Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Successive Halving Iterations#
Dieses Beispiel veranschaulicht, wie eine successive Halving-Suche (HalvingGridSearchCV und HalvingRandomSearchCV) iterativ die beste Parameterkombination aus mehreren Kandidaten auswählt.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import randint
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv # noqa: F401
from sklearn.model_selection import HalvingRandomSearchCV
Wir definieren zunächst den Parameterraum und trainieren eine Instanz von HalvingRandomSearchCV.
rng = np.random.RandomState(0)
X, y = datasets.make_classification(n_samples=400, n_features=12, random_state=rng)
clf = RandomForestClassifier(n_estimators=20, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 6),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
Wir können nun das Attribut ``cv_results_`` des Such-Estimators verwenden, um die Entwicklung der Suche zu inspizieren und zu plotten.
results = pd.DataFrame(rsh.cv_results_)
results["params_str"] = results.params.apply(str)
results.drop_duplicates(subset=("params_str", "iter"), inplace=True)
mean_scores = results.pivot(
index="iter", columns="params_str", values="mean_test_score"
)
ax = mean_scores.plot(legend=False, alpha=0.6)
labels = [
f"iter={i}\nn_samples={rsh.n_resources_[i]}\nn_candidates={rsh.n_candidates_[i]}"
for i in range(rsh.n_iterations_)
]
ax.set_xticks(range(rsh.n_iterations_))
ax.set_xticklabels(labels, rotation=45, multialignment="left")
ax.set_title("Scores of candidates over iterations")
ax.set_ylabel("mean test score", fontsize=15)
ax.set_xlabel("iterations", fontsize=15)
plt.tight_layout()
plt.show()

Anzahl der Kandidaten und Menge der Ressource in jeder Iteration#
In der ersten Iteration wird eine kleine Menge an Ressourcen verwendet. Die Ressource ist hier die Anzahl der Samples, auf denen die Estimators trainiert werden. Alle Kandidaten werden ausgewertet.
In der zweiten Iteration wird nur die beste Hälfte der Kandidaten ausgewertet. Die Anzahl der zugewiesenen Ressourcen wird verdoppelt: Die Kandidaten werden auf doppelt so vielen Samples ausgewertet.
Dieser Prozess wird bis zur letzten Iteration wiederholt, in der nur noch 2 Kandidaten übrig sind. Der beste Kandidat ist der Kandidat, der in der letzten Iteration die beste Punktzahl erzielt.
Gesamtlaufzeit des Skripts: (0 Minuten 5,524 Sekunden)
Verwandte Beispiele
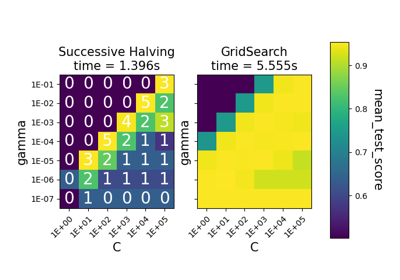
Vergleich zwischen Gitter-Suche und sukzessiver Halbierung

Vergleich von zufälliger Suche und Gitter-Suche zur Hyperparameter-Schätzung

Benutzerdefinierte Refit-Strategie einer Gitter-Suche mit Kreuzvalidierung