Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Label Propagation Ziffern: Leistung demonstrieren#
Dieses Beispiel demonstriert die Leistungsfähigkeit des semisupervised Learnings, indem ein Label Spreading Modell trainiert wird, um handschriftliche Ziffern mit sehr wenigen Labels zu klassifizieren.
Der Datensatz mit handschriftlichen Ziffern hat insgesamt 1797 Punkte. Das Modell wird mit allen Punkten trainiert, aber nur 30 werden mit Labels versehen. Die Ergebnisse in Form einer Konfusionsmatrix und einer Reihe von Metriken für jede Klasse werden sehr gut sein.
Am Ende werden die 10 unsichersten Vorhersagen angezeigt.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Datengenerierung#
Wir verwenden den Ziffern-Datensatz. Wir verwenden nur eine Teilmenge von zufällig ausgewählten Stichproben.
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
rng = np.random.RandomState(2)
indices = np.arange(len(digits.data))
rng.shuffle(indices)
Wir haben 340 Stichproben ausgewählt, von denen nur 40 mit einem bekannten Label verknüpft werden. Daher speichern wir die Indizes der 300 anderen Stichproben, deren Labels wir nicht kennen sollen.
X = digits.data[indices[:340]]
y = digits.target[indices[:340]]
images = digits.images[indices[:340]]
n_total_samples = len(y)
n_labeled_points = 40
indices = np.arange(n_total_samples)
unlabeled_set = indices[n_labeled_points:]
Alles durcheinander würfeln
y_train = np.copy(y)
y_train[unlabeled_set] = -1
Semisupervised Learning#
Wir passen ein LabelSpreading Modell an und verwenden es, um die unbekannten Labels vorherzusagen.
from sklearn.metrics import classification_report
from sklearn.semi_supervised import LabelSpreading
lp_model = LabelSpreading(gamma=0.25, max_iter=20)
lp_model.fit(X, y_train)
predicted_labels = lp_model.transduction_[unlabeled_set]
true_labels = y[unlabeled_set]
print(
"Label Spreading model: %d labeled & %d unlabeled points (%d total)"
% (n_labeled_points, n_total_samples - n_labeled_points, n_total_samples)
)
Label Spreading model: 40 labeled & 300 unlabeled points (340 total)
Klassifikationsbericht
print(classification_report(true_labels, predicted_labels))
precision recall f1-score support
0 1.00 1.00 1.00 27
1 0.82 1.00 0.90 37
2 1.00 0.86 0.92 28
3 1.00 0.80 0.89 35
4 0.92 1.00 0.96 24
5 0.74 0.94 0.83 34
6 0.89 0.96 0.92 25
7 0.94 0.89 0.91 35
8 1.00 0.68 0.81 31
9 0.81 0.88 0.84 24
accuracy 0.90 300
macro avg 0.91 0.90 0.90 300
weighted avg 0.91 0.90 0.90 300
Konfusionsmatrix
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(
true_labels, predicted_labels, labels=lp_model.classes_
)
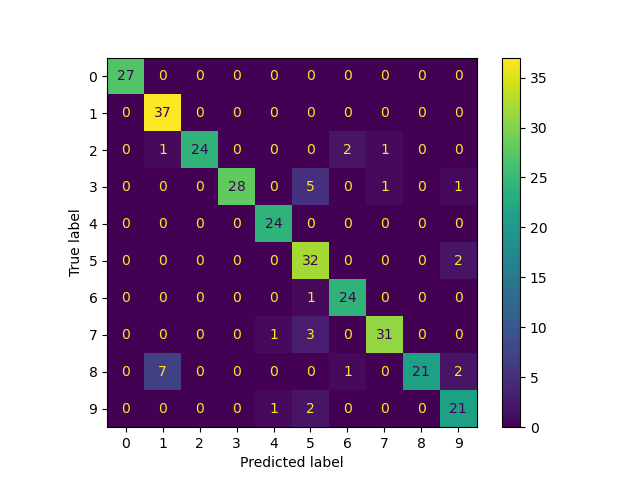
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay object at 0x7fb4b84aa410>
Die unsichersten Vorhersagen plotten#
Hier wählen wir die 10 unsichersten Vorhersagen aus und zeigen sie an.
from scipy import stats
pred_entropies = stats.distributions.entropy(lp_model.label_distributions_.T)
Die 10 unsichersten Labels auswählen
uncertainty_index = np.argsort(pred_entropies)[-10:]
Plotten
import matplotlib.pyplot as plt
f = plt.figure(figsize=(7, 5))
for index, image_index in enumerate(uncertainty_index):
image = images[image_index]
sub = f.add_subplot(2, 5, index + 1)
sub.imshow(image, cmap=plt.cm.gray_r)
plt.xticks([])
plt.yticks([])
sub.set_title(
"predict: %i\ntrue: %i" % (lp_model.transduction_[image_index], y[image_index])
)
f.suptitle("Learning with small amount of labeled data")
plt.show()

Gesamtlaufzeit des Skripts: (0 Minuten 0,249 Sekunden)
Verwandte Beispiele

Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz
Verschiedenes Agglomeratives Clustering auf einer 2D-Einbettung von Ziffern