GradientBoostingClassifier#
- class sklearn.ensemble.GradientBoostingClassifier(*, loss='log_loss', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)[source]#
Gradient Boosting für Klassifikation.
Dieser Algorithmus baut ein additives Modell in einer vorwärts schrittweisen Weise auf; er ermöglicht die Optimierung beliebiger differenzierbarer Verlustfunktionen. In jedem Schritt werden
n_classes_Regressionsbäume auf den negativen Gradienten der Verlustfunktion, z. B. binären oder multiklassen Log-Loss, trainiert. Binäre Klassifikation ist ein Sonderfall, bei dem nur ein einziger Regressionsbaum induziert wird.HistGradientBoostingClassifierist eine wesentlich schnellere Variante dieses Algorithmus für mittelgroße und große Datensätze (n_samples >= 10_000) und unterstützt monotone Einschränkungen.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- loss{‘log_loss’, ‘exponential’}, Standard=’log_loss’
Die zu optimierende Verlustfunktion. ‘log_loss’ bezieht sich auf die binomale und multinomale Abweichung, die gleiche wie bei der logistischen Regression. Sie ist eine gute Wahl für die Klassifikation mit Wahrscheinlichkeitsausgaben. Bei Verlust ‘exponential’ stellt Gradient Boosting den AdaBoost-Algorithmus wieder her.
- learning_ratefloat, Standard=0.1
Die Lernrate verringert den Beitrag jedes Baumes um
learning_rate. Es gibt einen Kompromiss zwischen learning_rate und n_estimators. Werte müssen im Bereich[0.0, inf)liegen.Für ein Beispiel der Auswirkungen dieses Parameters und seiner Interaktion mit
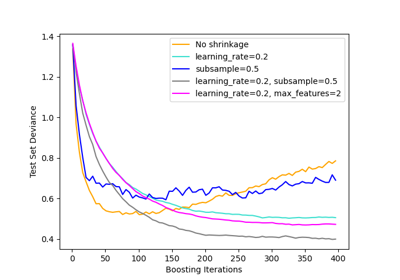
subsamplesiehe Gradient Boosting Regularisierung.- n_estimatorsint, Standard=100
Die Anzahl der durchzuführenden Boosting-Schritte. Gradient Boosting ist ziemlich robust gegenüber Überanpassung, daher führt eine große Anzahl normalerweise zu besseren Ergebnissen. Werte müssen im Bereich
[1, inf)liegen.- subsamplefloat, Standard=1.0
Der Bruchteil der Stichproben, die für das Training der einzelnen Basislerner verwendet werden. Wenn kleiner als 1,0, führt dies zu Stochastischem Gradient Boosting.
subsampleinteragiert mit dem Parametern_estimators. Die Wahl vonsubsample < 1.0führt zu einer Reduzierung der Varianz und einer Erhöhung des Bias. Werte müssen im Bereich(0.0, 1.0]liegen.- criterion{‘friedman_mse’, ‘squared_error’}, Standard=’friedman_mse’
Die Funktion zur Messung der Qualität einer Teilung. Unterstützte Kriterien sind ‘friedman_mse’ für den mittleren quadratischen Fehler mit Verbesserungs-Score nach Friedman, ‘squared_error’ für den mittleren quadratischen Fehler. Der Standardwert von ‘friedman_mse’ ist im Allgemeinen der beste, da er in einigen Fällen eine bessere Annäherung liefern kann.
Hinzugefügt in Version 0.18.
- min_samples_splitint oder float, Standard=2
Die minimale Anzahl von Samples, die zur Aufteilung eines internen Knotens erforderlich sind.
Wenn int, müssen Werte im Bereich
[2, inf)liegen.Wenn float, müssen Werte im Bereich
(0.0, 1.0]liegen undmin_samples_splitwirdceil(min_samples_split * n_samples)sein.
Geändert in Version 0.18: Float-Werte für Brüche hinzugefügt.
- min_samples_leafint oder float, Standard=1
Die minimale Anzahl von Samples, die an einem Blattknoten erforderlich sind. Ein Splitpunkt in beliebiger Tiefe wird nur berücksichtigt, wenn er mindestens
min_samples_leafTrainingssamples in jedem der linken und rechten Zweige hinterlässt. Dies kann insbesondere bei der Regression zur Glättung des Modells beitragen.Wenn int, müssen Werte im Bereich
[1, inf)liegen.Wenn float, müssen Werte im Bereich
(0.0, 1.0)liegen undmin_samples_leafwirdceil(min_samples_leaf * n_samples)sein.
Geändert in Version 0.18: Float-Werte für Brüche hinzugefügt.
- min_weight_fraction_leaffloat, Standard=0.0
Der minimale gewichtete Anteil der Summe der Gewichte (aller Eingabestichproben), der für einen Blattknoten erforderlich ist. Stichproben haben gleiche Gewichte, wenn sample_weight nicht angegeben ist. Werte müssen im Bereich
[0.0, 0.5]liegen.- max_depthint oder None, Standard=3
Maximale Tiefe der einzelnen Regressionsschätzer. Die maximale Tiefe begrenzt die Anzahl der Knoten im Baum. Stimmen Sie diesen Parameter für die beste Leistung ab; der beste Wert hängt von der Interaktion der Eingabevariablen ab. Wenn None, werden Knoten erweitert, bis alle Blätter rein sind oder bis alle Blätter weniger als min_samples_split Stichproben enthalten. Wenn int, müssen Werte im Bereich
[1, inf)liegen.- min_impurity_decreasefloat, Standard=0.0
Ein Knoten wird geteilt, wenn diese Teilung eine Verringerung der Verunreinigung größer oder gleich diesem Wert bewirkt. Werte müssen im Bereich
[0.0, inf)liegen.Die gewichtete Gleichung für die Verringerung der Unreinheit lautet:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
wobei
Ndie Gesamtzahl der Samples,N_tdie Anzahl der Samples im aktuellen Knoten,N_t_Ldie Anzahl der Samples im linken Kind undN_t_Rdie Anzahl der Samples im rechten Kind ist.N,N_t,N_t_RundN_t_Lbeziehen sich alle auf die gewichtete Summe, wennsample_weightübergeben wird.Hinzugefügt in Version 0.19.
- initestimator oder ‘zero’, Standard=None
Ein Schätzerobjekt, das zur Berechnung der anfänglichen Vorhersagen verwendet wird.
initmuss fit und predict_proba bereitstellen. Wenn ‘zero’, werden die anfänglichen Rohvorhersagen auf Null gesetzt. Standardmäßig wird einDummyEstimatorverwendet, der die Klassenwahrscheinlichkeiten vorhersagt.- random_stateint, RandomState-Instanz oder None, default=None
Steuert den Zufalls-Seed, der jedem Baumschätzer bei jeder Boosting-Iteration übergeben wird. Zusätzlich steuert er die zufällige Permutation der Merkmale bei jeder Teilung (siehe Hinweise für weitere Details). Er steuert auch die zufällige Teilung der Trainingsdaten, um einen Validierungssatz zu erhalten, wenn
n_iter_no_changenicht None ist. Geben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg an. Siehe Glossar.- max_features{‘sqrt’, ‘log2’}, int oder float, Standard=None
Die Anzahl der Features, die bei der Suche nach dem besten Split berücksichtigt werden.
Wenn int, müssen Werte im Bereich
[1, inf)liegen.Wenn float, müssen Werte im Bereich
(0.0, 1.0]liegen und die bei jeder Teilung berücksichtigten Merkmale sindmax(1, int(max_features * n_features_in_)).Wenn ‘sqrt’, dann
max_features=sqrt(n_features).Wenn ‘log2’, dann
max_features=log2(n_features).Wenn None, dann
max_features=n_features.
Die Wahl von
max_features < n_featuresführt zu einer Reduzierung der Varianz und einer Erhöhung des Bias.Hinweis: Die Suche nach einem Split stoppt nicht, bis mindestens eine gültige Partition der Knoten-Samples gefunden wurde, auch wenn dies die Inspektion von mehr als
max_featuresFeatures erfordert.- verboseint, default=0
Aktiviert ausführliche Ausgabe. Wenn 1, dann wird der Fortschritt und die Leistung von Zeit zu Zeit ausgegeben (je mehr Bäume, desto geringer die Frequenz). Wenn größer als 1, dann wird der Fortschritt und die Leistung für jeden Baum ausgegeben. Werte müssen im Bereich
[0, inf)liegen.- max_leaf_nodesint, Standard=None
Wächst Bäume mit
max_leaf_nodesim Best-First-Verfahren. Beste Knoten werden als relative Verringerung der Verunreinigung definiert. Werte müssen im Bereich[2, inf)liegen. WennNone, dann unbegrenzte Anzahl von Blattknoten.- warm_startbool, Standard=False
Wenn auf
Truegesetzt, wird die Lösung des vorherigen Aufrufs von fit wiederverwendet und dem Ensemble weitere Schätzer hinzugefügt, andernfalls wird die vorherige Lösung einfach gelöscht. Siehe das Glossar.- validation_fractionfloat, default=0.1
Der Anteil der Trainingsdaten, der als Validierungsdatensatz für frühzeitiges Stoppen beiseite gelegt wird. Werte müssen im Bereich
(0.0, 1.0)liegen. Wird nur verwendet, wennn_iter_no_changeauf eine Ganzzahl gesetzt ist.Hinzugefügt in Version 0.20.
- n_iter_no_changeint, Standard=None
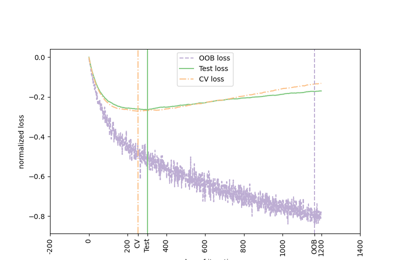
n_iter_no_changewird verwendet, um zu entscheiden, ob frühzeitiges Stoppen verwendet wird, um das Training zu beenden, wenn sich der Validierungs-Score nicht verbessert. Standardmäßig ist er auf None gesetzt, um das frühzeitige Stoppen zu deaktivieren. Wenn auf eine Zahl gesetzt, werdenvalidation_fractiondes Trainingsdatensatzes als Validierung zurückgehalten und das Training beendet, wenn sich der Validierungs-Score in keiner der vorherigenn_iter_no_changeIterationen verbessert. Die Teilung ist stratifiziert. Werte müssen im Bereich[1, inf)liegen. Siehe Frühzeitiges Stoppen in Gradient Boosting.Hinzugefügt in Version 0.20.
- tolfloat, Standard=1e-4
Toleranz für das frühzeitige Stoppen. Wenn der Verlust nicht um mindestens tol für
n_iter_no_changeIterationen (wenn auf eine Zahl gesetzt) verbessert wird, stoppt das Training. Werte müssen im Bereich[0.0, inf)liegen.Hinzugefügt in Version 0.20.
- ccp_alphanicht-negativer float, Standard=0.0
Komplexitätsparameter für die Minimale Kosten-Komplexitäts-Pruning. Der Teilbaum mit der größten Kosten-Komplexität, der kleiner als
ccp_alphaist, wird ausgewählt. Standardmäßig wird keine Pruning durchgeführt. Werte müssen im Bereich[0.0, inf)liegen. Siehe Minimale Kosten-Komplexitäts-Pruning für Details. Siehe Post pruning decision trees with cost complexity pruning für ein Beispiel einer solchen Pruning.Hinzugefügt in Version 0.22.
- Attribute:
- n_estimators_int
Die Anzahl der Schätzer, wie durch frühzeitiges Stoppen ausgewählt (wenn
n_iter_no_changeangegeben ist). Andernfalls wird sie aufn_estimatorsgesetzt.Hinzugefügt in Version 0.20.
- n_trees_per_iteration_int
Die Anzahl der Bäume, die bei jeder Iteration gebaut werden. Für binäre Klassifikatoren ist dies immer 1.
Hinzugefügt in Version 1.4.0.
feature_importances_ndarray der Form (n_features,)Die Unreinheits-basierten Wichtigkeiten der Features.
- oob_improvement_ndarray der Form (n_estimators,)
Die Verbesserung des Verlusts auf den Out-of-Bag-Stichproben im Verhältnis zur vorherigen Iteration.
oob_improvement_[0]ist die Verbesserung des Verlusts der ersten Stufe gegenüber deminit-Schätzer. Nur verfügbar, wennsubsample < 1.0.- oob_scores_ndarray der Form (n_estimators,)
Die vollständige Historie der Verlustwerte auf den Out-of-Bag-Stichproben. Nur verfügbar, wenn
subsample < 1.0.Hinzugefügt in Version 1.3.
- oob_score_float
Der letzte Wert des Verlusts auf den Out-of-Bag-Stichproben. Er ist derselbe wie
oob_scores_[-1]. Nur verfügbar, wennsubsample < 1.0.Hinzugefügt in Version 1.3.
- train_score_ndarray der Form (n_estimators,)
Der i-te Score
train_score_[i]ist der Verlust des Modells bei Iterationiauf der In-Bag-Stichprobe. Wennsubsample == 1, ist dies der Verlust auf den Trainingsdaten.- init_estimator
Der Schätzer, der die anfänglichen Vorhersagen liefert. Eingestellt über das Argument
init.- estimators_ndarray von DecisionTreeRegressor der Form (n_estimators,
n_trees_per_iteration_) Die Sammlung von trainierten Unterschätzern.
n_trees_per_iteration_ist 1 für binäre Klassifikation, ansonstenn_classes.- classes_ndarray der Form (n_classes,)
Die Klassenbezeichnungen.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_classes_int
Die Anzahl der Klassen.
- max_features_int
Der abgeleitete Wert von max_features.
Siehe auch
HistGradientBoostingClassifierHistogramm-basierter Gradient Boosting Klassifikationsbaum.
sklearn.tree.DecisionTreeClassifierEin Entscheidungsbaum-Klassifikator.
RandomForestClassifierEin Meta-Schätzer, der eine Anzahl von Entscheidungsbaumklassifikatoren auf verschiedenen Teilmengen des Datensatzes trainiert und Mittelwerte verwendet, um die Vorhersagegenauigkeit zu verbessern und Überanpassung zu kontrollieren.
AdaBoostClassifierEin Meta-Schätzer, der mit dem Trainieren eines Klassifikators auf dem ursprünglichen Datensatz beginnt und dann zusätzliche Kopien des Klassifikators auf demselben Datensatz trainiert, bei denen die Gewichte falsch klassifizierter Instanzen so angepasst werden, dass nachfolgende Klassifikatoren mehr auf schwierige Fälle fokussieren.
Anmerkungen
Die Merkmale werden bei jeder Teilung immer zufällig permutiert. Daher kann die gefundene beste Teilung variieren, selbst bei denselben Trainingsdaten und
max_features=n_features, wenn die Verbesserung des Kriteriums für mehrere Teilungen, die während der Suche nach der besten Teilung enumeriert werden, identisch ist. Um ein deterministisches Verhalten während des Trainings zu erzielen, mussrandom_statefestgelegt werden.Referenzen
J. Friedman, Greedy Function Approximation: A Gradient Boosting Machine, The Annals of Statistics, Vol. 29, No. 5, 2001.
Friedman, Stochastic Gradient Boosting, 1999
T. Hastie, R. Tibshirani und J. Friedman. Elements of Statistical Learning Ed. 2, Springer, 2009.
Beispiele
Das folgende Beispiel zeigt, wie ein Gradient Boosting-Klassifikator mit 100 Entscheidungsstümpfen als schwachen Lernern trainiert wird.
>>> from sklearn.datasets import make_hastie_10_2 >>> from sklearn.ensemble import GradientBoostingClassifier
>>> X, y = make_hastie_10_2(random_state=0) >>> X_train, X_test = X[:2000], X[2000:] >>> y_train, y_test = y[:2000], y[2000:]
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, ... max_depth=1, random_state=0).fit(X_train, y_train) >>> clf.score(X_test, y_test) 0.913
- apply(X)[source]#
Wendet Bäume im Ensemble auf X an, gibt Blattindizes zurück.
Hinzugefügt in Version 0.17.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird der dtype zu
dtype=np.float32konvertiert. Wenn eine dünnbesetzte Matrix bereitgestellt wird, wird sie in eine dünnbesetztecsr_matrixkonvertiert.
- Gibt zurück:
- X_leavesarray-like der Form (n_samples, n_estimators, n_classes)
Für jeden Datenpunkt x in X und für jeden Baum im Ensemble, gibt den Index des Blattes zurück, in dem x in jedem Schätzer landet. Im Falle einer binären Klassifikation ist n_classes 1.
- decision_function(X)[source]#
Berechnet die Entscheidungsfunktion von
X.- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt zurück:
- scorendarray der Form (n_samples, n_classes) oder (n_samples,)
Die Entscheidungsfunktion der Eingabestichproben, die den rohen Werten entspricht, die von den Bäumen des Ensembles vorhergesagt werden. Die Reihenfolge der Klassen entspricht der in dem Attribut classes_. Regression und binäre Klassifikation erzeugen ein Array der Form (n_samples,).
- fit(X, y, sample_weight=None, monitor=None)[source]#
Anpassen des Gradient Boosting-Modells.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.- yarray-like von Form (n_samples,)
Zielwerte (Strings oder Ganzzahlen bei Klassifikation, reelle Zahlen bei Regression) Für die Klassifikation müssen Labels den Klassen entsprechen.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Sample-Gewichte. Wenn None, dann werden die Samples gleich gewichtet. Splits, die Kindknoten mit Nettogewicht Null oder negativ erzeugen würden, werden bei der Suche nach einem Split in jedem Knoten ignoriert. Im Falle einer Klassifizierung werden Splits auch ignoriert, wenn sie dazu führen würden, dass eine einzelne Klasse in einem Kindknoten ein negatives Gewicht trägt.
- monitorcallable, Standard=None
Der Monitor wird nach jeder Iteration mit der aktuellen Iteration, einer Referenz auf den Schätzer und den lokalen Variablen von
_fit_stagesals Schlüsselwortargumentecallable(i, self, locals())aufgerufen. Wenn das CallableTruezurückgibt, wird der Trainingsvorgang beendet. Der Monitor kann für verschiedene Zwecke verwendet werden, wie z. B. die Berechnung von zurückgehaltenen Schätzungen, frühzeitiges Stoppen, Modellinspektion und Schnappschüsse.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[source]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[source]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[source]#
Sagt die Klasse für X voraus.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt zurück:
- yndarray der Form (n_samples,)
Die vorhergesagten Werte.
- predict_log_proba(X)[source]#
Sagt die logarithmierte Klassenwahrscheinlichkeit für X voraus.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt zurück:
- pndarray der Form (n_samples, n_classes)
Die Klassen-Log-Wahrscheinlichkeiten der Eingabestichproben. Die Reihenfolge der Klassen entspricht der in dem Attribut classes_.
- Löst aus:
- AttributeError
Wenn der
losskeine Wahrscheinlichkeiten unterstützt.
- predict_proba(X)[source]#
Sagt die Klassenwahrscheinlichkeiten für X voraus.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt zurück:
- pndarray der Form (n_samples, n_classes)
Die Klassenwahrscheinlichkeiten der Eingabesamplings. Die Reihenfolge der Klassen entspricht der im Attribut classes_.
- Löst aus:
- AttributeError
Wenn der
losskeine Wahrscheinlichkeiten unterstützt.
- score(X, y, sample_weight=None)[source]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_fit_request(*, monitor: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') GradientBoostingClassifier[source]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- monitorstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
monitorinfit.- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[source]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GradientBoostingClassifier[source]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- staged_decision_function(X)[source]#
Berechnet die Entscheidungsfunktion von
Xfür jede Iteration.Diese Methode ermöglicht die Überwachung (d.h. Bestimmung von Fehlern auf dem Testdatensatz) nach jeder Stufe.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt:
- scoreGenerator von ndarray der Form (n_samples, k)
Die Entscheidungsfunktion der Eingabestichproben, die den rohen Werten entspricht, die von den Bäumen des Ensembles vorhergesagt werden. Die Klassen entsprechen denen im Attribut classes_. Regression und binäre Klassifikation sind Sonderfälle mit
k == 1, ansonstenk==n_classes.
- staged_predict(X)[source]#
Vorhersagt Klasse in jeder Stufe für X.
Diese Methode ermöglicht die Überwachung (d.h. Bestimmung von Fehlern auf dem Testdatensatz) nach jeder Stufe.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt:
- yGenerator von ndarray der Form (n_samples,)
Der vorhergesagte Wert der Eingabestichproben.
- staged_predict_proba(X)[source]#
Vorhersagt Klassenwahrscheinlichkeiten in jeder Stufe für X.
Diese Methode ermöglicht die Überwachung (d.h. Bestimmung von Fehlern auf dem Testdatensatz) nach jeder Stufe.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.
- Gibt:
- yGenerator von ndarray der Form (n_samples,)
Der vorhergesagte Wert der Eingabestichproben.