load_iris#
- sklearn.datasets.load_iris(*, return_X_y=False, as_frame=False)[Quelle]#
Lädt und gibt den Iris Datensatz (Klassifikation) zurück.
Der Iris-Datensatz ist ein klassischer und sehr einfacher Datensatz für die Mehrklassenklassifizierung.
Klassen
3
Stichproben pro Klasse
50
Gesamtanzahl Samples
150
Dimensionalität
4
Merkmale
real, positive
Lesen Sie mehr im Benutzerhandbuch.
Geändert in Version 0.20: Zwei fehlerhafte Datenpunkte wurden gemäß Fishers Arbeit korrigiert. Die neue Version ist dieselbe wie in R, aber nicht wie im UCI Machine Learning Repository.
- Parameter:
- return_X_ybool, Standard=False
Wenn True, wird ein Bunch-Objekt zurückgegeben, das
(data, target)enthält. Weitere Informationen zu den Objektendataundtargetfinden Sie unten.Hinzugefügt in Version 0.18.
- as_framebool, default=False
Wenn True, sind die Daten ein pandas DataFrame, einschließlich Spalten mit geeigneten dtypes (numerisch). Das Ziel ist ein pandas DataFrame oder eine Series, abhängig von der Anzahl der Zielspalten. Wenn
return_X_yTrue ist, dann sind (data,target) pandas DataFrames oder Series wie unten beschrieben.Hinzugefügt in Version 0.23.
- Gibt zurück:
- data
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- data{ndarray, dataframe} der Form (150, 4)
Die Datenmatrix. Wenn
as_frame=True, istdataein pandas DataFrame.- target: {ndarray, Series} der Form (150,)
Das Klassifizierungsziel. Wenn
as_frame=True, isttargeteine pandas Series.- feature_names: list
Die Namen der Datensatzspalten.
- target_names: ndarray der Form (3, )
Die Namen der Zielklassen.
- frame: DataFrame der Form (150, 5)
Nur vorhanden, wenn
as_frame=True. DataFrame mitdataundtarget.Hinzugefügt in Version 0.23.
- DESCR: str
Die vollständige Beschreibung des Datensatzes.
- filename: str
Der Pfad zum Speicherort der Daten.
Hinzugefügt in Version 0.20.
- (data, target)tuple, wenn
return_X_yTrue ist Ein Tupel aus zwei ndarrays. Das erste enthält ein 2D-Array der Form (n_samples, n_features), wobei jede Zeile eine Stichprobe und jede Spalte die Merkmale darstellt. Das zweite ndarray der Form (n_samples,) enthält die Zielstichproben.
Hinzugefügt in Version 0.18.
- data
Beispiele
Nehmen wir an, Sie interessieren sich für die Stichproben 10, 25 und 50 und möchten deren Klassennamen erfahren.
>>> from sklearn.datasets import load_iris >>> data = load_iris() >>> samples = [10, 25, 50] >>> data.target[samples] array([0, 0, 1]) >>> data.target_names[data.target[samples]] array(['setosa', 'setosa', 'versicolor'], dtype='<U10')
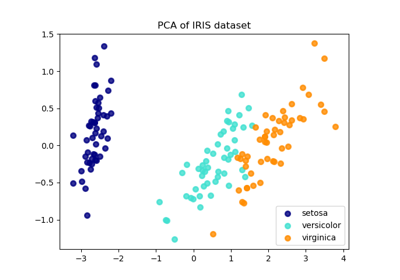
Siehe Hauptkomponentenanalyse (PCA) auf dem Iris-Datensatz für ein detaillierteres Beispiel, wie man mit dem Iris-Datensatz arbeitet.
Galeriebeispiele#

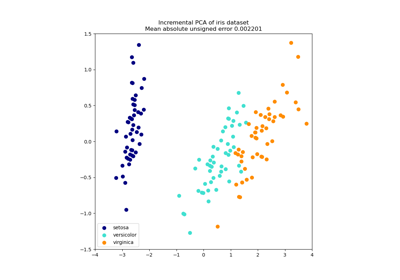
Principal Component Analysis (PCA) auf dem Iris-Datensatz
Vergleich von LDA und PCA 2D-Projektion des Iris-Datensatzes
Faktorenanalyse (mit Rotation) zur Visualisierung von Mustern
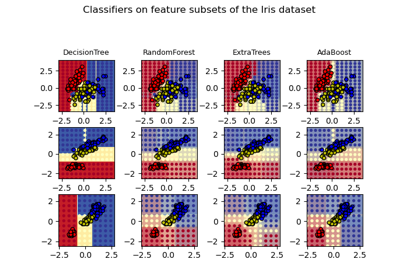
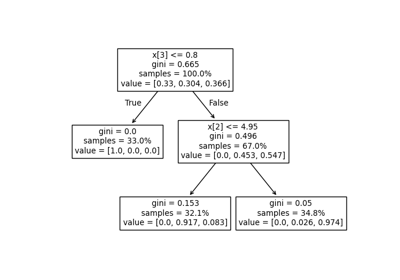
Entscheidungsflächen von Ensembles von Bäumen auf dem Iris-Datensatz plotten
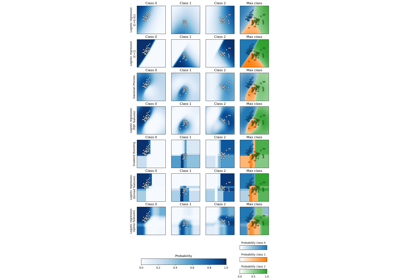
Gauß-Prozess-Klassifikation (GPC) auf dem Iris-Datensatz
Regularisierungspfad der L1-Logistischen Regression
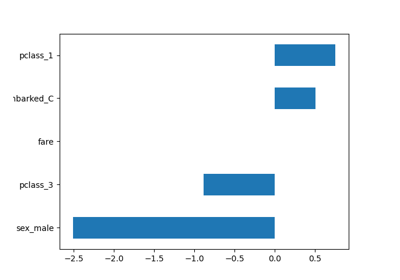
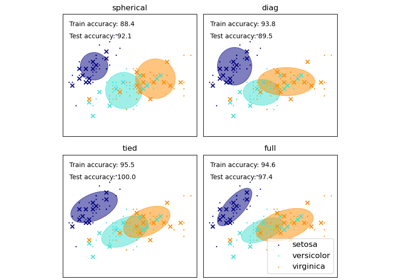
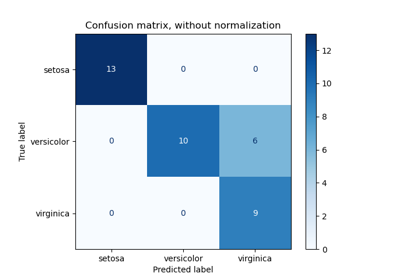
Leistung eines Klassifikators mit Konfusionsmatrix bewerten
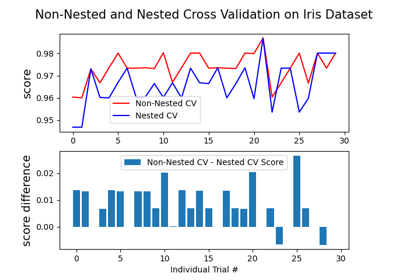
Verschachtelte vs. nicht verschachtelte Kreuzvalidierung
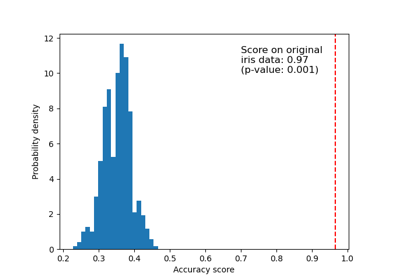
Testen der Signifikanz eines Klassifikations-Scores mit Permutationen
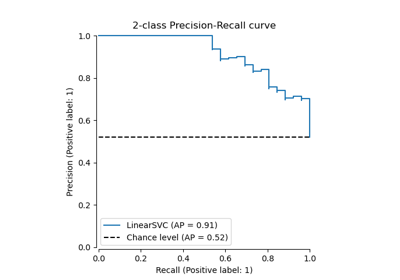
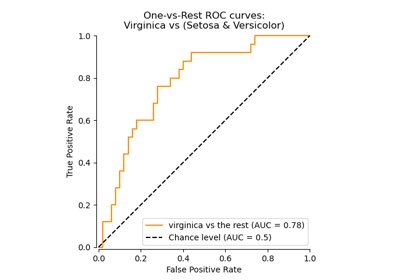
Multiklassen-Receiver Operating Characteristic (ROC)
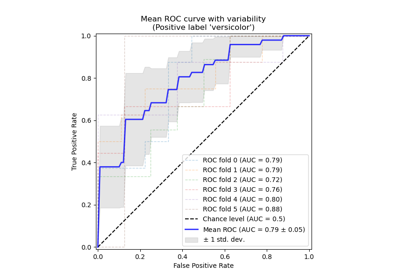
Receiver Operating Characteristic (ROC) mit Kreuzvalidierung
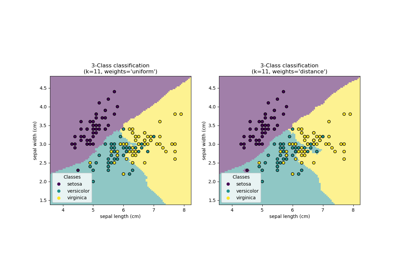
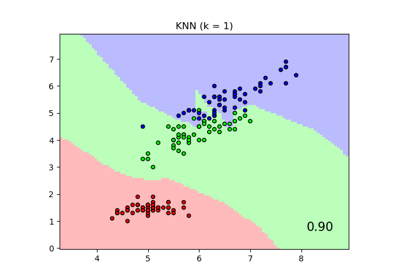
Vergleich von Nächsten Nachbarn mit und ohne Neighborhood Components Analysis
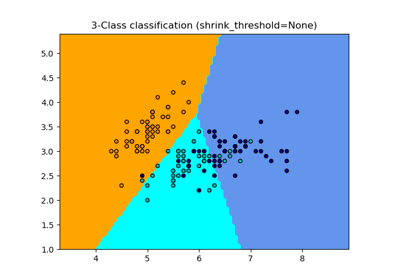
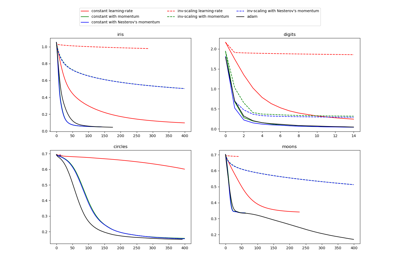
Vergleich von stochastischen Lernstrategien für MLPClassifier

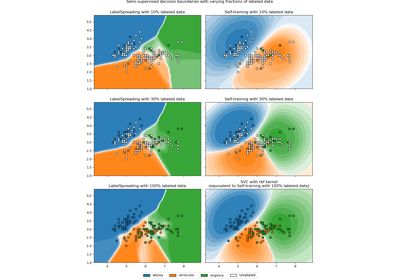
Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz

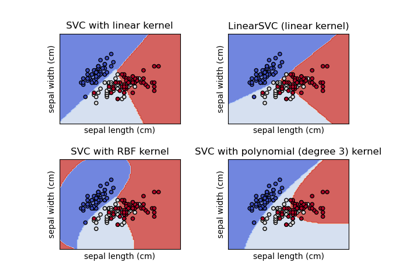
Verschiedene SVM-Klassifikatoren im Iris-Datensatz plotten
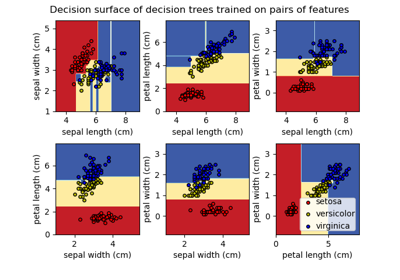
Entscheidungsfläche von Entscheidungsbäumen, trainiert auf dem Iris-Datensatz, plotten