Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Plotten von Kreuzvalidierten Vorhersagen#
Dieses Beispiel zeigt, wie cross_val_predict zusammen mit PredictionErrorDisplay verwendet werden kann, um Vorhersagefehler zu visualisieren.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Wir laden den Diabetes-Datensatz und erstellen eine Instanz eines linearen Regressionsmodells.
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
X, y = load_diabetes(return_X_y=True)
lr = LinearRegression()
cross_val_predict gibt ein Array derselben Größe wie y zurück, wobei jeder Eintrag eine durch Kreuzvalidierung erhaltene Vorhersage ist.
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(lr, X, y, cv=10)
Da cv=10 ist, bedeutet dies, dass wir 10 Modelle trainiert haben und jedes Modell verwendet wurde, um auf einem der 10 Folds vorherzusagen. Wir können nun die PredictionErrorDisplay verwenden, um die Vorhersagefehler zu visualisieren.
Auf der linken Achse plottetten wir die beobachteten Werte \(y\) gegen die vorhergesagten Werte \(\hat{y}\), die von den Modellen geliefert werden. Auf der rechten Achse plottetten wir die Residuen (d. h. die Differenz zwischen den beobachteten und den vorhergesagten Werten) gegen die vorhergesagten Werte.
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="actual_vs_predicted",
subsample=100,
ax=axs[0],
random_state=0,
)
axs[0].set_title("Actual vs. Predicted values")
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="residual_vs_predicted",
subsample=100,
ax=axs[1],
random_state=0,
)
axs[1].set_title("Residuals vs. Predicted Values")
fig.suptitle("Plotting cross-validated predictions")
plt.tight_layout()
plt.show()
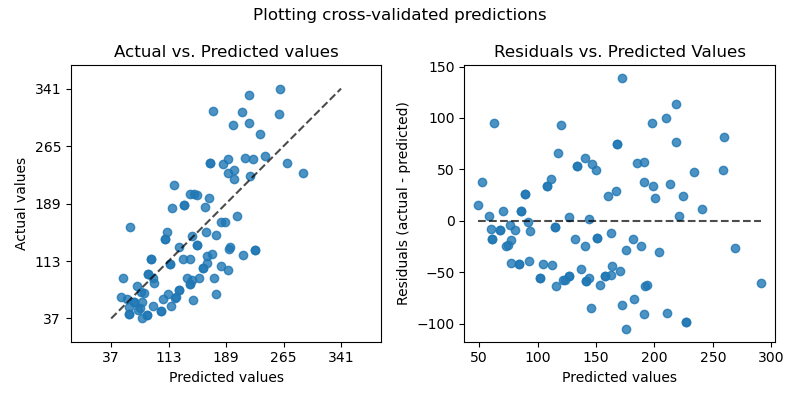
Es ist wichtig zu beachten, dass wir cross_val_predict in diesem Beispiel nur zu Visualisierungszwecken verwendet haben.
Es wäre problematisch, die Modellleistung quantitativ zu bewerten, indem eine einzige Leistungsmetrik aus den verketteten Vorhersagen berechnet wird, die von cross_val_predict zurückgegeben werden, wenn sich die verschiedenen CV-Folds in Größe und Verteilung unterscheiden.
Es wird empfohlen, per-Fold-Leistungsmetriken zu berechnen mit: cross_val_score oder cross_validate stattdessen.
Gesamtlaufzeit des Skripts: (0 Minuten 0,160 Sekunden)
Verwandte Beispiele
Auswirkung der Transformation der Ziele in einem Regressionsmodell
Vergleich der Leistung von Bisecting K-Means und Regular K-Means
