Hinweis
Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Label Propagation Kreise: Erlernen einer komplexen Struktur#
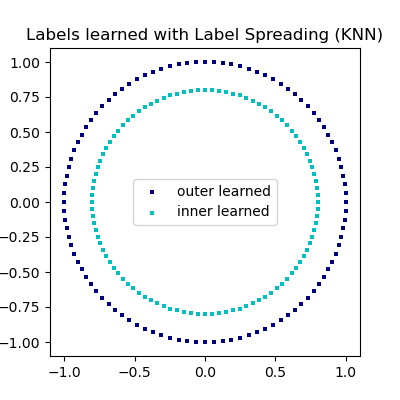
Beispiel für LabelPropagation, das eine komplexe interne Struktur lernt, um „Manifold Learning“ zu demonstrieren. Der äußere Kreis sollte als „rot“ und der innere Kreis als „blau“ gekennzeichnet werden. Da beide Labelgruppen innerhalb ihrer eigenen, unterscheidbaren Form liegen, können wir sehen, dass die Labels korrekt um den Kreis herum propagiert werden.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
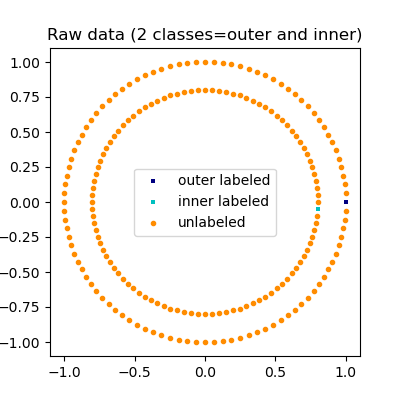
Wir generieren einen Datensatz mit zwei konzentrischen Kreisen. Zusätzlich ist jedem Sample des Datensatzes ein Label zugeordnet, das: 0 (gehört zum äußeren Kreis), 1 (gehört zum inneren Kreis) und -1 (unbekannt) ist. Hier sind alle Labels bis auf zwei als unbekannt markiert.
import numpy as np
from sklearn.datasets import make_circles
n_samples = 200
X, y = make_circles(n_samples=n_samples, shuffle=False)
outer, inner = 0, 1
labels = np.full(n_samples, -1.0)
labels[0] = outer
labels[-1] = inner
Rohe Daten plotten
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 4))
plt.scatter(
X[labels == outer, 0],
X[labels == outer, 1],
color="navy",
marker="s",
lw=0,
label="outer labeled",
s=10,
)
plt.scatter(
X[labels == inner, 0],
X[labels == inner, 1],
color="c",
marker="s",
lw=0,
label="inner labeled",
s=10,
)
plt.scatter(
X[labels == -1, 0],
X[labels == -1, 1],
color="darkorange",
marker=".",
label="unlabeled",
)
plt.legend(scatterpoints=1, shadow=False, loc="center")
_ = plt.title("Raw data (2 classes=outer and inner)")
Das Ziel von LabelSpreading ist es, einem Sample ein Label zuzuordnen, bei dem das Label anfänglich unbekannt ist.
from sklearn.semi_supervised import LabelSpreading
label_spread = LabelSpreading(kernel="knn", alpha=0.8)
label_spread.fit(X, labels)
Nun können wir überprüfen, welche Labels jedem Sample zugeordnet wurden, als das Label unbekannt war.
output_labels = label_spread.transduction_
output_label_array = np.asarray(output_labels)
outer_numbers = (output_label_array == outer).nonzero()[0]
inner_numbers = (output_label_array == inner).nonzero()[0]
plt.figure(figsize=(4, 4))
plt.scatter(
X[outer_numbers, 0],
X[outer_numbers, 1],
color="navy",
marker="s",
lw=0,
s=10,
label="outer learned",
)
plt.scatter(
X[inner_numbers, 0],
X[inner_numbers, 1],
color="c",
marker="s",
lw=0,
s=10,
label="inner learned",
)
plt.legend(scatterpoints=1, shadow=False, loc="center")
plt.title("Labels learned with Label Spreading (KNN)")
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 0,128 Sekunden)
Verwandte Beispiele
Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz
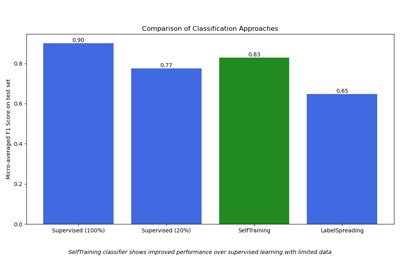
Semi-überwachte Klassifikation auf einem Textdatensatz