fetch_openml#
- sklearn.datasets.fetch_openml(name: str | None = None, *, version: str | int = 'active', data_id: int | None = None, data_home: str | PathLike | None = None, target_column: str | List | None = 'default-target', cache: bool = True, return_X_y: bool = False, as_frame: str | bool = 'auto', n_retries: int = 3, delay: float = 1.0, parser: str = 'auto', read_csv_kwargs: Dict | None = None)[Quelle]#
Ruft den Datensatz von openml nach Name oder Datensatz-ID ab.
Datensätze werden eindeutig entweder durch eine Ganzzahl-ID oder durch eine Kombination aus Name und Version identifiziert (d.h. es kann mehrere Versionen des Datensatzes „iris“ geben). Bitte geben Sie entweder den Namen oder die data_id an (nicht beides). Wenn ein Name angegeben wird, kann auch eine Version angegeben werden.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.20.
Hinweis
EXPERIMENTELL
Die API ist experimentell (insbesondere die Struktur des Rückgabewerts) und kann in zukünftigen Versionen ohne Vorankündigung oder Warnung geringfügige abwärtsinkompatible Änderungen aufweisen.
- Parameter:
- namestr, Standardwert=None
Zeichenketten-Identifikator des Datensatzes. Beachten Sie, dass OpenML mehrere Datensätze mit demselben Namen haben kann.
- versionint oder ‚active‘, Standard=‚active‘
Version des Datensatzes. Kann nur angegeben werden, wenn auch
nameangegeben ist. Wenn ‚active‘ angegeben ist, wird die älteste noch aktive Version verwendet. Da es mehr als eine aktive Version eines Datensatzes geben kann und diese Versionen sich grundlegend voneinander unterscheiden können, wird dringend empfohlen, eine genaue Version festzulegen.- data_idint, Standard=None
OpenML-ID des Datensatzes. Die spezifischste Art, einen Datensatz abzurufen. Wenn data_id nicht angegeben ist, werden Name (und mögliche Version) verwendet, um einen Datensatz zu erhalten.
- data_homestr oder path-like, Standard=None
Geben Sie einen anderen Download- und Cache-Ordner für die Datensätze an. Standardmäßig werden alle scikit-learn-Daten in Unterordnern von ‚~/scikit_learn_data‘ gespeichert.
- target_columnstr, list oder None, Standard=‚default-target‘
Geben Sie den Spaltennamen in den Daten an, der als Ziel verwendet werden soll. Wenn ‚default-target‘ angegeben ist, wird die Standard-Zielspalte verwendet, die auf dem Server gespeichert ist. Wenn
Noneangegeben ist, werden alle Spalten als Daten zurückgegeben und das Ziel istNone. Wenn eine Liste (von Zeichenketten) angegeben ist, werden alle Spalten mit diesen Namen als Mehrfachziele zurückgegeben (Hinweis: Nicht alle scikit-learn-Klassifikatoren können alle Arten von Mehrfachausgabekombinationen verarbeiten).- cachebool, Standard=True
Ob die heruntergeladenen Datensätze in
data_homegecacht werden sollen.- return_X_ybool, Standard=False
Wenn True, werden
(data, target)anstelle eines Bunch-Objekts zurückgegeben. Informationen zu dendata- undtarget-Objekten finden Sie weiter unten.- as_framebool oder ‚auto‘, Standard=‚auto‘
Wenn True, sind die Daten ein pandas DataFrame, einschließlich Spalten mit geeigneten Datentypen (numerisch, Zeichenkette oder kategorisch). Das Ziel ist ein pandas DataFrame oder eine Series, abhängig von der Anzahl der target_columns. Der Bunch enthält ein Attribut
framemit dem Ziel und den Daten. Wennreturn_X_yTrue ist, sind(data, target)pandas DataFrames oder Series, wie oben beschrieben.Wenn
as_frame‚auto‘ ist, werden die Daten und das Ziel so in DataFrame oder Series konvertiert, als obas_frameauf True gesetzt wäre, es sei denn, der Datensatz ist im Sparse-Format gespeichert.Wenn
as_frameFalse ist, sind die Daten und das Ziel NumPy-Arrays, und diedataenthalten nur numerische Werte, wennparser="liac-arff"verwendet wird, wobei die Kategorien im AttributcategoriesderBunch-Instanz angegeben sind. Wennparser="pandas"verwendet wird, erfolgt keine ordinale Kodierung.Geändert in Version 0.24: Der Standardwert von
as_framewurde vonFalseauf'auto'in 0.24 geändert.- n_retriesint, Standard=3
Anzahl der Wiederholungsversuche bei HTTP-Fehlern oder Netzwerk-Timeouts. Fehler mit dem Statuscode 412 werden nicht wiederholt, da sie generische OpenML-Fehler darstellen.
- delayfloat, Standard=1.0
Anzahl der Sekunden zwischen den Wiederholungsversuchen.
- parser{„auto“, „pandas“, „liac-arff“}, Standard=„auto“
Parser, der zum Laden der ARFF-Datei verwendet wird. Zwei Parser sind implementiert
"pandas": Dies ist der effizienteste Parser. Er erfordert jedoch, dass pandas installiert ist, und kann nur dichte Datensätze öffnen."liac-arff": Dies ist ein reiner Python-ARFF-Parser, der wesentlich weniger speicher- und CPU-intensiv ist. Er verarbeitet Sparse-ARFF-Datensätze.
Wenn
"auto"angegeben ist, wird der Parser automatisch so gewählt, dass"liac-arff"für Sparse-ARFF-Datensätze ausgewählt wird, andernfalls wird"pandas"ausgewählt.Hinzugefügt in Version 1.2.
Geändert in Version 1.4: Der Standardwert von
parserändert sich von"liac-arff"zu"auto".- read_csv_kwargsdict, Standard=None
Schlüsselwortargumente, die an
pandas.read_csvübergeben werden, wenn die Daten aus einer ARFF-Datei geladen und der pandas-Parser verwendet wird. Sie können einige Standardparameter überschreiben.Hinzugefügt in Version 1.3.
- Gibt zurück:
- data
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- datanp.array, scipy.sparse.csr_matrix von Floats oder pandas DataFrame
Die Feature-Matrix. Kategorische Merkmale werden als Ordinalzahlen kodiert.
- targetnp.array, pandas Series oder DataFrame
Die Regressionsziele oder Klassifikationsbezeichnungen, falls zutreffend. Der Datentyp ist float, wenn numerisch, und object, wenn kategorisch. Wenn
as_frameTrue ist, isttargetein pandas-Objekt.- DESCRstr
Die vollständige Beschreibung des Datensatzes.
- feature_nameslist
Die Namen der Datensatzspalten.
- target_names: list
Die Namen der Zielspalten.
Hinzugefügt in Version 0.22.
- categoriesdict oder None
Ordnet jeden Namen eines kategorischen Merkmals einer Liste von Werten zu, sodass der als i kodierte Wert der i-te in der Liste ist. Wenn
as_frameTrue ist, ist dies None.- detailsdict
Weitere Metadaten von OpenML.
- framepandas DataFrame
Nur vorhanden, wenn
as_frame=True. DataFrame mitdataundtarget.
- (data, target)tuple, wenn
return_X_yTrue ist Hinweis
EXPERIMENTELL
Diese Schnittstelle ist experimentell und zukünftige Releases können Attribute ohne Vorankündigung ändern (obwohl es nur geringfügige Änderungen an
dataundtargetgeben sollte).Fehlende Werte in den ‚data‘ werden als NaN dargestellt. Fehlende Werte in ‚target‘ werden als NaN (numerisches Ziel) oder None (kategorisches Ziel) dargestellt.
- data
Anmerkungen
Die Parser
"pandas"und"liac-arff"können zu unterschiedlichen Datentypen in der Ausgabe führen. Die bemerkenswerten Unterschiede sind folgende:Der Parser
"liac-arff"kodiert kategorische Merkmale immer alsstr-Objekte. Im Gegensatz dazu leitet der Parser"pandas"beim Lesen den Typ ab und numerische Kategorien werden, wo immer möglich, in Ganzzahlen umgewandelt.Der Parser
"liac-arff"verwendet float64 zur Kodierung von numerischen Merkmalen, die in den Metadaten als ‚REAL‘ und ‚NUMERICAL‘ gekennzeichnet sind. Der Parser"pandas"leitet stattdessen ab, ob diese numerischen Merkmale Ganzzahlen entsprechen, und verwendet die Integer-Erweiterungs-Datentypen von pandas.Insbesondere werden Klassifikationsdatensätze mit Ganzzahl-Kategorien typischerweise als solche geladen
(0, 1, ...)mit dem Parser"pandas", während"liac-arff"die Verwendung von Zeichenketten-kodierten Klassenbezeichnungen wie"0","1"und so weiter erzwingt.Der Parser
"pandas"entfernt keine einfachen Anführungszeichen – d.h.'– aus Zeichenketten-Spalten. Zum Beispiel wird eine Zeichenkette'my string'beibehalten, während der Parser"liac-arff"die einfachen Anführungszeichen entfernt. Bei kategorischen Spalten werden die einfachen Anführungszeichen von den Werten entfernt.
Darüber hinaus gibt der Parser
"liac-arff"bei Verwendung vonas_frame=Falseordinal kodierte Daten zurück, bei denen die Kategorien im AttributcategoriesderBunch-Instanz angegeben sind. Stattdessen gibt"pandas"ein NumPy-Array zurück, bei dem die Kategorien nicht kodiert sind.Beispiele
>>> from sklearn.datasets import fetch_openml >>> adult = fetch_openml("adult", version=2) >>> adult.frame.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 48842 entries, 0 to 48841 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 48842 non-null int64 1 workclass 46043 non-null category 2 fnlwgt 48842 non-null int64 3 education 48842 non-null category 4 education-num 48842 non-null int64 5 marital-status 48842 non-null category 6 occupation 46033 non-null category 7 relationship 48842 non-null category 8 race 48842 non-null category 9 sex 48842 non-null category 10 capital-gain 48842 non-null int64 11 capital-loss 48842 non-null int64 12 hours-per-week 48842 non-null int64 13 native-country 47985 non-null category 14 class 48842 non-null category dtypes: category(9), int64(6) memory usage: 2.7 MB
Galeriebeispiele#

Auswirkung der Transformation der Ziele in einem Regressionsmodell

Unterstützung für kategorische Merkmale in Gradient Boosting
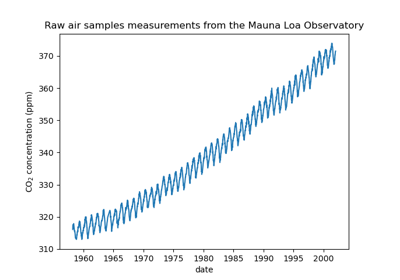
Prognose des CO2-Spiegels im Mona Loa Datensatz mittels Gauß-Prozess-Regression (GPR)
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle

Partial Dependence und Individual Conditional Expectation Plots

Permutations-Wichtigkeit vs. Random Forest Merkmals-Wichtigkeit (MDI)

Poisson-Regression und nicht-normale Verlustfunktion
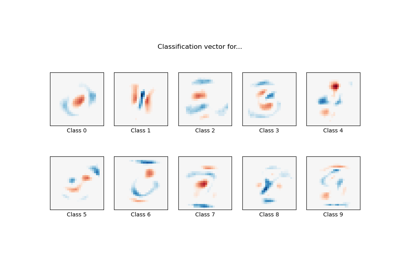
MNIST-Klassifikation mittels multinomialer Logistik + L1
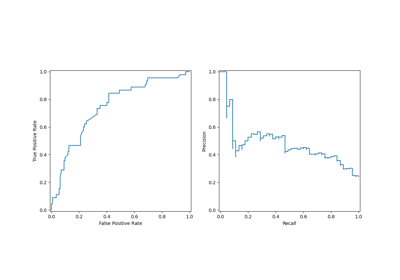

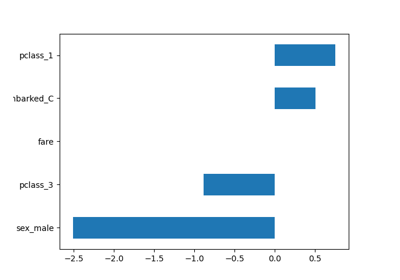
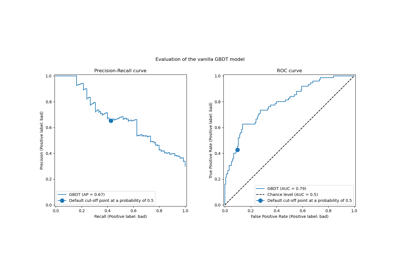
Post-Hoc-Anpassung des Entscheidungsschwellenwerts für kostenempfindliches Lernen
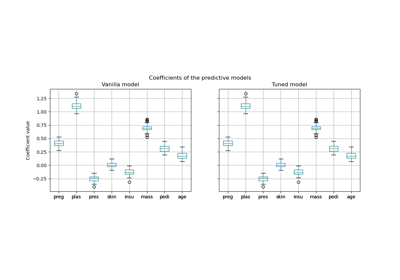
Post-hoc-Anpassung des Cut-off-Punkts der Entscheidungskfunktion
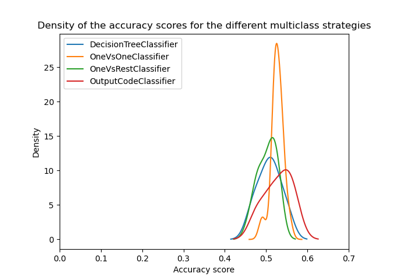
Übersicht über Multiklassen-Training Meta-Estimator
Multilabel-Klassifikation mit einem Klassifikator-Ketten