model.column_labels_)]
plt.matshow(reordered_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
Als letzten Schritt möchten wir die Beziehungen zwischen den vom Modell zugewiesenen Zeilen- und Spaltenbeschriftungen demonstrieren. Dazu erstellen wir ein Gitter mit numpy.outer, das die sortierten row_labels_ und column_labels_ verwendet und zu jedem 1 addiert, um sicherzustellen, dass die Beschriftungen von 1 statt von 0 ausgehen, um die Darstellung zu verbessern.
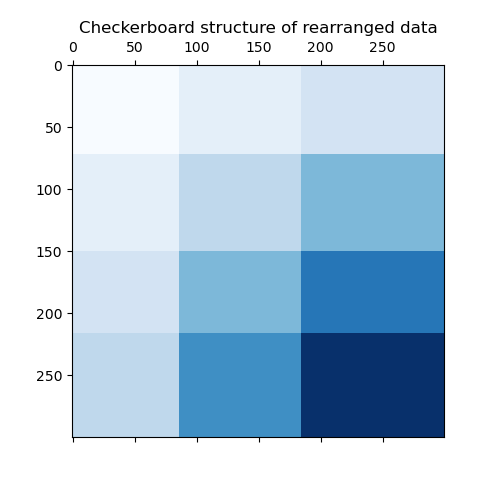
Das äußere Produkt der Zeilen- und Spaltenbeschriftungsvektoren zeigt eine Darstellung der Schachbrettstruktur, bei der verschiedene Kombinationen von Zeilen- und Spaltenbeschriftungen durch verschiedene Blautöne dargestellt werden.
Gesamtlaufzeit des Skripts: (0 Minuten 0,393 Sekunden)
Verwandte Beispiele
Auswahl der Anzahl von Clustern mit Silhouette-Analyse auf KMeans-Clustering
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen
Vergleich verschiedener hierarchischer Linkage-Methoden auf Toy-Datensätzen