permutation_test_score#
- sklearn.model_selection.permutation_test_score(estimator, X, y, *, groups=None, cv=None, n_permutations=100, n_jobs=None, random_state=0, verbose=0, scoring=None, params=None)[Quelle]#
Bewertet die Signifikanz eines kreuzvalidierten Scores durch Permutationen.
Permutiert Zielvariablen, um "zufällige Daten" zu generieren und den empirischen p-Wert gegen die Nullhypothese zu berechnen, dass Merkmale und Zielvariablen unabhängig sind.
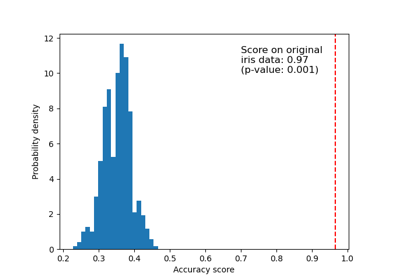
Der p-Wert stellt den Anteil der zufälligen Datensätze dar, bei denen der Schätzer so gut oder besser abgeschnitten hat als bei den Originaldaten. Ein kleiner p-Wert deutet darauf hin, dass eine echte Abhängigkeit zwischen Merkmalen und Zielvariablen besteht, die vom Schätzer genutzt wurde, um gute Vorhersagen zu liefern. Ein großer p-Wert kann auf mangelnde echte Abhängigkeit zwischen Merkmalen und Zielvariablen oder darauf zurückzuführen sein, dass der Schätzer die Abhängigkeit nicht nutzen konnte, um gute Vorhersagen zu liefern.
Mehr dazu im Benutzerhandbuch.
- Parameter:
- estimatorEstimator-Objekt, das ‘fit’ implementiert
Das zu verwendende Objekt zur Anpassung der Daten.
- Xarray-ähnlich, mindestens 2D
Die zu fittenden Daten.
- yarray-ähnlich der Form (n_samples,) oder (n_samples, n_outputs) oder None
Die Zielvariable, die im Falle von überwachtem Lernen vorhergesagt werden soll.
- groupsarray-like of shape (n_samples,), default=None
Labels zur Einschränkung der Permutation innerhalb von Gruppen, d. h. die
y-Werte werden unter Stichproben mit demselben Gruppenidentifikator permutiert. Wenn nicht angegeben, werden diey-Werte über alle Stichproben permutiert.Wenn ein gruppierter Kreuzvalidierer verwendet wird, werden die Gruppenlabels auch an die
split-Methode des Kreuzvalidierers übergeben. Der Kreuzvalidierer verwendet sie zur Gruppierung der Stichproben während der Aufteilung des Datensatzes in Trainings-/Testsets.Geändert in Version 1.6:
groupskann nur übergeben werden, wenn das Metadaten-Routing nicht übersklearn.set_config(enable_metadata_routing=True)aktiviert ist. Wenn das Routing aktiviert ist, übergeben Siegroupszusammen mit anderen Metadaten über das Argumentparams. Z. B.:permutation_test_score(..., params={'groups': groups}).- cvint, Kreuzvalidierungsgenerator oder iterierbar, Standardwert=None
Bestimmt die Strategie der Kreuzvalidierungsaufteilung. Mögliche Eingaben für cv sind
None, um die Standard-5-fach-Kreuzvalidierung zu verwenden,int, um die Anzahl der Folds in einem
(Stratified)KFoldanzugeben,Eine iterierbare Liste, die (Trainings-, Test-) Splits als Indizes-Arrays liefert.
Für
int/None-Eingaben wird, wenn der Schätzer ein Klassifikator ist undyentweder binär oder multiklasse ist,StratifiedKFoldverwendet. In allen anderen Fällen wirdKFoldverwendet. Diese Splitter werden mitshuffle=Falseinstanziiert, sodass die Splits über die Aufrufe hinweg gleich sind.Siehe Benutzerhandbuch für die verschiedenen Kreuzvalidierungsstrategien, die hier verwendet werden können.
Geändert in Version 0.22: Standardwert für
cv, wennNone, geändert von 3-fach auf 5-fach.- n_permutationsint, Standard=100
Anzahl der Permutationen von
y.- n_jobsint, default=None
Anzahl der parallel auszuführenden Jobs. Das Training des Schätzers und die Berechnung des kreuzvalidierten Scores werden über die Permutationen parallelisiert.
Nonebedeutet 1, es sei denn, es befindet sich in einemjoblib.parallel_backend-Kontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.- random_stateint, RandomState-Instanz oder None, Standard=0
Geben Sie eine Ganzzahl an, um reproduzierbare Ausgaben für die Permutation von
y-Werten zwischen Stichproben zu erhalten. Siehe Glossar.- verboseint, default=0
Die Ausführlichkeitsstufe.
- scoringstr oder callable, Standardwert=None
Bewertungsmethode, die zur Auswertung der Vorhersagen auf dem Validierungsset verwendet wird.
str: siehe Zeichenkettennamen für Bewerter für Optionen.
callable: Ein aufrufbaren Scorer-Objekt (z. B. Funktion) mit der Signatur
scorer(estimator, X, y), das nur einen einzigen Wert zurückgeben sollte. Einzelheiten siehe Aufrufbare Scorer.None: das Standard-Bewertungskriterium desestimatorwird verwendet.
- paramsdict, Standardwert=None
Parameter, die an die
fit-Methode des Schätzers, des Scorers und des CV-Splitters übergeben werden.Wenn
enable_metadata_routing=False(Standard): Parameter, die direkt an diefit-Methode des Estimators übergeben werden.Wenn
enable_metadata_routing=True: Sicher weitergeleitete Parameter an diefit-Methode des Schätzers, dascv-Objekt und denscorer. Einzelheiten siehe Metadaten-Routing-Benutzerhandbuch.
Hinzugefügt in Version 1.6.
- Gibt zurück:
- scorefloat
Der tatsächliche Score ohne Permutation der Zielvariablen.
- permutation_scoresArray der Form (n_permutations,)
Die für jede Permutation erzielten Scores.
- pvaluefloat
Der p-Wert, der die Wahrscheinlichkeit annähert, dass der Score zufällig erzielt wird. Dieser wird berechnet als
(C + 1) / (n_permutations + 1)Wobei C die Anzahl der Permutationen ist, deren Score >= dem tatsächlichen Score ist.
Der bestmögliche p-Wert ist 1/(n_permutations + 1), der schlechteste ist 1,0.
Anmerkungen
Diese Funktion implementiert Test 1 in
Ojala und Garriga. Permutation Tests for Studying Classifier Performance. The Journal of Machine Learning Research (2010) Band 11
Beispiele
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.model_selection import permutation_test_score >>> X, y = make_classification(random_state=0) >>> estimator = LogisticRegression() >>> score, permutation_scores, pvalue = permutation_test_score( ... estimator, X, y, random_state=0 ... ) >>> print(f"Original Score: {score:.3f}") Original Score: 0.810 >>> print( ... f"Permutation Scores: {permutation_scores.mean():.3f} +/- " ... f"{permutation_scores.std():.3f}" ... ) Permutation Scores: 0.505 +/- 0.057 >>> print(f"P-value: {pvalue:.3f}") P-value: 0.010
Galeriebeispiele#
Testen der Signifikanz eines Klassifikations-Scores mit Permutationen