Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Release Highlights für scikit-learn 1.3#
Wir freuen uns, die Veröffentlichung von scikit-learn 1.3 bekannt zu geben! Viele Fehlerbehebungen und Verbesserungen wurden hinzugefügt, sowie einige neue Schlüsselfunktionen. Im Folgenden beschreiben wir einige der wichtigsten Funktionen dieser Veröffentlichung. Für eine vollständige Liste aller Änderungen siehe die Release Notes.
Um die neueste Version zu installieren (mit pip)
pip install --upgrade scikit-learn
oder mit conda
conda install -c conda-forge scikit-learn
Metadaten-Routing#
Wir sind dabei, eine neue Methode zur Weiterleitung von Metadaten wie sample_weight im gesamten Code einzuführen, was die Art und Weise beeinflussen würde, wie Meta-Estimators wie pipeline.Pipeline und model_selection.GridSearchCV Metadaten weiterleiten. Während die Infrastruktur für diese Funktion bereits in dieser Veröffentlichung enthalten ist, sind die Arbeiten im Gange und nicht alle Meta-Estimators unterstützen diese neue Funktion. Mehr über diese Funktion erfahren Sie im Benutzerhandbuch für Metadaten-Routing. Beachten Sie, dass sich diese Funktion noch in der Entwicklung befindet und für die meisten Meta-Estimators noch nicht implementiert ist.
Drittentwickler können dies bereits in ihre Meta-Estimators integrieren. Weitere Details finden Sie im Entwicklerhandbuch für Metadaten-Routing.
HDBSCAN: hierarchisches dichtebasiertes Clustering#
Ursprünglich im scikit-learn-contrib-Repository gehostet, wurde cluster.HDBSCAN in scikit-learn übernommen. Es fehlen einige Funktionen der ursprünglichen Implementierung, die in zukünftigen Veröffentlichungen hinzugefügt werden. Durch die Durchführung einer modifizierten Version von cluster.DBSCAN über mehrere Epsilon-Werte gleichzeitig findet cluster.HDBSCAN Cluster unterschiedlicher Dichten, was es robuster gegenüber der Parameterwahl macht als cluster.DBSCAN. Mehr Details im Benutzerhandbuch.
import numpy as np
from sklearn.cluster import HDBSCAN
from sklearn.datasets import load_digits
from sklearn.metrics import v_measure_score
X, true_labels = load_digits(return_X_y=True)
print(f"number of digits: {len(np.unique(true_labels))}")
hdbscan = HDBSCAN(min_cluster_size=15, copy=True).fit(X)
non_noisy_labels = hdbscan.labels_[hdbscan.labels_ != -1]
print(f"number of clusters found: {len(np.unique(non_noisy_labels))}")
print(v_measure_score(true_labels[hdbscan.labels_ != -1], non_noisy_labels))
number of digits: 10
number of clusters found: 11
0.9694898472080092
TargetEncoder: eine neue Kategorie-Encoding-Strategie#
Gut geeignet für kategorische Merkmale mit hoher Kardinalität kodiert preprocessing.TargetEncoder die Kategorien basierend auf einer geschrumpften Schätzung der durchschnittlichen Zielwerte für Beobachtungen, die zu dieser Kategorie gehören. Mehr Details im Benutzerhandbuch.
import numpy as np
from sklearn.preprocessing import TargetEncoder
X = np.array([["cat"] * 30 + ["dog"] * 20 + ["snake"] * 38], dtype=object).T
y = [90.3] * 30 + [20.4] * 20 + [21.2] * 38
enc = TargetEncoder(random_state=0)
X_trans = enc.fit_transform(X, y)
enc.encodings_
[array([90.3, 20.4, 21.2])]
Unterstützung für fehlende Werte in Entscheidungsbäumen#
Die Klassen tree.DecisionTreeClassifier und tree.DecisionTreeRegressor unterstützen jetzt fehlende Werte. Für jeden potenziellen Schwellenwert bei den vorhandenen Daten wird der Splitter den Split mit allen fehlenden Werten, die zum linken oder zum rechten Knoten gehen, auswerten. Weitere Details finden Sie im Benutzerhandbuch oder sehen Sie sich Features in Histogram Gradient Boosting Trees als Anwendungsbeispiel für diese Funktion in HistGradientBoostingRegressor an.
import numpy as np
from sklearn.tree import DecisionTreeClassifier
X = np.array([0, 1, 6, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
tree = DecisionTreeClassifier(random_state=0).fit(X, y)
tree.predict(X)
array([0, 0, 1, 1])
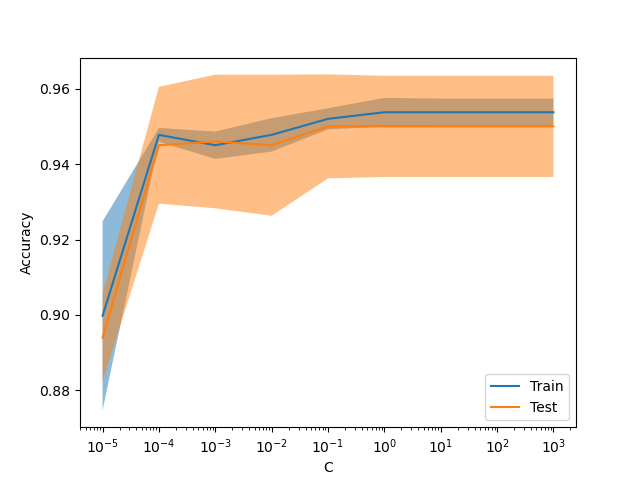
Neue Anzeige ValidationCurveDisplay#
model_selection.ValidationCurveDisplay ist jetzt verfügbar, um Ergebnisse von model_selection.validation_curve zu plotten.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ValidationCurveDisplay
X, y = make_classification(1000, 10, random_state=0)
_ = ValidationCurveDisplay.from_estimator(
LogisticRegression(),
X,
y,
param_name="C",
param_range=np.geomspace(1e-5, 1e3, num=9),
score_type="both",
score_name="Accuracy",
)
Gamma-Verlust für Gradient Boosting#
Die Klasse ensemble.HistGradientBoostingRegressor unterstützt die Gamma-Devianz-Verlustfunktion über loss="gamma". Diese Verlustfunktion ist nützlich für die Modellierung rein positiver Ziele mit einer rechtsschiefen Verteilung.
import numpy as np
from sklearn.datasets import make_low_rank_matrix
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.model_selection import cross_val_score
n_samples, n_features = 500, 10
rng = np.random.RandomState(0)
X = make_low_rank_matrix(n_samples, n_features, random_state=rng)
coef = rng.uniform(low=-10, high=20, size=n_features)
y = rng.gamma(shape=2, scale=np.exp(X @ coef) / 2)
gbdt = HistGradientBoostingRegressor(loss="gamma")
cross_val_score(gbdt, X, y).mean()
np.float64(0.46858513287221654)
Gruppierung seltener Kategorien in OrdinalEncoder#
Ähnlich wie preprocessing.OneHotEncoder unterstützt die Klasse preprocessing.OrdinalEncoder nun die Aggregation seltener Kategorien zu einer einzigen Ausgabe für jedes Merkmal. Die Parameter zur Aktivierung der Sammlung seltener Kategorien sind min_frequency und max_categories. Weitere Details finden Sie im Benutzerhandbuch.
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
X = np.array(
[["dog"] * 5 + ["cat"] * 20 + ["rabbit"] * 10 + ["snake"] * 3], dtype=object
).T
enc = OrdinalEncoder(min_frequency=6).fit(X)
enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
Gesamtlaufzeit des Skripts: (0 Minuten 1,295 Sekunden)
Verwandte Beispiele