DecisionTreeRegressor#
- class sklearn.tree.DecisionTreeRegressor(*, criterion='squared_error', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, ccp_alpha=0.0, monotonic_cst=None)[Quelle]#
Ein Entscheidungsbaum-Regressor.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- criterion{“squared_error”, “friedman_mse”, “absolute_error”, “poisson”}, default=”squared_error”
Die Funktion zur Messung der Qualität eines Splits. Unterstützte Kriterien sind "squared_error" für den mittleren quadratischen Fehler, der der Reduktion der Varianz als Kriterium zur Merkmalsauswahl entspricht und den L2-Verlust minimiert, indem der Mittelwert jeder Endknotens verwendet wird, "friedman_mse", der den mittleren quadratischen Fehler mit dem Friedman-Verbesserungs-Score für potenzielle Splits verwendet, "absolute_error" für den mittleren absoluten Fehler, der den L1-Verlust minimiert, indem der Median jedes Endknotens verwendet wird, und "poisson", der die Reduktion der halben mittleren Poisson-Devianz zur Ermittlung von Splits verwendet.
Hinzugefügt in Version 0.18: Kriterium für den mittleren absoluten Fehler (MAE).
Hinzugefügt in Version 0.24: Kriterium für die Poisson-Devianz.
- splitter{“best”, “random”}, default=”best”
Die Strategie, die zum Choisen des Splits an jedem Knoten verwendet wird. Unterstützte Strategien sind "best" zum Choisen des besten Splits und "random" zum Choisen des besten zufälligen Splits.
- max_depthint, Standard=None
Die maximale Tiefe des Baumes. Wenn None, dann werden Knoten erweitert, bis alle Blätter rein sind oder bis alle Blätter weniger als min_samples_split Samples enthalten.
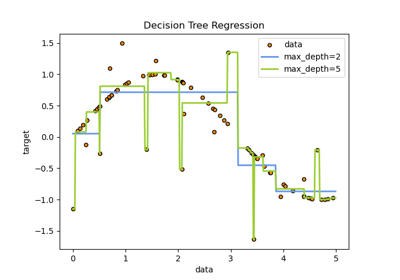
Ein Beispiel dafür, wie
max_depthdas Modell beeinflusst, finden Sie unter Entscheidungsbaum-Regression.- min_samples_splitint oder float, Standard=2
Die minimale Anzahl von Samples, die zur Aufteilung eines internen Knotens erforderlich sind.
Wenn int, dann betrachte
min_samples_splitals die minimale Anzahl.Wenn float, dann ist
min_samples_splitein Bruchteil undceil(min_samples_split * n_samples)ist die minimale Anzahl von Samples für jeden Split.
Geändert in Version 0.18: Float-Werte für Brüche hinzugefügt.
- min_samples_leafint oder float, Standard=1
Die minimale Anzahl von Samples, die an einem Blattknoten erforderlich sind. Ein Splitpunkt in beliebiger Tiefe wird nur berücksichtigt, wenn er mindestens
min_samples_leafTrainingssamples in jedem der linken und rechten Zweige hinterlässt. Dies kann insbesondere bei der Regression zur Glättung des Modells beitragen.Wenn int, dann betrachte
min_samples_leafals die minimale Anzahl.Wenn float, dann ist
min_samples_leafein Bruchteil undceil(min_samples_leaf * n_samples)ist die minimale Anzahl von Samples für jeden Knoten.
Geändert in Version 0.18: Float-Werte für Brüche hinzugefügt.
- min_weight_fraction_leaffloat, Standard=0.0
Der minimale gewichtete Bruchteil der Summe aller Gewichte (aller Eingabesamplings), der in einem Blattknoten erforderlich ist. Samples haben gleiche Gewichte, wenn sample_weight nicht angegeben ist.
- max_featuresint, float or {“sqrt”, “log2”}, default=None
Die Anzahl der Features, die bei der Suche nach dem besten Split berücksichtigt werden.
Wenn int, dann werden
max_featuresFeatures bei jedem Split berücksichtigt.Wenn float, dann ist
max_featuresein Bruchteil undmax(1, int(max_features * n_features_in_))Features werden bei jedem Split berücksichtigt.Wenn "sqrt", dann
max_features=sqrt(n_features).Wenn "log2", dann
max_features=log2(n_features).Wenn None, dann
max_features=n_features.
Hinweis: Die Suche nach einem Split stoppt nicht, bis mindestens eine gültige Partition der Knoten-Samples gefunden wurde, auch wenn dies die Inspektion von mehr als
max_featuresFeatures erfordert.- random_stateint, RandomState-Instanz oder None, default=None
Steuert die Zufälligkeit des Estimators. Die Merkmale werden bei jedem Split immer zufällig permutiert, auch wenn
splitterauf"best"gesetzt ist. Wennmax_features < n_featuresist, wählt der Algorithmus bei jedem Splitmax_featureszufällig aus, bevor der beste Split unter ihnen ermittelt wird. Der gefundene beste Split kann jedoch bei verschiedenen Durchläufen variieren, selbst wennmax_features=n_featuresist. Dies ist der Fall, wenn die Verbesserung des Kriteriums für mehrere Splits identisch ist und ein Split zufällig ausgewählt werden muss. Um ein deterministisches Verhalten während des Trainings zu erzielen, mussrandom_stateauf eine Ganzzahl gesetzt werden. Siehe Glossar für Details.- max_leaf_nodesint, Standard=None
Erzeugt einen Baum mit
max_leaf_nodesim Best-First-Verfahren. Beste Knoten werden als relative Verringerung der Unreinheit definiert. Wenn None, dann unbegrenzte Anzahl von Blattknoten.- min_impurity_decreasefloat, Standard=0.0
Ein Knoten wird geteilt, wenn dieser Split eine Verringerung der Unreinheit von mindestens diesem Wert bewirkt.
Die gewichtete Gleichung für die Verringerung der Unreinheit lautet:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
wobei
Ndie Gesamtzahl der Samples,N_tdie Anzahl der Samples im aktuellen Knoten,N_t_Ldie Anzahl der Samples im linken Kind undN_t_Rdie Anzahl der Samples im rechten Kind ist.N,N_t,N_t_RundN_t_Lbeziehen sich alle auf die gewichtete Summe, wennsample_weightübergeben wird.Hinzugefügt in Version 0.19.
- ccp_alphanicht-negativer float, Standard=0.0
Komplexitätsparameter, der für das prudenbasierte "Minimal Cost-Complexity Pruning" verwendet wird. Es wird der Teilbaum mit der größten Kostenkomplexität gewählt, der kleiner als
ccp_alphaist. Standardmäßig erfolgt kein Pruning. Siehe Pruning nach Kostenkomplexität für Details. Siehe Entscheidungsbäume durch Kostenkomplexitäts-Pruning nachbearbeiten für ein Beispiel eines solchen Prunings.Hinzugefügt in Version 0.22.
- monotonic_cstarray-like von int der Form (n_features,), Standard=None
- Gibt die zu erzwingende Monotonie-Beschränkung für jedes Merkmal an.
1: monoton steigend
0: keine Beschränkung
-1: monoton fallend
Wenn monotonic_cst None ist, werden keine Beschränkungen angewendet.
- Monotonie-Beschränkungen werden nicht unterstützt für
Multi-Output-Regressionen (d.h. wenn
n_outputs_ > 1),Regressionen, die auf Daten mit fehlenden Werten trainiert wurden.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 1.4.
- Attribute:
feature_importances_ndarray der Form (n_features,)Gibt die Merkmalswichtigkeit zurück.
- max_features_int
Der abgeleitete Wert von max_features.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_outputs_int
Die Anzahl der Ausgaben, wenn
fitausgeführt wird.- tree_Tree-Instanz
Das zugrunde liegende Tree-Objekt. Bitte beziehen Sie sich auf
help(sklearn.tree._tree.Tree)für Attribute des Tree-Objekts und Die Struktur des Entscheidungsbaums verstehen für grundlegende Verwendung dieser Attribute.
Siehe auch
DecisionTreeClassifierEin Entscheidungsbaum-Klassifikator.
Anmerkungen
Die Standardwerte für die Parameter, die die Größe der Bäume steuern (z. B.
max_depth,min_samples_leafusw.), führen zu vollständig gewachsenen und un-geprunten Bäumen, die auf einigen Datensätzen potenziell sehr groß sein können. Um den Speicherverbrauch zu reduzieren, sollte die Komplexität und Größe der Bäume durch Setzen dieser Parameterwerte gesteuert werden.Referenzen
[2]L. Breiman, J. Friedman, R. Olshen, and C. Stone, “Classification and Regression Trees”, Wadsworth, Belmont, CA, 1984.
[3]T. Hastie, R. Tibshirani and J. Friedman. “Elements of Statistical Learning”, Springer, 2009.
[4]L. Breiman, and A. Cutler, “Random Forests”, https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
Beispiele
>>> from sklearn.datasets import load_diabetes >>> from sklearn.model_selection import cross_val_score >>> from sklearn.tree import DecisionTreeRegressor >>> X, y = load_diabetes(return_X_y=True) >>> regressor = DecisionTreeRegressor(random_state=0) >>> cross_val_score(regressor, X, y, cv=10) ... ... array([-0.39, -0.46, 0.02, 0.06, -0.50, 0.16, 0.11, -0.73, -0.30, -0.00])
- apply(X, check_input=True)[Quelle]#
Gibt den Index des Blattes zurück, als das jeder Stichprobe vorhergesagt wird.
Hinzugefügt in Version 0.17.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.- check_inputbool, Standardwert=True
Ermöglicht das Umgehen mehrerer Eingabeüberprüfungen. Verwenden Sie diesen Parameter nicht, es sei denn, Sie wissen, was Sie tun.
- Gibt zurück:
- X_leavesarray-like von Form (n_samples,)
Gibt für jeden Datenpunkt x in X den Index des Blattes zurück, in dem x landet. Blätter sind innerhalb von
[0; self.tree_.node_count)nummeriert, möglicherweise mit Lücken in der Nummerierung.
- cost_complexity_pruning_path(X, y, sample_weight=None)[Quelle]#
Berechnet den Beschneidungspfad während des minimalen Kosten-Komplexitäts-Beschneidens.
Siehe Minimales Kosten-Komplexitäts-Beschneiden für Details zum Beschneidungsprozess.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Trainings-Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csc_matrix.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Die Zielwerte (Klassenbezeichnungen) als ganze Zahlen oder Zeichenketten.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte. Wenn None, dann werden die Stichproben gleich gewichtet. Splits, die Kindknoten mit Nettogewicht Null oder negativ erzeugen würden, werden bei der Suche nach einem Split in jedem Knoten ignoriert. Splits werden auch ignoriert, wenn sie dazu führen würden, dass eine einzelne Klasse in einem Kindknoten ein negatives Gewicht trägt.
- Gibt zurück:
- ccp_path
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- ccp_alphasndarray
Effektive Alphas des Teilbaums während des Beschneidens.
- impuritiesndarray
Summe der Unreinheiten der Blattknoten des Teilbaums für den entsprechenden Alpha-Wert in
ccp_alphas.
- ccp_path
- decision_path(X, check_input=True)[Quelle]#
Gibt den Entscheidungspfad im Baum zurück.
Hinzugefügt in Version 0.18.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.- check_inputbool, Standardwert=True
Ermöglicht das Umgehen mehrerer Eingabeüberprüfungen. Verwenden Sie diesen Parameter nicht, es sei denn, Sie wissen, was Sie tun.
- Gibt zurück:
- indicatordünn besetzte Matrix der Form (n_samples, n_nodes)
Gibt eine CSR-Matrix mit Knotenindikatoren zurück, wobei Nicht-Null-Elemente anzeigen, dass die Stichproben die Knoten durchlaufen.
- fit(X, y, sample_weight=None, check_input=True)[Quelle]#
Erstellt einen Entscheidungsbaum-Regressor aus dem Trainingsdatensatz (X, y).
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Trainings-Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csc_matrix.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Die Zielwerte (reelle Zahlen). Verwenden Sie
dtype=np.float64undorder='C'für maximale Effizienz.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte. Wenn None, dann werden die Stichproben gleich gewichtet. Splits, die Kindknoten mit Nettogewicht Null oder negativ erzeugen würden, werden bei der Suche nach einem Split in jedem Knoten ignoriert.
- check_inputbool, Standardwert=True
Ermöglicht das Umgehen mehrerer Eingabeüberprüfungen. Verwenden Sie diesen Parameter nicht, es sei denn, Sie wissen, was Sie tun.
- Gibt zurück:
- selfDecisionTreeRegressor
Angepasster Schätzer.
- get_depth()[Quelle]#
Gibt die Tiefe des Entscheidungsbaums zurück.
Die Tiefe eines Baumes ist der maximale Abstand zwischen der Wurzel und jedem Blatt.
- Gibt zurück:
- self.tree_.max_depthint
Die maximale Tiefe des Baumes.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_n_leaves()[Quelle]#
Gibt die Anzahl der Blätter des Entscheidungsbaums zurück.
- Gibt zurück:
- self.tree_.n_leavesint
Anzahl der Blätter.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X, check_input=True)[Quelle]#
Sagt die Klasse oder den Regressionswert für X voraus.
Für ein Klassifikationsmodell wird die vorhergesagte Klasse für jede Stichprobe in X zurückgegeben. Für ein Regressionsmodell wird der vorhergesagte Wert basierend auf X zurückgegeben.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben. Intern wird sie in
dtype=np.float32konvertiert und, wenn eine Sparse-Matrix bereitgestellt wird, in eine Sparse-csr_matrix.- check_inputbool, Standardwert=True
Ermöglicht das Umgehen mehrerer Eingabeüberprüfungen. Verwenden Sie diesen Parameter nicht, es sei denn, Sie wissen, was Sie tun.
- Gibt zurück:
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Die vorhergesagten Klassen oder die vorhergesagten Werte.
- score(X, y, sample_weight=None)[Quelle]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmtheitskoeffizient, \(R^2\), ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen ist
((y_true - y_pred)** 2).sum()und \(v\) die Summe der Gesamtquadrate ist((y_true - y_true.mean()) ** 2).sum(). Der beste mögliche Score ist 1,0 und er kann negativ sein (da das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den Erwartungswert vonyvorhersagt, unabhängig von den Eingabemerkmalen, würde einen \(R^2\)-Score von 0,0 erzielen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der bei der Verwendung von
scoreauf einem Regressor verwendet wird, nutztmultioutput='uniform_average'ab Version 0.23, um konsistent mit dem Standardwert vonr2_scorezu bleiben. Dies beeinflusst diescore-Methode aller Multi-Output-Regressoren (mit Ausnahme vonMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DecisionTreeRegressor[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DecisionTreeRegressor[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
Einzelner Estimator versus Bagging: Bias-Varianz-Zerlegung


Verwendung von KBinsDiscretizer zur Diskretisierung kontinuierlicher Merkmale