Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
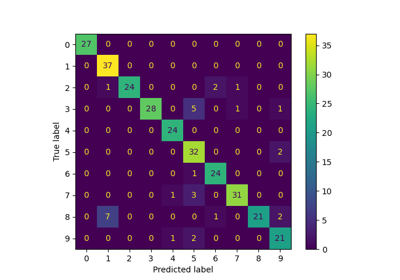
Entscheidungsgrenze von semi-überwachten Klassifikatoren im Vergleich zu SVM auf dem Iris-Datensatz#
Dieses Beispiel vergleicht die von zwei semi-überwachten Methoden gelernten Entscheidungsgrenzen, nämlich LabelSpreading und SelfTrainingClassifier, wobei der Anteil der gelabelten Trainingsdaten von kleinen Bruchteilen bis zum vollständigen Datensatz variiert wird.
Beide Methoden basieren auf RBF-Kernen: LabelSpreading verwendet ihn standardmäßig, und SelfTrainingClassifier wird hier mit SVC als Basis-Schätzer (ebenfalls standardmäßig RBF-basiert) kombiniert, um einen fairen Vergleich zu ermöglichen. Bei 100 % gelabelten Daten reduziert sich SelfTrainingClassifier zu einem vollständig überwachten SVC, da keine ungelabelten Punkte mehr übrig sind, die pseudo-gelabelt werden könnten.
In einem zweiten Abschnitt erklären wir, wie predict_proba in LabelSpreading und SelfTrainingClassifier berechnet wird.
Siehe Semi-überwachte Klassifizierung auf einem Textdatensatz für einen Leistungsvergleich von LabelSpreading und SelfTrainingClassifier.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.semi_supervised import LabelSpreading, SelfTrainingClassifier
from sklearn.svm import SVC
iris = load_iris()
X = iris.data[:, :2]
y = iris.target
rng = np.random.RandomState(42)
y_rand = rng.rand(y.shape[0])
y_10 = np.copy(y)
y_10[y_rand > 0.1] = -1 # set random samples to be unlabeled
y_30 = np.copy(y)
y_30[y_rand > 0.3] = -1
ls10 = (LabelSpreading().fit(X, y_10), y_10, "LabelSpreading with 10% labeled data")
ls30 = (LabelSpreading().fit(X, y_30), y_30, "LabelSpreading with 30% labeled data")
ls100 = (LabelSpreading().fit(X, y), y, "LabelSpreading with 100% labeled data")
base_classifier = SVC(gamma=0.5, probability=True, random_state=42)
st10 = (
SelfTrainingClassifier(base_classifier).fit(X, y_10),
y_10,
"Self-training with 10% labeled data",
)
st30 = (
SelfTrainingClassifier(base_classifier).fit(X, y_30),
y_30,
"Self-training with 30% labeled data",
)
rbf_svc = (
base_classifier.fit(X, y),
y,
"SVC with rbf kernel\n(equivalent to Self-training with 100% labeled data)",
)
tab10 = plt.get_cmap("tab10")
color_map = {cls: tab10(cls) for cls in np.unique(y)}
color_map[-1] = (1, 1, 1)
classifiers = (ls10, st10, ls30, st30, ls100, rbf_svc)
fig, axes = plt.subplots(nrows=3, ncols=2, sharex="col", sharey="row", figsize=(10, 12))
axes = axes.ravel()
handles = [
mpatches.Patch(facecolor=tab10(i), edgecolor="black", label=iris.target_names[i])
for i in np.unique(y)
]
handles.append(mpatches.Patch(facecolor="white", edgecolor="black", label="Unlabeled"))
for ax, (clf, y_train, title) in zip(axes, classifiers):
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="predict_proba",
plot_method="contourf",
ax=ax,
)
colors = [color_map[label] for label in y_train]
ax.scatter(X[:, 0], X[:, 1], c=colors, edgecolor="black")
ax.set_title(title)
fig.suptitle(
"Semi-supervised decision boundaries with varying fractions of labeled data", y=1
)
fig.legend(
handles=handles, loc="lower center", ncol=len(handles), bbox_to_anchor=(0.5, 0.0)
)
fig.tight_layout(rect=[0, 0.03, 1, 1])
plt.show()
Wir beobachten, dass die Entscheidungsgrenzen bereits denjenigen, die mit den vollständig verfügbaren gelabelten Daten zum Training verwendet werden, recht ähnlich sind, selbst wenn nur ein sehr kleiner Teil der Labels verwendet wird.
Interpretation von predict_proba#
predict_proba in LabelSpreading#
LabelSpreading konstruiert aus den Daten einen Ähnlichkeitsgraphen, der standardmäßig einen RBF-Kern verwendet. Das bedeutet, dass jeder Sample mit jedem anderen mit einem Gewicht verbunden ist, das mit ihrer quadrierten euklidischen Distanz abfällt, skaliert durch einen Parameter gamma.
Sobald wir diesen gewichteten Graphen haben, werden die Labels entlang der Graphenkanten propagiert. Jeder Sample nimmt allmählich eine weiche Label-Verteilung an, die einen gewichteten Durchschnitt der Labels seiner Nachbarn widerspiegelt, bis der Prozess konvergiert. Diese per-Sample-Verteilungen werden in label_distributions_ gespeichert.
predict_proba berechnet die Klassenwahrscheinlichkeiten für einen neuen Punkt, indem es einen gewichteten Durchschnitt der Zeilen in label_distributions_ nimmt, wobei die Gewichte aus den RBF-Kern-Ähnlichkeiten zwischen dem neuen Punkt und den Trainingssamples stammen. Die gemittelten Werte werden dann neu normiert, sodass sie sich zu eins summieren.
Beachten Sie einfach, dass es sich bei diesen „Wahrscheinlichkeiten“ um graphenbasierte Scores handelt, nicht um kalibrierte Posterior-Werte. Überinterpretieren Sie deren absolute Werte nicht.
from sklearn.metrics.pairwise import rbf_kernel
ls = ls100[0] # fitted LabelSpreading instance
x_query = np.array([[3.5, 1.5]]) # point in the soft blue region
# Step 1: similarities between query and all training samples
W = rbf_kernel(x_query, X, gamma=ls.gamma) # `gamma=20` by default
# Step 2: weighted average of label distributions
probs = np.dot(W, ls.label_distributions_)
# Step 3: normalize to sum to 1
probs /= probs.sum(axis=1, keepdims=True)
print("Manual:", probs)
print("API :", ls.predict_proba(x_query))
Manual: [[0.96 0.03 0.01]]
API : [[0.96 0.03 0.01]]
predict_proba in SelfTrainingClassifier#
SelfTrainingClassifier funktioniert, indem er wiederholt seinen Basis-Schätzer auf den aktuell gelabelten Daten anpasst und dann Pseudo-Labels für ungelabelte Punkte hinzufügt, deren vorhergesagte Wahrscheinlichkeiten einen Konfidenzschwellenwert überschreiten. Dieser Prozess wird fortgesetzt, bis keine neuen Punkte mehr gelabelt werden können, woraufhin der Klassifikator einen finalen angepassten Basis-Schätzer im Attribut estimator_ gespeichert hat.
Wenn Sie predict_proba für den SelfTrainingClassifier aufrufen, delegiert er dies einfach an diesen finalen Schätzer.
st = st10[0]
print("Manual:", st.estimator_.predict_proba(x_query))
print("API :", st.predict_proba(x_query))
Manual: [[0.52 0.29 0.19]]
API : [[0.52 0.29 0.19]]
Bei beiden Methoden kann semi-überwachtes Lernen als Konstruktion einer kategorischen Verteilung über Klassen für jede Sample verstanden werden. LabelSpreading hält diese Verteilungen weich und aktualisiert sie durch graphenbasierte Propagation. Vorhersagen (einschließlich predict_proba) bleiben an den Trainingsdatensatz gebunden, der für die Inferenz gespeichert werden muss.
SelfTrainingClassifier verwendet diese Verteilungen stattdessen intern, um zu entscheiden, welche ungelabelten Punkte während des Trainings Pseudo-Labels zugewiesen werden sollen. Zur Vorhersagezeit stammen die zurückgegebenen Wahrscheinlichkeiten jedoch direkt vom finalen angepassten Schätzer, und daher erfordert die Entscheidungsregel nicht das Speichern der Trainingsdaten.
Gesamtlaufzeit des Skripts: (0 Minuten 0,818 Sekunden)
Verwandte Beispiele
Semi-überwachte Klassifikation auf einem Textdatensatz
Auswirkung der Änderung des Schwellenwerts für Self-Training