Ridge#
- class sklearn.linear_model.Ridge(alpha=1.0, *, fit_intercept=True, copy_X=True, max_iter=None, tol=0.0001, solver='auto', positive=False, random_state=None)[Quelle]#
Lineare Kleinste-Quadrate mit l2-Regularisierung.
Minimiert die Zielfunktion
||y - Xw||^2_2 + alpha * ||w||^2_2
Dieses Modell löst ein Regressionsmodell, bei dem die Verlustfunktion die Funktion der kleinsten Quadrate ist und die Regularisierung durch die l2-Norm gegeben ist. Auch bekannt als Ridge-Regression oder Tikhonov-Regularisierung. Dieser Schätzer hat eingebaute Unterstützung für multivariate Regression (d.h. wenn y eine 2D-Array der Form (n_samples, n_targets) ist).
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- alpha{float, ndarray der Form (n_targets,)}, default=1.0
Konstante, die den L2-Term multipliziert und die Stärke der Regularisierung steuert.
alphamuss eine nicht-negative Gleitkommazahl sein, d.h. im Bereich[0, inf).Wenn
alpha = 0, ist die Zielfunktion äquivalent zu gewöhnlichen kleinsten Quadraten, gelöst durch dasLinearRegression-Objekt. Aus numerischen Gründen wird die Verwendung vonalpha = 0mit demRidge-Objekt nicht empfohlen. Verwenden Sie stattdessen dasLinearRegression-Objekt.Wenn ein Array übergeben wird, wird angenommen, dass die Strafen spezifisch für die Ziele sind. Daher müssen sie in der Anzahl übereinstimmen.
- fit_interceptbool, Standardwert=True
Ob der Achsenabschnitt für dieses Modell angepasst werden soll. Wenn auf falsch gesetzt, wird kein Achsenabschnitt zur Berechnung verwendet (d.h.
Xundywerden als zentriert erwartet).- copy_Xbool, Standardwert=True
Wenn True, wird X kopiert; andernfalls kann es überschrieben werden.
- max_iterint, Standard=None
Maximale Anzahl von Iterationen für den konjugierten Gradientenlöser. Für die Löser ‚sparse_cg‘ und ‚lsqr‘ wird der Standardwert von scipy.sparse.linalg bestimmt. Für den ‚sag‘-Löser beträgt der Standardwert 1000. Für den ‚lbfgs‘-Löser beträgt der Standardwert 15000.
- tolfloat, Standard=1e-4
Die Genauigkeit der Lösung (
coef_) wird durchtolbestimmt, das ein anderes Konvergenzkriterium für jeden Löser spezifiziert‘svd’:
tolhat keinen Einfluss.‘cholesky’:
tolhat keinen Einfluss.‘sparse_cg’: Norm der Residuen kleiner als
tol.‘lsqr’:
tolwird als atol und btol von scipy.sparse.linalg.lsqr gesetzt, welche die Norm des Residuenvektors im Verhältnis zu den Normen von Matrix und Koeffizienten steuern.‘sag‘ und ‚saga‘: relative Änderung der Koeffizienten kleiner als
tol.‘lbfgs‘: Maximum des absoluten (projizierten) Gradienten=max|Residuen| kleiner als
tol.
Geändert in Version 1.2: Standardwert von 1e-3 auf 1e-4 geändert, um mit anderen linearen Modellen übereinzustimmen.
- solver{‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
Löser, der in den rechnerischen Routinen verwendet werden soll
‚auto‘ wählt den Löser automatisch basierend auf dem Datentyp aus.
‚svd‘ verwendet eine Singulärwertzerlegung (Singular Value Decomposition, SVD) von X zur Berechnung der Ridge-Koeffizienten. Dies ist der stabilste Löser, insbesondere stabiler für singuläre Matrizen als ‚cholesky‘, aber auf Kosten einer langsameren Ausführung.
‚cholesky‘ verwendet die Standardfunktion
scipy.linalg.solve, um eine geschlossene Form für die Lösung zu erhalten.‚sparse_cg‘ verwendet den konjugierten Gradientenlöser, wie er in
scipy.sparse.linalg.cgzu finden ist. Als iterativer Algorithmus ist dieser Löser besser für große Datenmengen geeignet als ‚cholesky‘ (Möglichkeit zur Einstellung vontolundmax_iter).‚lsqr‘ verwendet die dedizierte regularisierte Least-Squares-Routine
scipy.sparse.linalg.lsqr. Dies ist die schnellste und verwendet ein iteratives Verfahren.‚sag‘ verwendet einen Stochastic Average Gradient Descent und ‚saga‘ verwendet seine verbesserte, unverzerrte Version namens SAGA. Beide Methoden verwenden ebenfalls ein iteratives Verfahren und sind oft schneller als andere Löser, wenn sowohl n_samples als auch n_features groß sind. Beachten Sie, dass die schnelle Konvergenz von ‚sag‘ und ‚saga‘ nur für Merkmale mit ungefähr gleicher Skala garantiert ist. Sie können die Daten mit einem Scaler aus
sklearn.preprocessingvorverarbeiten.‚lbfgs‘ verwendet den L-BFGS-B-Algorithmus, der in
scipy.optimize.minimizeimplementiert ist. Er kann nur verwendet werden, wennpositiveTrue ist.
Alle Löser außer ‚svd‘ unterstützen sowohl dichte als auch spärliche Daten. Nur ‚lsqr‘, ‚sag‘, ‚sparse_cg‘ und ‚lbfgs‘ unterstützen jedoch spärliche Eingaben, wenn
fit_interceptTrue ist.Hinzugefügt in Version 0.17: Stochastic Average Gradient Descent Löser.
Hinzugefügt in Version 0.19: SAGA-Löser.
- positivebool, Standardwert=False
Wenn auf
Truegesetzt, werden die Koeffizienten gezwungen, positiv zu sein. In diesem Fall wird nur der ‚lbfgs‘-Löser unterstützt.- random_stateint, RandomState instance, default=None
Verwendet, wenn
solver== ‚sag‘ oder ‚saga‘ ist, um die Daten zu mischen. Siehe Glossar für Details.Hinzugefügt in Version 0.17:
random_statezur Unterstützung von Stochastic Average Gradient.
- Attribute:
- coef_ndarray der Form (n_features,) oder (n_targets, n_features)
Gewichtsvektor(en).
- intercept_float oder ndarray der Form (n_targets,)
Unabhängiger Term in der Entscheidungsfunktion. Auf 0.0 gesetzt, wenn
fit_intercept = False.- n_iter_None oder ndarray der Form (n_targets,)
Tatsächliche Anzahl von Iterationen für jedes Ziel. Nur für ‚sag‘ und ‚lsqr‘-Löser verfügbar. Andere Löser geben None zurück.
Hinzugefügt in Version 0.17.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- solver_str
Der Löser, der während der Anpassung von den rechnerischen Routinen verwendet wurde.
Hinzugefügt in Version 1.5.
Siehe auch
RidgeClassifierRidge-Klassifikator.
RidgeCVRidge-Regression mit integrierter Kreuzvalidierung.
KernelRidgeKernel-Ridge-Regression kombiniert Ridge-Regression mit dem Kernel-Trick.
Anmerkungen
Regularisierung verbessert die Konditionierung des Problems und reduziert die Varianz der Schätzungen. Größere Werte bedeuten stärkere Regularisierung. Alpha entspricht
1 / (2C)in anderen linearen Modellen wieLogisticRegressionoderLinearSVC.Beispiele
>>> from sklearn.linear_model import Ridge >>> import numpy as np >>> n_samples, n_features = 10, 5 >>> rng = np.random.RandomState(0) >>> y = rng.randn(n_samples) >>> X = rng.randn(n_samples, n_features) >>> clf = Ridge(alpha=1.0) >>> clf.fit(X, y) Ridge()
- fit(X, y, sample_weight=None)[Quelle]#
Ridge-Regressionsmodell anpassen.
- Parameter:
- X{ndarray, sparse matrix} der Form (n_samples, n_features)
Trainingsdaten.
- yndarray der Form (n_samples,) oder (n_samples, n_targets)
Zielwerte.
- sample_weightfloat oder ndarray der Form (n_samples,), default=None
Einzelne Gewichte für jede Stichprobe. Wenn eine Gleitkommazahl angegeben wird, hat jede Stichprobe das gleiche Gewicht.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersage mit dem linearen Modell.
- Parameter:
- Xarray-like oder sparse matrix, Form (n_samples, n_features)
Stichproben.
- Gibt zurück:
- Carray, Form (n_samples,)
Gibt vorhergesagte Werte zurück.
- score(X, y, sample_weight=None)[Quelle]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmtheitskoeffizient \(R^2\) ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen ist
((y_true - y_pred)** 2).sum()und \(v\) die Gesamtsumme der Quadrate ist((y_true - y_true.mean()) ** 2).sum(). Der bestmögliche Score ist 1.0 und kann negativ sein (da das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den Erwartungswert vonyvorhersagt, unabhängig von den Eingabemerkmalen, würde einen \(R^2\)-Score von 0.0 erzielen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der beim Aufruf von
scorefür einen Regressor verwendet wird, verwendetmultioutput='uniform_average'ab Version 0.23, um konsistent mit dem Standardwert vonr2_scorezu sein. Dies beeinflusst diescore-Methode aller Multioutput-Regressoren (mit Ausnahme vonMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Ridge[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Ridge[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

Kompression Sensing: Tomographie-Rekonstruktion mit L1-Prior (Lasso)
Vergleich von Kernel Ridge und Gauß-Prozess-Regression
Fehlende Werte mit Varianten von IterativeImputer imputieren
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle
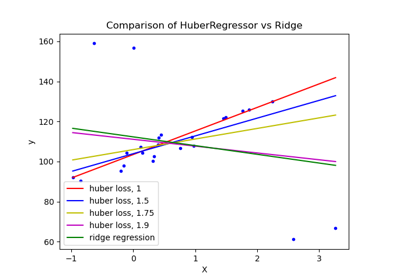
HuberRegressor vs Ridge auf Datensatz mit starken Ausreißern
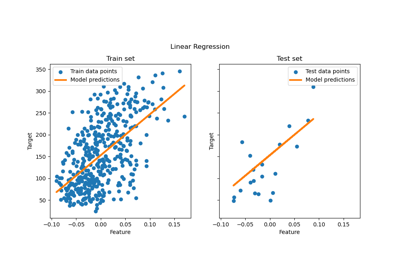
Gewöhnliche kleinste Quadrate und Ridge Regression

Poisson-Regression und nicht-normale Verlustfunktion
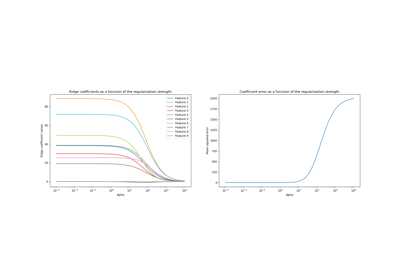
Ridge-Koeffizienten als Funktion der L2-Regularisierung
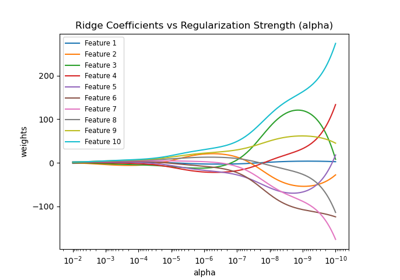
Ridge-Koeffizienten als Funktion der Regularisierung plotten
